Author: Denis Avetisyan
A new foundation model allows robots to predict and interact with their environment by learning from vast datasets of human activity.
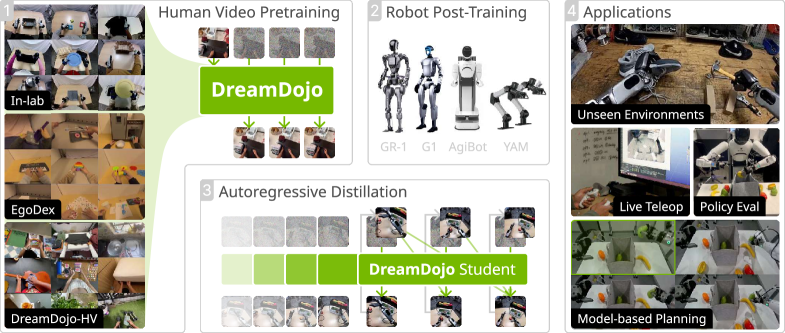
DreamDojo leverages large-scale human video data and continuous latent actions to create a generalist world model for long-horizon robotic control and realistic simulation.
Simulating complex, real-world interactions remains a key bottleneck in developing truly generalist robotic agents. To address this, we introduce DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos, a foundation model pre-trained on 44,000 hours of egocentric human activity, and employing continuous latent actions to bridge the gap between visual observation and dexterous control. This approach yields a world model capable of realistic, long-horizon prediction and precise action controllability after limited fine-tuning on target robot data. Will this large-scale pre-training paradigm unlock a new era of adaptable, open-world robotic systems capable of seamlessly navigating complex environments?
Beyond Reactive Control: The Seeds of Prediction
Historically, robotic systems have largely operated on principles of reactive control, responding directly to sensory input without anticipating future consequences. While sufficient for simple, static environments, this approach falters when confronted with complexity and dynamism. Consider a robot navigating a crowded room; purely reactive control necessitates constant adjustments based on immediate obstacles, leading to jerky movements and potential collisions. This is because the robot lacks an internal representation of the world that allows it to foresee how its actions will unfold and proactively adjust its trajectory. Consequently, traditional robotics struggles with scenarios requiring planning, adaptation, and the ability to handle unforeseen circumstances-environments where anticipating change, rather than merely reacting to it, is paramount for successful operation.
Robust robotic systems operating in unpredictable environments necessitate a departure from purely reactive control strategies; instead, the capacity to anticipate future states becomes paramount. This predictive ability isn’t about clairvoyance, but rather the construction of internal world models – sophisticated representations of the environment that allow a robot to simulate potential outcomes of its actions. By effectively “thinking ahead,” a robot can plan more efficiently, avoid collisions, and adapt to changing circumstances with greater resilience. Such models move beyond simply responding to immediate stimuli, enabling proactive behavior and unlocking the potential for truly autonomous operation in complex, dynamic settings. The development of these predictive frameworks represents a critical step towards building robots capable of navigating and interacting with the world in a truly intelligent manner.
Contemporary robotic systems, despite advancements in sensing and actuation, frequently falter when confronted with even slightly unpredictable situations due to limitations in their ability to anticipate future consequences. Existing world models often struggle to accurately simulate interactions extending beyond the immediate next step, hindering performance in tasks requiring strategic planning or long-term adaptation. This shortfall stems from a reliance on datasets constrained by specific environments or activities, resulting in models that exhibit poor generalization to novel scenarios. Consequently, a robot trained in a controlled laboratory setting may fail to effectively navigate a cluttered home or interact with unfamiliar objects, highlighting the critical need for robust models capable of predicting outcomes across a wider spectrum of possibilities and extending their predictive capabilities to encompass extended temporal horizons.
DreamDojo: Simulating Reality, Expanding Intelligence
DreamDojo employs a latent video diffusion model to address limitations inherent in traditional world modeling techniques. Unlike methods relying on discrete state representations or limited observation horizons, diffusion models operate directly in a continuous latent space, enabling the generation of diverse and realistic future states. This approach allows DreamDojo to predict and simulate complex physical interactions with greater fidelity and robustness. By learning the underlying distribution of video data in this latent space, the model can effectively extrapolate beyond observed scenarios and generalize to novel situations, significantly enhancing its ability to anticipate and react to dynamic environments. The latent space representation also facilitates efficient training and reduces computational demands compared to operating directly on pixel data.
DreamDojo employs continuous latent actions as a core mechanism for controlling and simulating robot behavior. Unlike discrete action spaces which limit movement to predefined steps, continuous latent actions represent control signals within a high-dimensional, continuous vector space. This allows for nuanced and fluid movements, and crucially, provides a unified representation for both training the model and conditioning its outputs. The model learns to map observations to these continuous latent actions, and then decodes these actions into realistic robot movements. This unified representation streamlines the learning process and improves generalization to novel situations, as the model doesn’t need to relearn different action mappings for different tasks or environments.
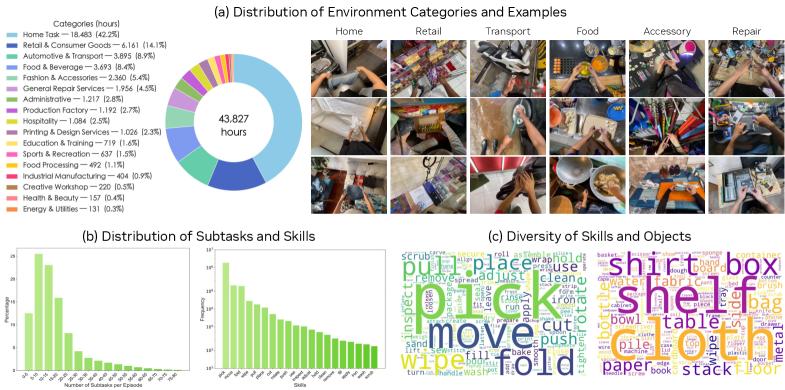
DreamDojo’s training regimen utilizes the DreamDojo-HV dataset, comprising 44,000 hours of human video footage. This extensive dataset serves as the primary source for the model’s understanding of both physical dynamics and a diverse range of human activities. The scale of DreamDojo-HV represents a significant advancement in robot learning datasets, exceeding previously available resources and enabling the model to generalize across a wider spectrum of scenarios. The sheer volume of data allows for the capture of subtle nuances in movement and interaction, contributing to the model’s ability to perform complex tasks and adapt to novel situations.

Cosmos-Predict2.5: Efficiency Through Latent Space Compression
DreamDojo utilizes Cosmos-Predict2.5 as its foundational video prediction model, which is a latent video diffusion model specifically engineered for computational efficiency. Cosmos-Predict2.5 operates within a latent space, processing video data in a compressed representation to reduce processing demands. This approach allows for faster prediction speeds and lower memory requirements compared to models operating directly on pixel data. The model’s architecture is designed to generate future frames given a sequence of past frames, leveraging the principles of diffusion models to iteratively refine the predicted output and achieve high-quality results with optimized performance.
The WAN2.2 Tokenizer is a vector quantization method employed to map raw video frames into a discrete latent space. This process involves training a codebook of vector embeddings; each frame is then represented by the index of its nearest embedding in the codebook. Utilizing a learned codebook with 16,384 entries, WAN2.2 facilitates the creation of a continuous latent space, minimizing information loss during the vector quantization process. This continuity is crucial for the diffusion model, allowing for effective denoising and reconstruction of plausible future frames during video prediction. The resulting latent representation significantly reduces computational demands compared to operating directly on pixel data, enabling efficient processing of video sequences.
The training process for Cosmos-Predict2.5 utilizes the Flow Matching Loss function, a technique designed to refine the model’s predictive capabilities by directly comparing predicted and actual motion vectors. This loss function calculates the discrepancy between the predicted velocity field – representing the anticipated movement of pixels between frames – and the ground-truth velocity field derived from observed video sequences. Minimizing this discrepancy forces the model to generate predictions that accurately reflect the dynamics of the input video, resulting in enhanced prediction accuracy and smoother, more realistic motion in the generated frames. The Flow Matching Loss effectively guides the model’s learning process, optimizing its ability to extrapolate future frames based on observed motion patterns.
Chunked Action Injection is a performance optimization technique employed within Cosmos-Predict2.5 that enhances video prediction accuracy and speed. This method involves segmenting actions within a video into discrete chunks and providing the model with focused information pertaining to these specific actions. By concentrating on relevant action data, the model reduces computational load and improves the efficiency of its predictions, ultimately achieving real-time performance of 10.81 frames per second at a resolution of 640×480 pixels. This targeted approach allows for more precise and faster predictions compared to processing the entire video sequence at once.
Stabilizing the Simulation: Coherence Across Time
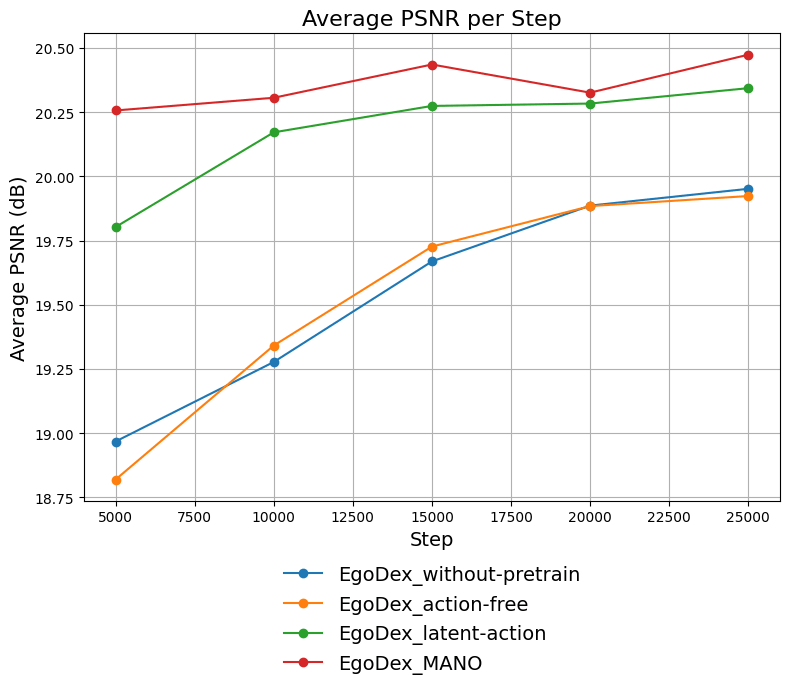
Temporal Consistency Loss functions by minimizing the difference between features extracted from adjacent predicted frames. This is achieved by applying a loss function – typically Mean Squared Error (MSE) or a perceptual loss based on feature activations from a pre-trained network – to the feature representations of consecutive frames. By penalizing large discrepancies in these features, the model is encouraged to generate videos where the predicted state transitions are smooth and physically plausible, reducing flickering or jarring movements. The implementation often involves calculating the loss on feature maps extracted from intermediate layers of a convolutional neural network, providing a more robust measure of similarity than pixel-wise comparisons and improving the visual coherence of long-horizon predictions.
Self forcing is a distillation technique applied to autoregressive prediction models to improve long-horizon stability. During training, the model is forced to predict future states not only based on ground truth data but also based on its own previously predicted states. This process effectively creates a “teacher-student” loop where the model learns to correct its own errors, mitigating the compounding of inaccuracies that typically occur during extended predictions. By training the model to be robust to its own imperfections, self forcing reduces error accumulation and enhances the overall coherence of predicted sequences over longer time horizons, leading to more stable and realistic outputs.
Relative actions represent a simplification of the action space by defining actions as changes in joint angles rather than absolute target positions. This approach reduces the dimensionality of the action space, thereby decreasing computational complexity during both training and inference. By focusing on incremental changes, the model generalizes more effectively to novel situations and unseen environments, as it learns to adapt to existing states rather than memorizing specific trajectories. The use of relative actions mitigates the challenges associated with predicting absolute joint configurations, particularly over extended prediction horizons, and improves the robustness of the system to variations in initial conditions and task parameters.
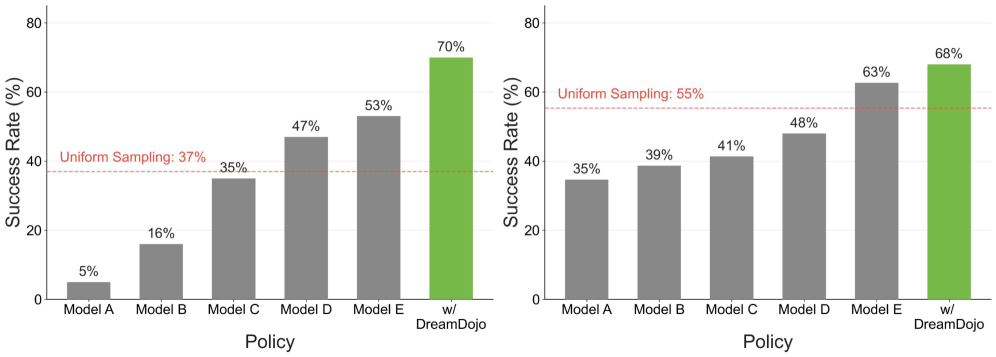
Model validation was conducted using the EgoDex dataset, which focuses on in-hand manipulation, and a dedicated in-lab dataset designed for dexterous manipulation tasks. Quantitative results demonstrated the model’s capacity to accurately simulate complex manipulation sequences. Critically, human evaluations performed on previously unseen scenarios indicated high preference rates for the model’s predicted actions, signifying a strong correlation between simulated and preferred human behavior. These preference rates provide a key metric for assessing the realism and plausibility of the model’s long-horizon predictions in a practical context.
Towards Generalizable Robotic Intelligence: Beyond Mimicry
DreamDojo showcases a remarkable capacity for action controllability, meaning it can reliably forecast the consequences of specific actions within a simulated environment. This isn’t simply pattern recognition; the model demonstrates an understanding of how actions propagate through a system, allowing it to predict not just the immediate result, but also the cascading effects that follow. Researchers validated this capability through complex manipulation tasks, observing that DreamDojo accurately anticipated the outcome of movements with a high degree of precision, even when those movements involved interacting with numerous objects simultaneously. This precise predictive ability is foundational for robust robotic planning, enabling robots to ‘think through’ actions before executing them and avoid potentially costly errors or unintended consequences – a critical step towards truly autonomous operation.
DreamDojo showcases a remarkable capacity for physics understanding, allowing it to accurately predict how objects will behave when interacting with the world. This isn’t simply rote memorization; the model constructs an internal representation of physical principles – gravity, friction, momentum – and applies them to simulate realistic interactions. Through extensive training, it learns to anticipate the consequences of actions, like predicting the trajectory of a thrown object or the stability of a stacked tower. This capability extends beyond the training data, allowing DreamDojo to generalize its understanding to novel scenarios and physical properties, effectively functioning as a predictive physics engine embedded within a robotic control system. The ability to simulate these interactions is fundamental to enabling robots to plan and execute complex tasks in unpredictable environments, marking a significant advancement towards more adaptable and intelligent machines.
The core innovation of DreamDojo lies in its capacity to construct a generalized world model – a sophisticated internal representation of how environments behave – which dramatically reduces the need for extensive retraining when robots encounter novel situations. Unlike traditional robotic systems heavily reliant on task-specific datasets, DreamDojo learns underlying physical principles and dynamics, enabling it to predict outcomes and plan actions across a wide range of scenarios. This ability to extrapolate knowledge allows robots to adapt quickly to unfamiliar environments, manipulate new objects, and execute previously unseen tasks with remarkable efficiency. Consequently, the development of such generalizable models represents a significant departure from the limitations of current robotic intelligence, promising a future where robots exhibit greater autonomy, flexibility, and resilience in dynamic, real-world settings.
The development of DreamDojo signifies a pivotal advancement in the pursuit of genuinely intelligent and autonomous robotic systems. Historically, robots have struggled with adaptability, often requiring extensive reprogramming for even minor environmental changes or novel tasks. This research transcends that limitation by establishing a foundation for robots capable of learning a generalized understanding of the physical world, allowing them to anticipate the consequences of actions and effectively plan for unforeseen circumstances. By demonstrating robust action controllability and a nuanced grasp of physics, DreamDojo moves beyond pre-programmed responses, enabling robots to reason about their surroundings and interact with them in a flexible and resourceful manner – a crucial step towards creating machines that can operate independently and solve complex problems in real-world settings.

The pursuit within DreamDojo-building a generalized world model from the chaos of human action-mirrors a fundamental drive to deconstruct and understand complex systems. It’s a process akin to reverse-engineering reality itself, identifying the underlying principles governing behavior. As John von Neumann observed, “The sciences do not try to explain why we exist, but how we exist.” This pursuit isn’t about replicating the human experience, but about distilling it into a framework for prediction and control – a computational lens through which long-horizon planning becomes not merely possible, but predictable, even in the face of the inherently messy data from which it’s derived. The distillation process within DreamDojo exemplifies this-reducing complex video data into continuous latent actions, revealing the core mechanics of interaction.
What’s Next?
DreamDojo, in its ambition to distill reality into a trainable simulation, predictably exposes the chasm between seeing and understanding. The model generates plausible futures, certainly – but plausibility isn’t truth. The real test lies not in mimicking human actions, but in anticipating the unexpected consequences of those actions within a complex system. The current focus on video data, while pragmatic, begs the question: how much of ‘world knowledge’ remains stubbornly locked outside the visual spectrum? Tactile feedback, material properties, even the subtle cues of weight and balance – these aren’t merely details to be added, but fundamental constraints on any predictive model.
The claim of ‘generalist’ capability deserves scrutiny. A model trained on human demonstrations, however vast the dataset, inherently internalizes human biases and limitations. True generality would require the robot to independently discover physical principles, to formulate its own ‘rules’ for interacting with the world-not simply extrapolate from observed human behavior. One anticipates the inevitable need for active experimentation – letting the robot break things, in a controlled manner, to refine its internal model and identify the boundaries of its predictive power.
Long-horizon prediction, the ultimate goal, remains tantalizingly out of reach. The universe, after all, is under no obligation to be predictable. The pursuit of a perfect world model isn’t about achieving omniscience, but about constructing a sufficiently accurate approximation – one that’s useful, even if it’s fundamentally flawed. The next iteration won’t be about more data, but about a more rigorous methodology for evaluating the model’s ignorance – quantifying what it doesn’t know, and designing strategies for gracefully handling the inevitable surprises.
Original article: https://arxiv.org/pdf/2602.06949.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-09 17:02