Author: Denis Avetisyan
As artificial intelligence systems grow more complex, simply knowing what they decide isn’t enough – we need to understand why, and current explainability methods fall short when applied to increasingly autonomous agents.
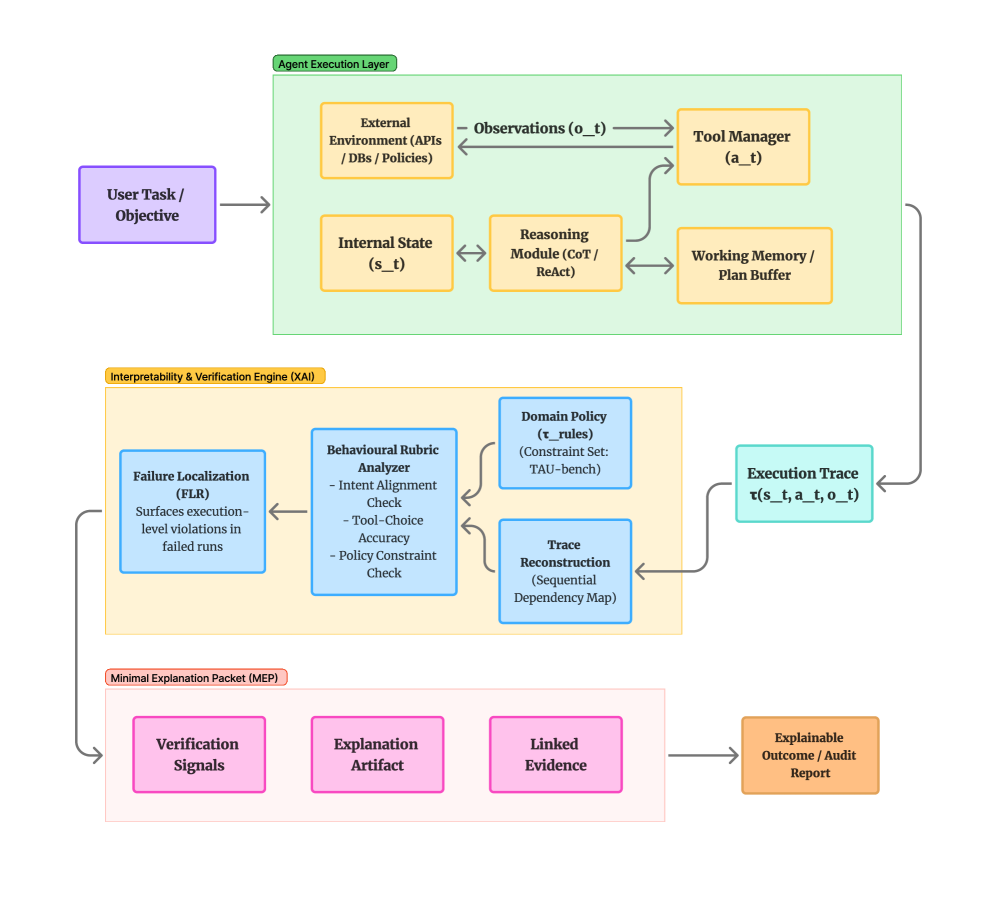
This review argues for trace-level analysis and rubric-based evaluation to effectively diagnose failures and improve transparency in agentic AI systems.
While explainable AI has progressed rapidly for static predictions, its application to increasingly prevalent agentic systems-those exhibiting multi-step behavior-remains largely unexplored. This work, ‘From Features to Actions: Explainability in Traditional and Agentic AI Systems’, bridges this gap by comparing traditional attribution-based explanations with trace-based diagnostics across both static and agentic settings. Our findings reveal that while attribution methods offer stable feature rankings in static tasks, they fail to reliably diagnose failures in agentic trajectories-in contrast to trace-grounded rubric evaluation which consistently localizes behavioral breakdowns and identifies state tracking inconsistency as a key failure mode. Does this necessitate a shift towards trajectory-level explainability to effectively evaluate and debug the complex behavior of autonomous AI agents?
Navigating the Rise of Agentic Systems: The Explainability Imperative
Large language models (LLMs) are no longer simply text predictors; they are increasingly the brains behind agentic systems capable of autonomous action. These agents, powered by LLMs, demonstrate a remarkable capacity to perform complex tasks, from scheduling meetings and managing emails to conducting online research and even writing code. This rapid evolution signifies a shift towards widespread automation across numerous domains, with potential applications in customer service, data analysis, and creative content generation. The core promise lies in their ability to perceive, reason, and act in dynamic environments, offering a level of flexibility and adaptability previously unattainable with traditional automation tools. Consequently, the development and deployment of LLM-based agents are accelerating, driven by the potential to reshape workflows and enhance productivity across various industries.
The increasing sophistication of large language model-based agents, while promising unprecedented automation, is fundamentally challenged by their inherent opacity. These systems often arrive at conclusions or take actions without revealing a clear, traceable reasoning process, effectively operating as “black boxes”. This lack of transparency poses significant risks to both trust and safety, particularly in high-stakes applications like healthcare or finance, where understanding why a decision was made is as crucial as the decision itself. Without the ability to inspect and validate the internal logic driving agent behavior, potential biases, errors, or unintended consequences can remain hidden, hindering responsible deployment and widespread adoption. Addressing this challenge requires innovative approaches to not only evaluate agent performance, but to illuminate the decision-making pathways that lead to their outputs.
Assessing the capabilities of increasingly complex LLM-based agents demands more than simple accuracy scores; robust behavioral rubrics are crucial for discerning how an agent arrives at a decision, not just if it is correct. Current evaluations, such as those utilizing the TAU-bench Airline and AssistantBench benchmarks, reveal modest performance – 56.0% and 17.39% respectively – underscoring a significant gap in reliable assessment. These scores aren’t simply numbers, but indicators that existing methods struggle to fully capture agent competence and identify potential failure modes. Consequently, the development of comprehensive explainability methods is paramount, allowing researchers and developers to peer inside the ‘black box’ and build trust in these rapidly evolving systems, ensuring they align with human values and operate safely in real-world applications.
Defining Agent Success: The Importance of Behavioral Rubrics
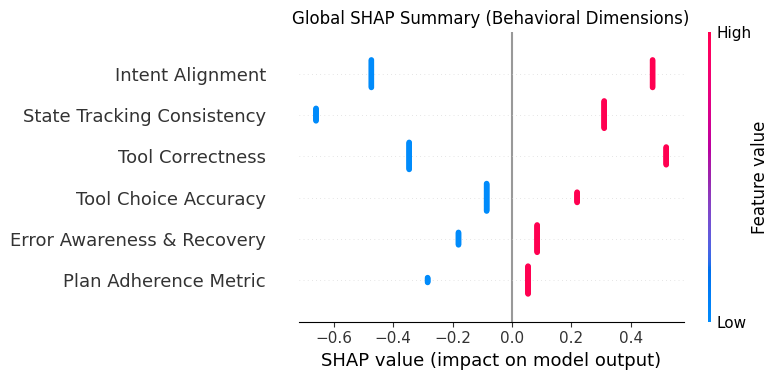
Standardized evaluation of large language model (LLM) agents necessitates quantifiable metrics beyond simple task completion. State Tracking Consistency assesses the agent’s ability to accurately maintain and utilize information about the conversational or environmental context throughout an interaction; errors in this area directly impact the agent’s capacity to provide relevant and coherent responses. Tool Choice Accuracy measures the agent’s selection of appropriate tools or APIs to fulfill a given request, with incorrect tool usage leading to failed actions or irrelevant results. Defining these criteria allows for objective scoring and comparison of agent performance, moving beyond subjective assessments and facilitating iterative improvement through targeted training and refinement.
Docent is a system designed to streamline the process of evaluating large language model (LLM) agents by enabling the creation of labeled datasets of agent execution traces. These traces, consisting of the agent’s actions and observations during a task, are annotated with judgments regarding correctness, adherence to rubrics like State Tracking Consistency and Tool Choice Accuracy, and other relevant metrics. This annotation process is facilitated through a user interface and programmatic APIs, allowing for both manual review and automated labeling. The resulting labeled data can then be used to train and evaluate automated evaluation metrics, as well as to provide insights into agent behavior and identify areas for improvement. Docent supports various data formats and integrates with common LLM evaluation frameworks, allowing for comprehensive and objective assessment of agent performance.
Current evaluation of agent performance relies on benchmark datasets designed to simulate real-world interactions. TAU-bench Airline and AssistantBench are two such benchmarks; as of recent evaluations, agents achieve a success rate of 56.0% on the TAU-bench Airline tasks and 17.39% on AssistantBench. These benchmarks provide standardized environments and task definitions, allowing for objective comparison of different agent architectures and training methodologies. Performance is typically measured by the percentage of tasks completed successfully according to pre-defined criteria within each benchmark, offering a quantitative assessment of agent capabilities.
Illuminating the ‘Black Box’: Approaches to Agent Explainability
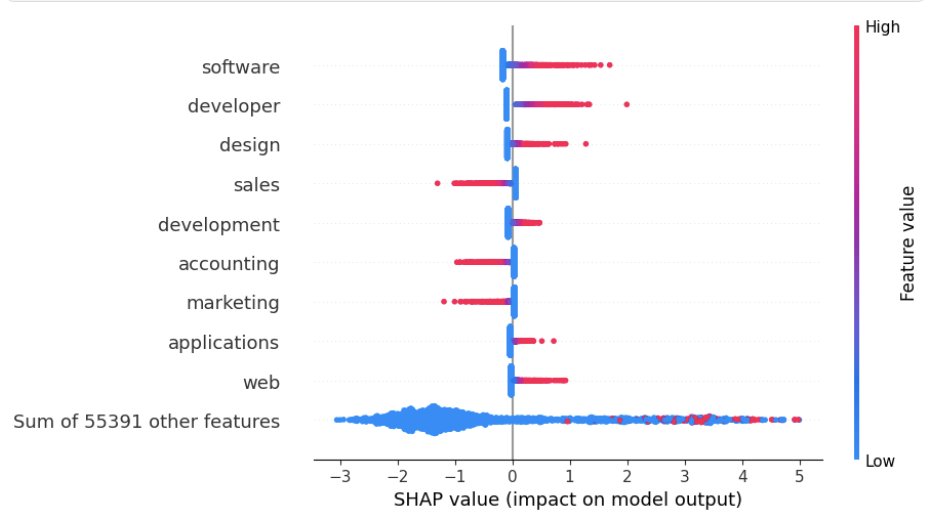
Static Prediction Explainability techniques aim to elucidate the reasoning behind individual predictions made by an agent. Methods such as SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), and Partial Dependence Plots (PDPs) function by analyzing the relationship between input features and the resulting output for a single instance. SHAP utilizes concepts from game theory to assign each feature a value representing its contribution to the prediction. LIME approximates the agent’s behavior locally with a simpler, interpretable model. PDPs, conversely, demonstrate the marginal effect of one or two features on the predicted outcome, averaged across the entire dataset. These techniques provide post-hoc explanations, meaning they are applied after the agent has made its prediction, and focus on understanding what factors influenced a specific decision, rather than how the agent arrived at it over time.
Trajectory-Level Explainability addresses the limitations of static methods by focusing on the sequence of states and actions leading to an agent’s ultimate decision. Unlike static explainability which analyzes a single prediction, trajectory-level techniques examine the agent’s complete behavioral path, including intermediate observations and reasoning steps. This is crucial for understanding why an agent made a series of choices, rather than simply identifying factors influencing a final outcome. Methods in this category often involve analyzing logged agent execution data to reconstruct and interpret the decision-making process, providing insights into potential biases, unintended consequences, or emergent behaviors exhibited over time.
HAL-Harness facilitates detailed analysis of agent behavior by providing a standardized framework for agent execution and comprehensive logging of internal states and actions. This standardization is critical for applying explainability techniques, as variations in execution environments can introduce noise. Evaluation of static explainability methods using HAL-Harness data indicates varying robustness; specifically, models employing TF-IDF features coupled with Logistic Regression demonstrated a Spearman correlation of 0.8577 under perturbation, while Text CNN models exhibited a lower correlation of 0.6127. These correlation values represent the stability of explanations generated by these methods when subjected to minor input variations, highlighting the importance of evaluating and selecting explainability techniques appropriate for specific agent architectures and deployment scenarios.
Building Trust Through Transparent Agent Reasoning
Establishing confidence in increasingly complex agentic systems hinges on not only demonstrating performance, but also illuminating the reasoning behind it. Robust evaluation benchmarks, when paired with comprehensive explainability techniques, are proving vital in this endeavor. One promising approach involves the use of Minimal Explanation Packets – concise summaries of the key information an agent considered when reaching a decision. These packets allow observers to trace the agent’s thought process, identifying potential flaws or biases and validating its conclusions. This transparency fosters trust by moving beyond a ‘black box’ model, where outputs are simply accepted, to a system where reasoning can be scrutinized and understood, ultimately increasing reliance on these autonomous systems.
Modern agentic systems are increasingly leveraging techniques such as Reflexion and ReAct to not only improve performance, but also to establish a crucial layer of transparency. Reflexion enables agents to critically evaluate their own past actions and learn from failures, while ReAct facilitates a cyclical process of reasoning and acting, allowing for more deliberate and justifiable decision-making. Complementing these approaches, Retrieval-Augmented Generation (RAG) equips agents with the ability to ground their responses in external knowledge sources, further bolstering the validity and explainability of their conclusions. This confluence of methods moves beyond simply achieving a result to demonstrating how that result was reached, fostering user trust by revealing the agent’s internal thought process and supporting evidence.
A recent analysis of agent performance on the TAU-bench Airline task demonstrates a strong correlation between maintaining consistent state tracking and overall success. Researchers found that failures in an agent’s ability to accurately monitor and update its understanding of the environment – termed “State Tracking Consistency” violations – occurred 2.7 times more frequently in unsuccessful runs. Perhaps more telling, even when an agent did manage to complete the task despite such inconsistencies, its success rate plummeted to just 0.51. This data underscores the critical importance of reliable state tracking; an agent can employ sophisticated reasoning and retrieval techniques, but if it loses sight of the current situation, its performance is severely compromised, suggesting that consistent environmental awareness is a foundational element for building truly reliable agentic systems.
Envisioning the Future of Agentic Systems: Towards Self-Aware Intelligence
The progression of agentic systems necessitates a shift beyond mere action explanation towards robust justification capabilities. Future research prioritizes equipping artificial intelligence with the capacity to rationalize decisions not simply by detailing what was done, but by articulating why – grounding those reasons in established ethical frameworks and relevant domain expertise. This involves integrating complex reasoning processes, allowing agents to demonstrate adherence to pre-defined values and provide transparent, understandable justifications for their behavior. Such a capability is crucial for building trust and ensuring alignment between artificial intelligence and human values, ultimately fostering collaborative partnerships where AI actions are not only predictable but also ethically sound and logically defensible.
Current research explores the synergistic potential of combining explainability methods directly into the learning processes of intelligent agents. Rather than treating explanation as a post-hoc analysis of decisions, these systems are designed to learn from explanations of their own errors. By analyzing why a particular action led to an undesirable outcome – perhaps through counterfactual reasoning or identifying violated constraints – the agent can refine its internal models and improve future performance. This creates a feedback loop where explanation isn’t just about understanding what happened, but about actively learning how to do better, leading to more robust, adaptable, and ultimately, more intelligent systems capable of continuous self-improvement.
The progression towards explainable and justifiable artificial intelligence holds the potential to unlock genuinely self-aware systems capable of seamless human collaboration. These future agents won’t merely perform tasks, but will articulate the reasoning behind their actions, grounding decisions in established ethical frameworks and relevant knowledge domains. This transparency is crucial for building trust and ensuring safety, as humans can understand, validate, and even correct an agent’s logic when necessary. Consequently, such systems promise not just increased efficiency, but also a collaborative partnership where artificial intelligence augments human capabilities in a reliable and beneficial manner, fostering innovation across diverse fields and redefining the boundaries of problem-solving.
The pursuit of understandable systems necessitates a shift from merely attributing feature importance to meticulously tracing behavioral trajectories, as the article champions. This mirrors Barbara Liskov’s observation: “Programs must be right first, then fast.” A system exhibiting complex, agentic behavior, even if superficially functional, remains brittle if its underlying decision-making process lacks transparency. Without trace-level analysis – a deep dive into the ‘how’ and ‘why’ of each step – identifying the root cause of failure becomes akin to applying duct tape to a fundamentally flawed structure. The article’s emphasis on rubric-based evaluation provides a framework for assessing not just what an agent does, but how it does it, aligning with the principle that robust design stems from a holistic understanding of the system’s internal logic.
Where Do We Go From Here?
The pursuit of explainability often feels like a relentless attempt to map the ghost onto the machine. Traditional attribution methods, while useful for simpler systems, reveal little about the emergent behavior of agentic AI. To treat such systems as merely complex functions invites a perpetual crisis of opacity; each added layer of sophistication obscures the underlying rationale, not clarifies it. The work presented here suggests a shift in focus-from what an agent does to how it arrived at that action-but this is merely a diagnostic, not a solution.
A true understanding requires a move toward behavioral rubrics-a way to assess not just the outcome, but the quality of the reasoning process. Such rubrics, however, are inherently subjective. The challenge lies in formalizing these assessments, embedding them into the agent’s training, and accepting that perfect transparency may be an illusion. A system that appears ‘clever’ should immediately be suspect; elegant design emerges from simplicity, and fragility lurks within complexity.
Future work should explore the interplay between these rubrics and the agent’s internal state. Can an agent explain its own reasoning, not through post-hoc justifications, but through a demonstrable alignment with pre-defined behavioral principles? Perhaps the ultimate goal isn’t to understand the agent, but to build agents that understand themselves-and, crucially, that can communicate that understanding in a way that is both meaningful and trustworthy.
Original article: https://arxiv.org/pdf/2602.06841.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-09 13:45