Author: Denis Avetisyan
Researchers have developed a system that autonomously learns and refines scientific principles by actively seeking out and resolving uncertainty in experimental data.
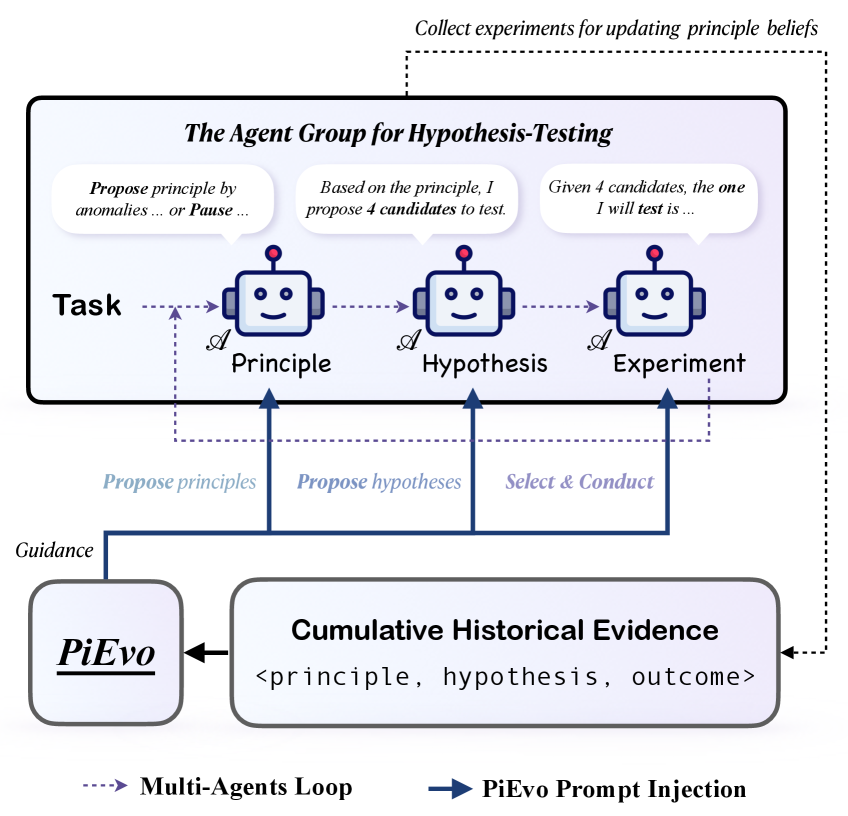
PiEvo utilizes Bayesian optimization and anomaly detection to minimize regret and achieve state-of-the-art results in scientific discovery benchmarks.
Current large language model-based scientific agents, while accelerating discovery, often operate within fixed theoretical frameworks, limiting their ability to adapt and efficiently explore novel phenomena. This work, ‘Principle-Evolvable Scientific Discovery via Uncertainty Minimization’, introduces PiEvo, a framework that shifts the focus from hypothesis testing to evolving the underlying scientific principles through Bayesian optimization and anomaly detection. PiEvo achieves state-of-the-art results across multiple benchmarks, demonstrating significant improvements in solution quality and convergence speed by optimizing a compact principle space. Could this principle-evolving approach unlock a new paradigm for autonomous scientific exploration and accelerate breakthroughs across diverse domains?
Navigating Complexity: The Limits of Traditional Inquiry
The pursuit of scientific understanding increasingly encounters systems defined by intricate interactions and enormous combinatorial possibilities. Traditional methods, reliant on focused experimentation and deductive reasoning, often falter when confronted with this complexity; the sheer number of potential hypotheses expands beyond practical manual evaluation. Consider, for instance, the challenge of modeling protein folding or predicting climate change – each involves a multitude of variables and feedback loops creating a hypothesis space so vast that exhaustive testing becomes impossible. This limitation isn’t merely a matter of computational power, but a fundamental difficulty in navigating such expansive landscapes, demanding innovative approaches to efficiently identify governing principles and meaningful relationships within these complex systems.
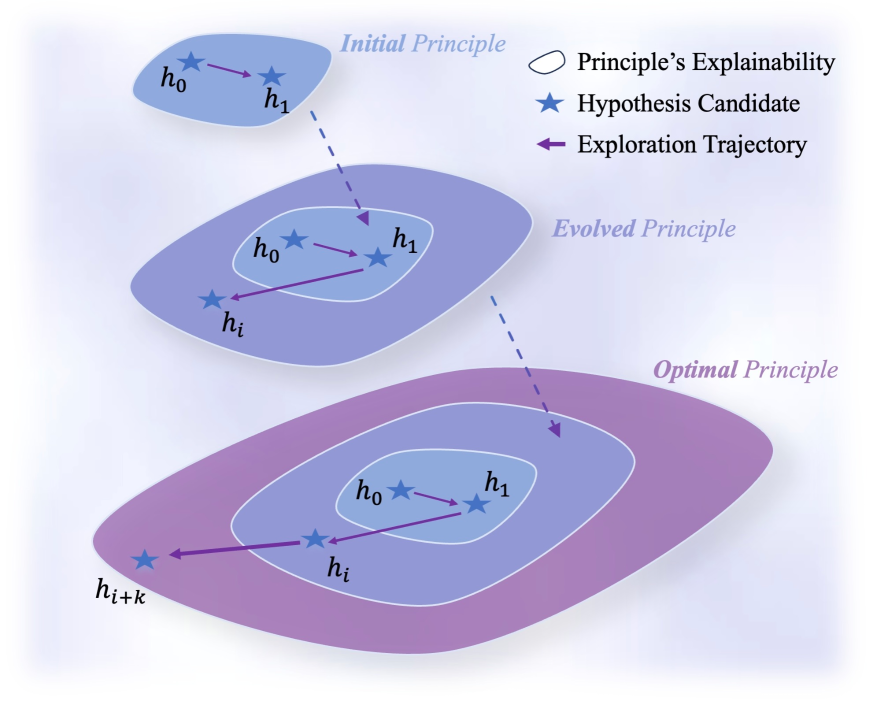
The sheer complexity of modern scientific inquiry renders exhaustive manual exploration of potential principles impossible. As systems increase in dimensionality and the number of interacting variables grows, the hypothesis space expands exponentially, quickly exceeding the capacity of human researchers to systematically investigate every possibility. This intractability necessitates the development of automated approaches capable of sifting through vast datasets, identifying patterns, and formulating testable hypotheses without constant human intervention. These automated systems leverage computational power to explore a far greater range of possibilities than could ever be achieved through traditional methods, ultimately accelerating the pace of scientific discovery and uncovering previously hidden relationships within complex phenomena.
The pursuit of scientific breakthroughs often relies on optimization techniques – algorithms designed to find the best solution from a multitude of possibilities. However, these methods frequently encounter a significant hurdle: local optima. Imagine a landscape with many hills and valleys; an optimization algorithm, seeking the lowest point, can become stuck in a valley that appears to be the absolute bottom, but is merely a local minimum. This occurs because the algorithm only explores the immediate surroundings, failing to identify a deeper, global optimum elsewhere in the landscape. Consequently, promising avenues of research can be overlooked, and truly novel discoveries are hindered as the search process prematurely converges on a suboptimal solution. This limitation underscores the need for innovative approaches that can effectively escape these local traps and navigate the complex hypothesis spaces inherent in scientific inquiry.
![Utilizing Coherent Augmentation, the PiEvo system iteratively evolves its principle space by integrating new candidate principles [latex]P_{new}[/latex] in response to high-surprise anomalies, ultimately optimizing the trajectory toward the true principle [latex]P^{\star}[/latex] and enabling the identification of the optimal hypothesis.](https://arxiv.org/html/2602.06448v1/x2.png)
PiEvo: A System for Evolving Principles
PiEvo operates as a systematic framework for principle refinement and optimization utilizing Bayesian updating. This process involves iteratively adjusting principles based on incoming experimental data, weighted against pre-existing beliefs about their validity. The Bayesian approach allows PiEvo to quantify uncertainty in each principle and prioritize exploration of those with the highest potential for improvement. This contrasts with purely empirical methods by incorporating prior knowledge, accelerating the convergence towards optimal principles and improving solution quality as demonstrated by achieved results of 90.81% – 93.15%.
PiEvo employs a ‘WorkingPrincipleSet’ as a computational strategy to address the complexity inherent in its ‘UniversalPrincipleSpace’. The UniversalPrincipleSpace represents the complete set of potential principles guiding the system, which is often too large for exhaustive evaluation. Consequently, PiEvo focuses computational resources on a significantly smaller, actively managed subset – the WorkingPrincipleSet – allowing for efficient Bayesian optimization and principle refinement. This targeted approach prioritizes principles deemed most promising based on current evidence, enabling practical application and scalability without sacrificing the potential for discovering high-performing solutions within the broader principle landscape.
BayesianOptimization forms the core refinement mechanism within PiEvo, iteratively adjusting principles based on the integration of experimental data and pre-existing probabilistic beliefs. This process utilizes a surrogate model to approximate the performance of each principle and an acquisition function to determine which principle to evaluate next, balancing exploration of novel principles with exploitation of those already showing promise. Through repeated cycles of evaluation and model updating, the framework converges on an optimized set of principles, demonstrably achieving a solution quality consistently within the 90.81% – 93.15% range across tested problem sets.
Intelligent Exploration: Directing the Search for Truth
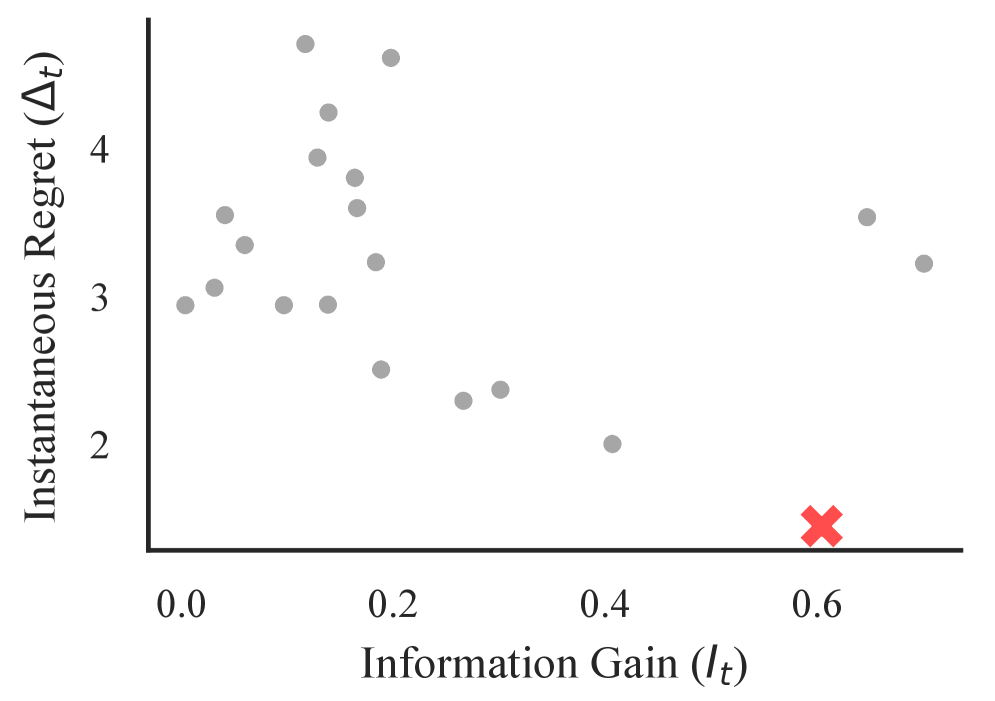
Information-Directed Sampling (IDS) operates on the principle of actively selecting hypotheses not based on their immediate promise, but on their potential to resolve the largest amount of current uncertainty within the search space. This is achieved by quantifying the expected reduction in entropy – a measure of uncertainty – associated with each potential hypothesis. Specifically, IDS employs a probabilistic model to estimate the information gain – the reduction in uncertainty – that would result from evaluating a given hypothesis. Hypotheses yielding the highest predicted information gain are then prioritized for evaluation, effectively directing the search towards areas where knowledge is most lacking and where data acquisition will be most impactful in refining the overall understanding of the problem. This contrasts with purely exploitative methods that focus solely on improving existing beliefs and may overlook potentially valuable, yet unexplored, regions of the search space.
Information-Directed Sampling (IDS) operates on the principle of maximizing information gain to strategically balance exploration and exploitation. This is achieved by prioritizing hypotheses not based on their immediate reward, but on their potential to reduce overall uncertainty in the model. The algorithm evaluates hypotheses based on their expected reduction in entropy or variance, effectively quantifying the value of acquiring new data. By actively seeking out data that resolves the greatest ambiguity, IDS avoids premature convergence on suboptimal solutions and efficiently allocates resources to areas where learning is most impactful. This approach allows the system to continuously refine its beliefs while simultaneously exploring potentially more rewarding, yet uncertain, regions of the search space.
Intelligent Exploration with Information-Directed Sampling (IDS) leverages Gaussian Process (GP) expert models to improve sampling efficiency. GPs provide a probabilistic representation of the environment, enabling accurate likelihood estimation of potential hypotheses. This accurate likelihood representation, combined with the information-directed sampling strategy, results in a demonstrably high Average Pairwise Distance (APD) between sampled points. A high APD indicates that the IDS algorithm effectively explores the search space, avoiding redundant sampling and prioritizing diverse, informative regions for further investigation; this is crucial for efficiently identifying optimal solutions in complex environments.
The Evolution of Understanding: Measuring Discovery
The ongoing refinement of any predictive framework hinges on its ability to recognize when expectations diverge from reality. AnomalyDetection serves as a critical component in this process, constantly evaluating the framework’s predictions against observed data. When discrepancies arise – anomalies – they signal a potential gap in the current understanding, prompting a focused re-evaluation of the underlying principles. These anomalies aren’t merely errors; they are opportunities to expand the ‘WorkingPrincipleSet’, the collection of rules governing the system’s behavior. By systematically identifying and addressing these discrepancies, the framework evolves, becoming more comprehensive and accurate in its ability to model complex phenomena. This iterative process of prediction, observation, and refinement is fundamental to the system’s adaptability and its capacity to uncover previously unknown relationships.
The architecture inherently prioritizes ongoing refinement and the capacity to integrate new understandings. Through continuous comparison of predicted outcomes against observed data, the system isn’t simply validating existing principles, but actively seeking deviations that signal the need for adaptation. This dynamic process allows the framework to evolve beyond its initial parameters, identifying previously unknown relationships and incorporating them into its core operational logic. Consequently, the system demonstrates a capacity for genuine discovery, extending its explanatory power and remaining relevant even as new information challenges established models – a critical feature for navigating complex and ever-changing systems.
The true measure of PiEvo’s effectiveness lies in its ‘DiscoveryTime’ – the duration required to pinpoint accurate underlying principles governing a system. Rigorous testing reveals a substantial performance advantage, with PiEvo achieving an 83.3% speedup in identifying these principles compared to the PiFlow framework. This accelerated discovery isn’t achieved at the expense of accuracy; in fact, PiEvo consistently surpasses baseline performance by up to 31.06% in the quality of the solutions it generates, suggesting a more efficient and robust approach to uncovering fundamental relationships within complex data.
![PiEvo achieves optimal performance across all tasks, demonstrating a superior trade-off between exploration, measured by [latex]APD[/latex], and exploitation, quantified by [latex]AUOC[/latex], as evidenced by its position on the Pareto frontier.](https://arxiv.org/html/2602.06448v1/x13.png)
The pursuit within PiEvo, as detailed in the article, echoes a fundamental tenet of inquiry: dismantling assumptions to reveal underlying truths. It’s a process of controlled disruption, leveraging anomaly detection not as a failure state, but as a signal – a deviation demanding explanation. This resonates deeply with Alan Turing’s assertion: “Sometimes people who are unhappy tend to look for a person to blame.” While seemingly disparate, Turing’s observation speaks to the human tendency to seek easy answers, to cling to existing models even when confronted with contradictory evidence. PiEvo, by actively seeking anomalies and refining principles through Bayesian optimization, deliberately resists this inclination, embracing uncertainty as a pathway to more robust understanding. The framework doesn’t simply accept the established order; it interrogates it, relentlessly testing the boundaries of current knowledge.
Where Do We Go From Here?
The PiEvo framework, in its pursuit of principle-guided learning via uncertainty minimization, inevitably highlights what remains stubbornly resistant to automation: the genesis of truly novel insight. While the system excels at refining existing principles and identifying anomalies, it operates, fundamentally, within a defined search space. The true breakthroughs rarely arrive by diligently minimizing regret; more often, they emerge from cheerfully violating established rules – from intentionally introducing ‘errors’ to see what unexpected structures arise. One wonders if future iterations might benefit from a controlled injection of chaos, a deliberate courting of the improbable.
Current benchmarks, however cleverly designed, still represent a known universe. The real test will lie in applying such frameworks to genuinely open-ended problems – to data streams where the ‘rules’ are not merely unknown, but perhaps nonexistent. Can PiEvo, or its successors, learn to identify when a principle itself is fundamentally flawed, rather than simply misapplied? Or will it remain a supremely efficient tool for optimizing within pre-existing paradigms?
Ultimately, the value of this work may not reside in its ability to discover scientific truths, but in its capacity to expose the limitations of discovery itself. The very act of formalizing the scientific method-of translating intuition into algorithms-reveals how much of the process relies on tacit knowledge, on the messy, unpredictable interplay of observation and imagination. And that, perhaps, is a lesson worth learning.
Original article: https://arxiv.org/pdf/2602.06448.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-09 12:16