Author: Denis Avetisyan
Researchers have developed a new deep learning framework that fuses data from lidar and depth sensors to create detailed terrain maps, enabling more stable and reliable locomotion for humanoid robots.
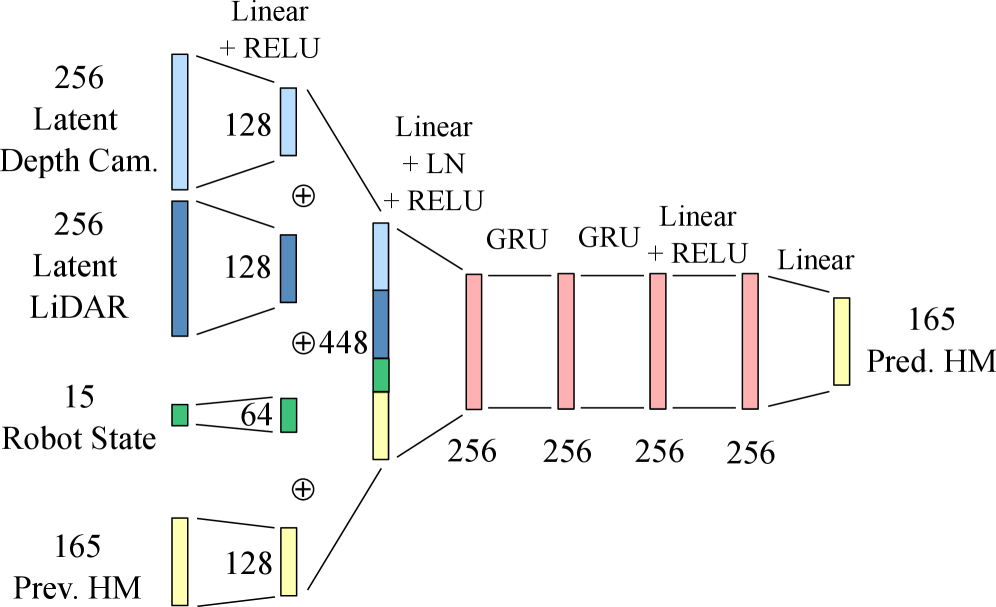
A hybrid autoencoder architecture leverages multimodal sensor fusion and temporal context to generate robust heightmaps for improved terrain perception.
Reliable terrain perception remains a key challenge for deploying humanoid robots in complex, real-world environments. This is addressed in ‘A Hybrid Autoencoder for Robust Heightmap Generation from Fused Lidar and Depth Data for Humanoid Robot Locomotion’, which presents a learning-based framework leveraging a hybrid encoder-decoder structure to generate robust heightmaps for locomotion. By fusing data from LiDAR, depth cameras, and an IMU, the proposed system demonstrates improved reconstruction accuracy and reduced mapping drift through multimodal sensor fusion and temporal context integration. Could this approach pave the way for more adaptable and resilient humanoid robots capable of navigating truly unstructured spaces?
Beyond Static Mapping: Embracing Dynamic Terrain Perception
Conventional robotic navigation relies heavily on techniques like Simultaneous Localization and Mapping (SLAM), yet these methods encounter significant difficulties when operating in real-world scenarios characterized by constant change and unpredictable layouts. While SLAM excels in static, well-defined spaces, its performance degrades substantially when confronted with dynamic obstacles – moving people or objects – or unstructured terrain like forests, construction sites, or disaster zones. The core issue stems from SLAM’s dependence on maintaining a consistent map; any substantial alteration to the environment necessitates costly re-mapping, leading to delays and potential navigational failures. Consequently, robots utilizing standard SLAM algorithms often exhibit hesitant or incorrect behaviors in these complex settings, highlighting the need for more adaptable and robust terrain perception systems capable of handling uncertainty and dynamism.
Effective robotic locomotion demands more than simply knowing where obstacles are; it requires a nuanced understanding of the terrain itself. Current terrain perception systems frequently fall short by delivering representations lacking the granularity needed for safe and efficient navigation. These systems often struggle to differentiate between traversable surfaces and those that pose a risk – a seemingly flat patch of ground might conceal subtle changes in elevation or friction. Consequently, path planning algorithms receive incomplete or inaccurate data, leading to hesitant movements, unexpected stops, or even failures in challenging environments. The limitations stem from an inability to capture critical details – the precise angle of a slope, the depth of loose gravel, or the presence of hidden obstacles beneath vegetation – all of which directly impact a robot’s ability to maintain stability and momentum during travel.
Creating a truly comprehensive understanding of terrain for robots demands skillful integration of data from diverse sensor modalities. While individual sensors – such as cameras, LiDAR, and tactile sensors – each offer unique strengths, their isolated outputs often present incomplete or conflicting information. The challenge lies in effectively fusing these heterogeneous data streams, accounting for varying noise levels, fields of view, and measurement frequencies. Algorithms must intelligently reconcile discrepancies and construct a cohesive, semantically rich representation of the environment, distinguishing between static obstacles, dynamic hazards, and traversable surfaces. Successfully addressing this sensor fusion problem is paramount, as it directly impacts a robot’s ability to navigate complex, unstructured terrains with robustness and adaptability, enabling more than just mapping – it allows for genuine terrain perception.

A Hybrid Perception Module for Detailed Terrain Reconstruction
The system utilizes a hybrid encoder-decoder structure to generate a robot-centric heightmap from both LiDAR and depth camera data. The encoder component employs a Convolutional Neural Network (CNN) to extract relevant spatial features from the input sensor data. Subsequently, the decoder utilizes a Gated Recurrent Unit (GRU) to model temporal dependencies within the data stream, enabling the system to account for changes in the environment over time. This architecture allows for the fusion of complementary information from both sensor modalities, resulting in a detailed and temporally consistent representation of the surrounding terrain.
The perception system utilizes a Convolutional Neural Network (CNN) within the encoder to process spatial characteristics of the LiDAR and depth camera data; this CNN extracts features like edges, textures, and object boundaries from individual sensor inputs. Complementing this, the decoder employs a Gated Recurrent Unit (GRU), a type of recurrent neural network, to analyze the sequential data and model temporal dependencies inherent in the sensor streams. This GRU architecture allows the system to account for changes in the environment over time and improve the accuracy of heightmap reconstruction by considering past observations when processing current data.
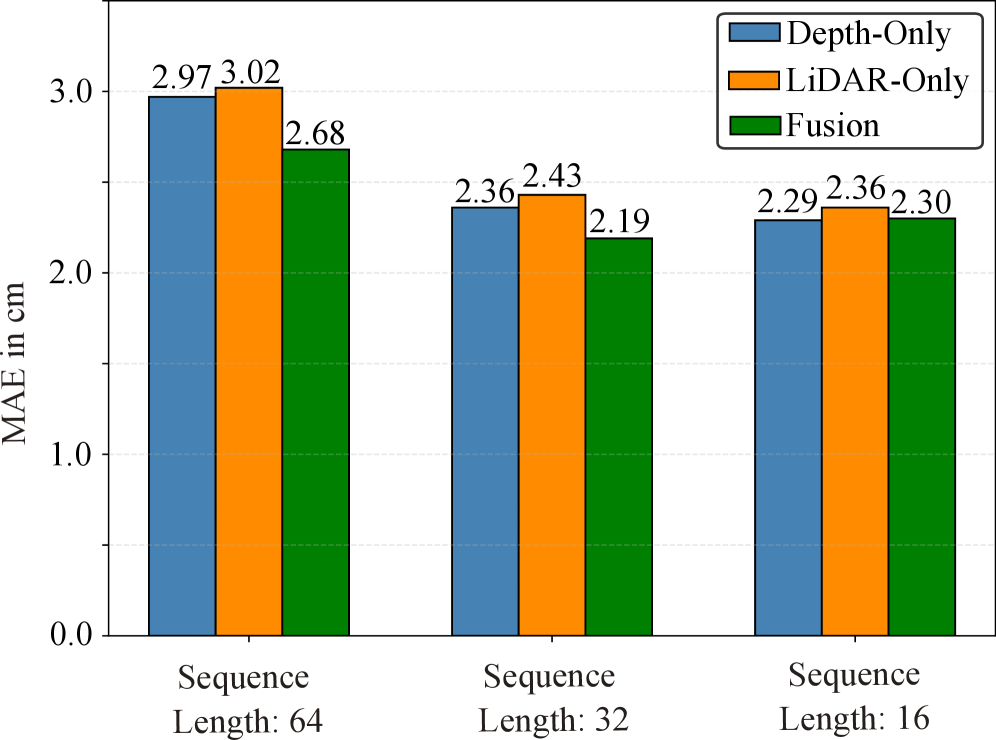
The integration of LiDAR and depth camera data through multimodal fusion enhances terrain understanding by leveraging the complementary strengths of each sensor. LiDAR provides accurate long-range distance measurements, while depth cameras offer high-resolution textural information. This combination improves robustness against individual sensor limitations – for example, LiDAR performance can degrade in adverse weather, and depth cameras struggle with range. Quantitative evaluation demonstrates the effectiveness of this approach, achieving a mean absolute error (MAE) of 2.19 cm in heightmap reconstruction, indicating a high degree of accuracy in terrain representation.
Optimizing Perception: Strategies for Robustness and Accuracy
Domain Randomization is implemented during training to enhance the system’s robustness and generalization capabilities when deployed in novel environments. This technique involves systematically varying simulation parameters – including textures, lighting conditions, object placements, and camera viewpoints – during the training process. By exposing the system to a wide distribution of randomized environments, it learns to become invariant to specific environmental characteristics and instead focuses on core geometric features. This approach effectively increases the diversity of the training data without requiring the collection of real-world data for each possible scenario, leading to improved performance in unseen and unpredictable conditions.
Grid Spacing Optimization involves a systematic process of determining the ideal density of grid points used to represent the heightmap. This optimization balances the need for high-resolution detail with computational efficiency. A finer grid spacing – more grid points – allows for the capture of intricate terrain features but increases memory requirements and processing time. Conversely, a coarser grid spacing reduces computational load but may result in a loss of detail. The optimal grid spacing is determined through experimentation and analysis, evaluating the trade-offs between reconstruction accuracy and computational cost to achieve the most efficient and detailed heightmap representation.
The heightmap reconstruction process utilizes a combined loss function strategy to optimize both overall accuracy and the preservation of significant terrain details. Mean Squared Error (MSE) provides a global measure of reconstruction error, minimizing the average squared difference between predicted and ground truth height values. Complementing MSE, Edge-Aware Loss Functions specifically penalize errors at terrain edges and discontinuities, ensuring sharper feature representation and preventing blurring. This dual-loss approach prioritizes both minimizing overall height discrepancies and maintaining the integrity of critical topographical features within the reconstructed heightmap, leading to improved visual fidelity and downstream task performance.
Reconstruction accuracy is quantitatively assessed using Mean Absolute Error (MAE), which calculates the average magnitude of the error between reconstructed and ground truth heightmap values. Current performance achieves an MAE of 2.19 cm. This result represents a 7.2% improvement in accuracy when compared to configurations relying solely on depth data, and a 9.9% improvement over systems utilizing LiDAR data alone. The reported MAE value indicates the average deviation in reconstructed terrain height, providing a precise metric for evaluating system performance and demonstrating the benefits of the integrated approach.

Deep Reinforcement Learning for Adaptive Locomotion Control
A Deep Reinforcement Learning (DRL) framework was implemented to develop a locomotion policy leveraging data from the hybrid perception module. This integration allows the robot to learn optimal actions based on perceived environmental features. The DRL framework receives processed sensory input – specifically, the outputs of the hybrid perception module – as state information. This data is then used to train the policy network, enabling the robot to adapt its gait and maintain stability across various terrains. The resultant policy dictates motor commands, effectively closing the loop between perception and action for autonomous locomotion.
Proximal Policy Optimization (PPO) was selected as the reinforcement learning algorithm due to its ability to perform stable policy updates. PPO achieves this stability by incorporating a clipped surrogate objective function, limiting the policy update step to prevent drastic changes that could destabilize learning. This clipping mechanism ensures that the new policy remains close to the old policy, facilitating consistent improvement without catastrophic performance drops. The algorithm utilizes an advantage function to estimate the benefit of taking a particular action in a given state, guiding the policy towards actions that yield higher rewards. Furthermore, PPO incorporates a value function to reduce variance in the advantage estimation, contributing to more efficient learning and improved sample complexity.
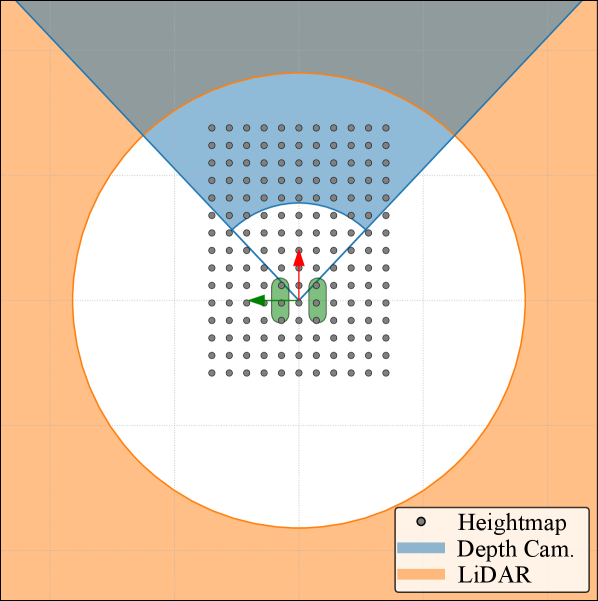
The locomotion policy utilizes a combined input vector comprising the robot’s kinematic state – specifically, its three-dimensional position, linear velocity, and orientation – alongside a robot-centric heightmap. The heightmap provides local terrain information, represented as a grid of elevation values relative to the robot’s current location. This data fusion allows the policy to directly correlate the robot’s current state with the surrounding terrain, enabling informed decisions regarding gait selection, step planning, and trajectory optimization for stable and efficient locomotion across varying surfaces.
Locomotion policies were trained utilizing the NVIDIA Isaac Lab simulation environment to facilitate rapid iteration and safe exploration of diverse and challenging terrains. This simulation-based training regimen yielded a quantifiable improvement in robustness, demonstrated by a 70.1% reduction in the incidence of falls during locomotion trials compared to baseline performance. The Isaac Lab environment allows for parallelized training runs and automated data collection, significantly accelerating the learning process and enabling the evaluation of the policy across a wide range of simulated conditions.

Towards Truly Adaptive and Robust Robotic Navigation
A significant advancement in robotic perception stems from the innovative application of spherical projection to LiDAR data. Traditional methods often struggle to efficiently process the point cloud data generated by LiDAR sensors within the convolutional neural network (CNN) frameworks commonly used for image-based perception. Spherical projection transforms the 3D point cloud into a 2D spherical image, effectively allowing the CNN to leverage its existing architecture and learned features for terrain understanding. This conversion not only simplifies the data format for processing but also preserves crucial spatial relationships, enabling the robot to accurately interpret the surrounding environment. By aligning LiDAR data with the visual processing strengths of CNNs, this technique facilitates robust obstacle detection, path planning, and ultimately, more reliable autonomous navigation across diverse and complex terrains.
The system’s ability to perceive and navigate complex terrains is significantly enhanced through the incorporation of temporal context. Rather than treating each LiDAR scan as an isolated data point, the framework analyzes sequences of scans, effectively building a short-term memory of the environment. This allows for the filtering of spurious noise – transient errors or reflections that might otherwise mislead the robot – and the consolidation of consistent terrain features over time. By considering how the environment changes between scans, the system can distinguish between genuine obstacles and temporary disturbances, leading to more reliable path planning and a more robust understanding of the surroundings even in dynamic or poorly lit conditions. This temporal smoothing is crucial for maintaining navigational accuracy and preventing the robot from reacting to fleeting anomalies.
The developed robotic navigation framework demonstrably enhances a robot’s ability to traverse difficult landscapes, achieving increased robustness through consistent performance even amidst unpredictable conditions. This is accomplished by synthesizing data from spherical projections with temporal context, allowing the system to effectively filter noise and maintain situational awareness. Consequently, robots equipped with this framework exhibit greater adaptability, responding dynamically to changes in terrain and obstacles without requiring explicit reprogramming for each new environment. This advancement isn’t merely about overcoming current limitations; it represents a significant step towards truly versatile and autonomous systems capable of operating reliably in complex, real-world scenarios, from search and rescue operations to planetary exploration.
Further development of this robotic navigation framework anticipates tackling increasingly intricate environments, moving beyond controlled settings to encompass dynamic, unstructured spaces like dense forests or disaster zones. Researchers aim to seamlessly integrate this perception system with sophisticated, high-level planning algorithms, enabling robots not just to see the terrain, but to strategically reason about optimal paths, anticipate potential obstacles, and adapt to unforeseen changes in real-time. This convergence of robust perception and intelligent planning promises to unlock truly autonomous navigation capabilities, fostering robots capable of independent operation and complex task completion in previously inaccessible areas, and ultimately expanding their utility in fields ranging from environmental monitoring to search and rescue operations.
The pursuit of robust terrain perception, as detailed in this work, echoes a fundamental principle of system design: interconnectedness. The framework’s hybrid autoencoder, fusing LiDAR and depth data, exemplifies how a holistic approach – considering multiple modalities and temporal context – yields stability. As Linus Torvalds aptly stated, “Talk is cheap. Show me the code.” This sentiment applies directly to the presented method; the elegance isn’t in theoretical claims, but in the demonstrable improvement to humanoid robot locomotion achieved through carefully constructed architecture and optimized heightmaps. The system’s behavior is dictated by its structure, and this research highlights how a well-defined structure can anticipate and mitigate weaknesses in complex environments.
The Road Ahead
The pursuit of robust terrain perception for legged locomotion invariably reveals the elegance – and fragility – of simplified representations. This work demonstrates the power of fusing multimodal data within a learned heightmap framework, but it also implicitly highlights the information lost in that very compression. The resulting heightmap, while effective, remains an abstraction; a useful lie, if you will. Future efforts must confront the inevitable trade-off between representational fidelity and computational tractability.
A natural progression lies in exploring architectures that delay this simplification. Perhaps a learned, variable-resolution representation – one that retains fine detail where needed, and coarsens elsewhere – could offer a more nuanced balance. Furthermore, the current framework, like many, treats perception as a feedforward process. Integrating predictive models – anticipating terrain changes based on robot action – could offer a proactive, rather than reactive, locomotion strategy.
Ultimately, the true challenge isn’t simply mapping the world, but understanding it. A heightmap, however cleverly generated, remains a static snapshot. The next generation of algorithms must move beyond surface geometry, incorporating semantic understanding – differentiating between traversable ground and impassable obstacles – to achieve truly adaptable and intelligent locomotion.
Original article: https://arxiv.org/pdf/2602.05855.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-08 12:26