Author: Denis Avetisyan
New research tackles the challenge of ambiguous instructions, enabling robots to interpret intent and successfully complete tasks in real-world settings.
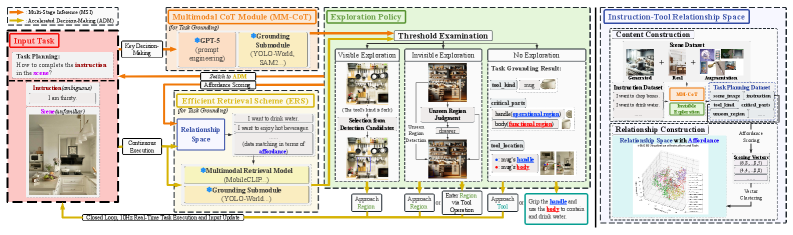
A novel framework combining affordance analysis and interactive exploration allows robots to reliably execute tasks from imprecise language commands.
Despite advances in robotic perception, reliably interpreting ambiguous human instructions for real-world task execution remains a significant challenge. This paper introduces ‘Affordance-Aware Interactive Decision-Making and Execution for Ambiguous Instructions’-a novel framework, AIDE, that integrates interactive environmental exploration with vision-language reasoning to enable robots to identify task-relevant objects and plan effective actions. Through a dual-stream architecture leveraging affordance analysis, AIDE achieves over 80% task planning success and 95% accuracy in continuous execution at 10 Hz, surpassing existing vision-language model-based approaches. Could this affordance-aware, interactive approach unlock more robust and intuitive human-robot collaboration in complex, open-world scenarios?
Bridging Perception and Action: The Essence of Intelligent Robotics
Robotic task planning, despite advancements in artificial intelligence, frequently encounters difficulties when bridging the gap between human language and physical action. Traditional AI systems often treat visual perception and linguistic instruction as separate data streams, hindering their ability to understand requests within a real-world context. A robot might accurately identify objects in a scene, but struggle to correlate that visual data with the nuanced meaning of a command like “bring me the slightly dented red mug.” This disconnect stems from the difficulty in creating algorithms that can seamlessly integrate symbolic language with continuous sensory input, demanding a new generation of AI capable of true cross-modal reasoning and adaptable task execution.
Current robotic systems attempting to interpret human instructions and translate them into action frequently falter when faced with the inherent ambiguity of natural language. These systems typically rely on massive datasets for pre-training, essentially learning to associate specific phrases with pre-defined actions, or require developers to painstakingly hand-engineer features to disambiguate commands. This reliance creates a significant bottleneck; even slight variations in phrasing or novel situations can disrupt performance, hindering the robot’s ability to generalize its understanding. Consequently, these approaches lack the adaptability and robustness necessary for operating in unpredictable, real-world environments, demanding continual refinement and limiting their potential for truly autonomous behavior.
The hallmark of genuine intelligence lies not merely in deciphering requests, but in translating them into feasible actions within a constantly changing world. A system capable of true cross-modal reasoning doesn’t simply register a command like “bring me the red block”; it internally maps that instruction to a sequence of motor actions, accounting for potential obstacles, the block’s precise location, and the robot’s own physical limitations. This requires a robust understanding of affordances – what the environment allows the robot to do – and the capacity to dynamically replan if initial assumptions prove incorrect. It’s a shift from passive comprehension to proactive problem-solving, where the system anticipates consequences and adapts its strategy, mirroring the flexible intelligence observed in biological organisms and representing a critical step towards truly autonomous robotics.
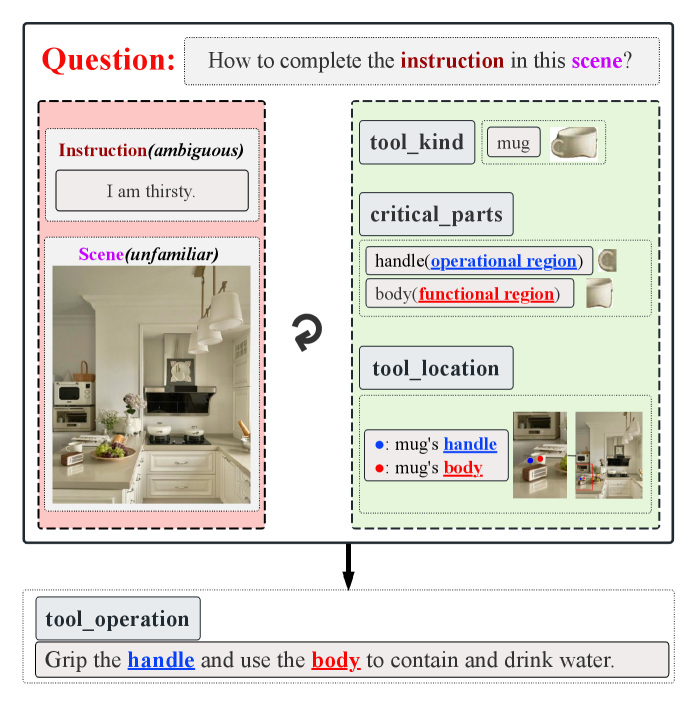
AIDE: A Framework for Harmonizing Language and Vision
AIDE employs a dual-stream architecture to facilitate cross-modal reasoning between language and visual inputs. This mechanism consists of a language stream processing textual instructions and a vision stream analyzing visual observations from the environment. These streams are not processed in isolation; rather, information is exchanged and correlated through a dedicated multimodal fusion layer. This layer allows the system to identify correspondences between linguistic references and visual elements, enabling AIDE to accurately interpret instructions in the context of the observed scene. The dual-stream approach enhances robustness by allowing the system to leverage complementary information from both modalities, mitigating ambiguities or inaccuracies present in either the language or visual input alone.
The AIDE framework’s Multimodal Chain-of-Thought (CoT) Module utilizes the GPT-5 Large Language Model to facilitate task decomposition. This module receives both language-based task instructions and visual input, and then iteratively breaks down the overall objective into a sequence of discrete, executable steps. By leveraging GPT-5’s reasoning capabilities, the CoT module generates a plan consisting of these intermediate actions, enabling the system to address complex tasks that would be intractable with a single-step approach. The generated plan serves as a guide for subsequent execution, allowing AIDE to navigate and manipulate its environment based on the decomposed task structure.
The AIDE framework’s Multimodal Chain-of-Thought module integrates specialized vision models – YOLO-World and SAM2 – to enhance object detection and segmentation capabilities. YOLO-World provides robust object detection within visual scenes, while SAM2 performs precise segmentation to identify and isolate relevant object parts, specifically tools and their components, necessary for task execution. This combined approach enables the system to process visual information and make task-level decisions at a frequency of 10 Hz, facilitating real-time interaction and dynamic task planning.
Efficient Retrieval: Grounding Knowledge for Robust Performance
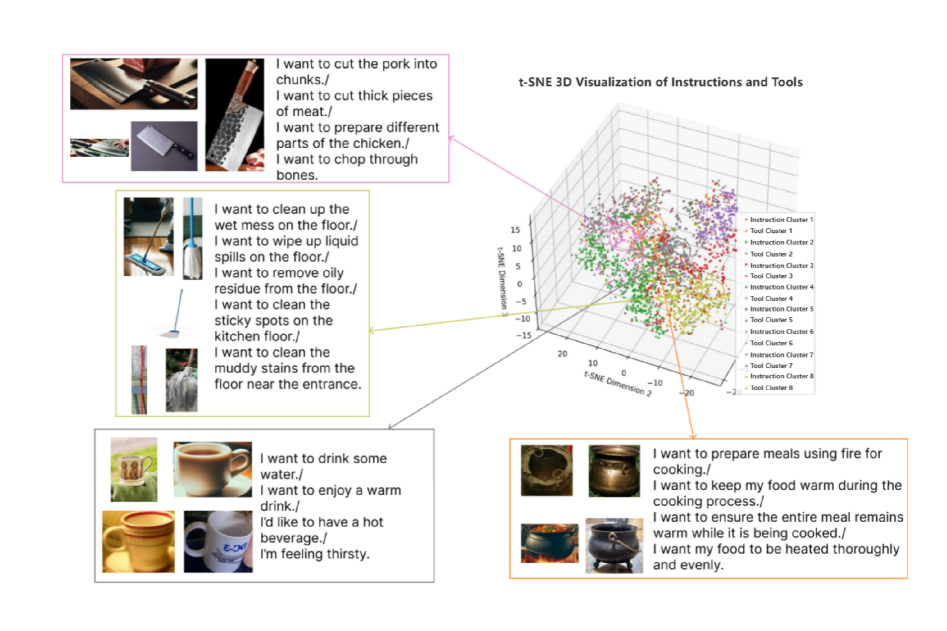
AIDE’s Efficient Retrieval Scheme (ERS) functions by querying an Instruction-Tool Relationship Space, which is a pre-computed and indexed database of successful task planning outcomes. This space stores associations between natural language instructions and the specific tools or sequences of tools required to fulfill those instructions. The indexing process enables rapid identification of previously solved tasks that are similar to the current input, facilitating the retrieval of relevant planning strategies. By leveraging this stored knowledge, ERS avoids redundant computation and allows AIDE to quickly access established solutions for common or recurring tasks.
The Efficient Retrieval Scheme (ERS) functions by accessing a pre-computed and indexed Instruction-Tool Relationship Space, enabling the system to quickly identify previously successful task planning outcomes applicable to current scenarios. This rapid retrieval of relevant solutions significantly reduces the computational time required for decision-making, as the system leverages existing knowledge rather than re-planning from first principles. Consequently, ERS enhances consistency in performance by applying proven strategies, particularly in complex scenarios where exhaustive re-planning might introduce errors or inefficiencies. This approach contributes to AIDE’s demonstrated accuracy rates, exceeding 80% across 400 test samples and achieving Task Planning Success Rates of 83% on the G-Dataset and 88% on the R-Dataset.
AIDE demonstrates a high degree of performance in task planning, achieving greater than 80% accuracy when evaluated across a test set of 400 samples. Specifically, the system attained an 83% Task Planning Success Rate on the G-Dataset and an 88% rate on the R-Dataset. These results indicate a substantial improvement over existing state-of-the-art task planning methods, as measured by these benchmark datasets and evaluation metrics.

Real-World Impact: Towards Truly Adaptive and Intelligent Systems
Central to achieving truly flexible robotic systems is the ability to understand how objects can be used – a process known as affordance analysis. AIDE distinguishes itself through a sophisticated approach to this challenge, enabling robots to move beyond pre-programmed routines and intelligently interact with unfamiliar environments. Rather than simply recognizing an object, the system determines what actions can be performed with it – can it be grasped, pushed, pulled, or used as a support? This understanding is not static; AIDE dynamically assesses affordances based on visual input and the robot’s current context, allowing for adaptable manipulation. By effectively bridging the gap between perception and action, AIDE empowers robots to complete complex tasks in unstructured settings, significantly enhancing their utility in diverse applications requiring real-world adaptability and problem-solving.
A core strength of the developed framework lies in its capacity for real-time closed-loop control, enabling robotic systems to dynamically respond to changing circumstances. This isn’t simply pre-programmed execution; the robot continuously perceives its environment through sensor data, compares the observed state to the desired outcome, and adjusts its actions accordingly – all within fractions of a second. This feedback loop is crucial for navigating unpredictable real-world scenarios, allowing for robust manipulation even when faced with unexpected obstacles or variations in object properties. Consequently, the system doesn’t merely attempt a task; it actively monitors performance, identifies errors, and refines its approach in real-time, leading to significantly improved reliability and adaptability in complex environments.
Demonstrating a significant leap in robotic capability, the AIDE framework achieves tool selection with remarkable accuracy-reaching 94.5% success on the G-Dataset and 95.0% on the R-Dataset. Equally impressive is its exploration success rate, exceeding 64.0% on the G-Dataset and 65.0% on the R-Dataset. These results aren’t merely incremental improvements; AIDE consistently outperforms existing baseline technologies by over 45%, establishing a new benchmark for performance. This high degree of reliability and adaptability positions AIDE as a compelling solution for diverse applications, ranging from optimizing efficiency in industrial automation settings to enhancing the functionality and responsiveness of assistive robots designed to support individuals in everyday tasks.
The work detailed in this paper echoes a fundamental principle of elegant engineering. AIDE’s approach to disambiguating instructions through affordance analysis and interactive exploration isn’t about adding complexity to address uncertainty; it’s about stripping away extraneous assumptions. This aligns perfectly with the belief that ‘talk is cheap. show me the code.’ By focusing on what an environment allows a robot to do, rather than layering abstract interpretations, AIDE demonstrates that true intelligence lies in minimizing the space between intention and action. The system’s emphasis on closed-loop control is a testament to the power of iterative refinement-a process of continuous subtraction to reveal the essential core of a task.
Further Steps
The persistent difficulty lies not in instructing a machine, but in accepting the inherent imprecision of language itself. This work, while demonstrating improved robustness to ambiguity, merely postpones the inevitable confrontation with semantic under-determination. Future iterations will undoubtedly refine affordance analysis, perhaps through larger datasets or more sophisticated feature extraction. However, such gains will be incremental.
A more fruitful line of inquiry concerns the robot’s capacity for productive misunderstanding. The system currently seeks to resolve ambiguity; it might instead learn to exploit it. True intelligence may not be found in minimizing uncertainty, but in navigating it efficiently. Closed-loop control, presently focused on task completion, should also encompass a self-assessment of interpretive confidence.
Ultimately, the challenge is not to build machines that understand instructions, but to build systems that are indifferent to the need for understanding. The pursuit of perfect semantic alignment is a baroque distraction. A simpler architecture, accepting and even embracing linguistic looseness, may prove surprisingly resilient.
Original article: https://arxiv.org/pdf/2602.05273.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-07 21:18