Author: Denis Avetisyan
New research shows that conversational AI can surprisingly replicate the irrational decision-making patterns common in human beings.
This study demonstrates that large language models can accurately emulate aggregate human choice behavior, specifically the status quo bias, in dialogue simulations.
Despite increasing reliance on artificial intelligence for decision support, a critical gap remains in understanding whether these systems can authentically replicate the nuances of human cognitive biases. Our research, ‘Emulating Aggregate Human Choice Behavior and Biases with GPT Conversational Agents’, addresses this by investigating the ability of large language models to reproduce established behavioral patterns – specifically, the status quo bias – within interactive conversational settings. We demonstrate that models based on GPT-4 and GPT-5 accurately emulate human decision-making under simulated cognitive load, mirroring biases observed in a human experiment with [latex]\mathcal{N}=1100[/latex] participants. This raises the intriguing possibility of using LLMs not just as decision-makers, but as realistic behavioral simulators for evaluating and refining bias-aware AI systems.
The Inevitable Distortion of Choice
Human cognition, despite its remarkable capabilities, isn’t a purely logical process; instead, decision-making is fundamentally shaped by systematic deviations from rationality known as cognitive biases. These aren’t random errors, but predictable patterns of thought that influence judgments and choices, even in individuals possessing high intelligence or expertise. From favoring information confirming existing beliefs – a phenomenon called confirmation bias – to overestimating the likelihood of events that are easily recalled, these biases operate largely outside of conscious awareness. Consequently, seemingly rational actors may consistently make suboptimal decisions in areas ranging from financial investments and medical diagnoses to personal relationships and political opinions, highlighting the pervasive influence of these mental shortcuts on the human experience.
Predictive accuracy in fields ranging from economics to public health hinges on acknowledging the potent influence of cognitive biases, particularly the ‘Status Quo Bias’. This pervasive tendency to favor existing states, even when objectively superior alternatives exist, demonstrably shapes decision-making in complex scenarios. Research indicates individuals often require significant incentives to deviate from default options, even if those defaults are not in their best interest – a phenomenon exploited in behavioral economics through strategies like opt-out enrollment programs. Consequently, models attempting to forecast human behavior must incorporate these predictable irrationalities; simply assuming rational actors consistently overlooks a fundamental aspect of cognitive processing and yields inaccurate projections regarding choices in everything from investment portfolios to healthcare selections.
Research into cognitive biases has historically favored tightly controlled laboratory settings, presenting participants with simplified choices to isolate specific thinking errors. However, this approach often struggles to reflect the messy, multifaceted nature of real-world decisions. These artificial scenarios, while useful for initial identification of biases, may not accurately capture how biases manifest when individuals face ambiguity, incomplete information, or competing priorities. Consequently, findings from these limited studies can exhibit weak generalization to more ecologically valid contexts, prompting a need for methodologies that better mirror the complexity of everyday life – such as utilizing big data, field experiments, or computational modeling – to gain a more robust understanding of how biases truly influence human behavior.
Simulating the Ghost in the Machine
Large Language Models (LLMs) facilitate the creation of ‘Dialogue Simulations’ by generating text-based responses to user inputs, effectively modeling human conversational behavior. These simulations are not intended to replicate human consciousness, but rather to produce statistically plausible outputs based on the extensive datasets used in LLM training. By controlling the input prompts and parameters governing LLM response generation – such as temperature and top-p sampling – researchers can establish controlled experimental conditions. This allows for systematic manipulation of conversational scenarios and analysis of the resulting LLM-generated responses, providing a scalable method for investigating human-like interactions and decision-making processes without direct human subject involvement.
LLM Simulation, as employed in this research, utilizes the generative capabilities of the GPT-4.1 model to produce text-based responses to a range of complex prompts. This technique moves beyond simple question-answering by constructing simulated conversational environments where GPT-4.1 acts as a proxy for human interaction. The model receives detailed prompts designed to elicit specific behaviors or decision-making processes, and generates responses based on its training data and the nuances of the prompt itself. The resulting output is then analyzed to observe patterns and characteristics indicative of human-like cognitive processes, offering a scalable method for investigating behavioral dynamics.
Human-Likeness Prompt engineering significantly enhanced the realism of LLM-driven simulations by focusing on crafting prompts that elicit responses mirroring human conversational patterns and decision-making processes. This methodology involved incorporating nuanced linguistic cues and contextual information into the prompts provided to the GPT-4.1 model. Quantitative evaluation, specifically within budget allocation tasks, demonstrated a precision score of 0.685, indicating a substantial correlation between LLM-generated decisions and expected human responses under similar conditions. This precision metric was calculated by comparing the LLM’s resource distribution with a benchmark dataset of human allocations, assessing the degree of overlap and minimizing deviation from established human behavioral patterns.
Utilizing LLM-driven dialogue simulations enables a systematic investigation of cognitive biases by providing a controlled environment for observing decision-making processes. These simulations allow researchers to introduce specific conversational contexts and prompts designed to elicit biased responses, which are then quantifiable and analyzed. By repeatedly exposing the LLM to varied stimuli and recording its outputs, patterns of biased reasoning – such as anchoring, confirmation bias, or loss aversion – can be identified and their prevalence measured. This methodology moves beyond correlational studies, offering a mechanism to observe bias manifestation within the dynamic framework of interactive conversation and assess how these biases influence simulated behavioral outcomes.
Tracing the Fault Lines of Thought
Response Time Analysis was implemented to measure decision-making processes within simulated conversations by tracking the time taken to formulate responses. This metric served as an indicator of cognitive engagement and processing effort; deviations from baseline response times suggested increased cognitive load or a potential influence of bias. Specifically, longer response times may indicate greater deliberation or difficulty in processing information, while shorter times could signify impulsive decision-making or reliance on pre-existing biases. Data collected through this analysis provided quantifiable evidence of subtle cognitive shifts occurring during the simulations, enabling the assessment of bias influence on user behavior.
Recall tasks were integrated into the dialogue simulations to assess participant memory retention and comprehension of presented information. Following specific exchanges within the simulated conversations, participants were prompted with questions requiring them to accurately recall details discussed earlier. This methodology allowed for the measurement of how cognitive biases impacted not only immediate decision-making, but also the encoding and retrieval of information, providing a more comprehensive understanding of bias influence on cognitive processes. Data collected from these recall tasks were quantified and analyzed alongside response time and response length metrics to determine correlations and establish a holistic view of behavioral indicators related to bias.
Behavioral metrics derived from simulated conversations yielded quantifiable evidence of cognitive bias influence, achieving a precision of 0.667 across both investment decision-making and college job scenarios. This precision score indicates the proportion of correctly identified instances where cognitive bias demonstrably affected participant responses within the simulations. The measurement was based on comparisons between observed behavioral data – including response times and selections – and expected rational behavior in the given scenarios. This level of accuracy suggests the methodology effectively isolates and measures the impact of cognitive biases on decision processes within a controlled environment, providing a statistically significant basis for further research and analysis.
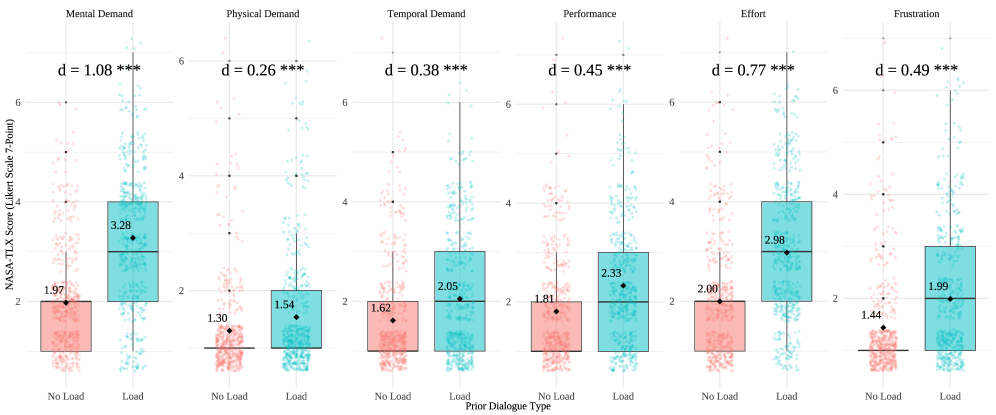
Cognitive load was intentionally increased within the dialogue simulations through the implementation of complex dialogue structures. This methodology aimed to heighten the influence of cognitive biases on decision-making processes. Statistical analysis revealed a Pearson’s correlation coefficient (r) of 0.396 between participant response time and response length. This indicates a moderate positive correlation; as the complexity of the dialogue increased, requiring greater cognitive effort, participants generally took longer to respond and provided longer responses, suggesting a measurable impact on processing speed and output volume.
![Under load, memory task accuracy is negatively correlated with mental demand and response time, as shown by the scatter plots with regression lines and [latex]95%[/latex] confidence intervals.](https://arxiv.org/html/2602.05597v1/x3.png)
The Inevitable Shadow of Imperfection
A cornerstone of this research was a commitment to data integrity, achieved through meticulous ‘Data Cleaning’ procedures applied throughout the study. This involved a systematic process of identifying and addressing inconsistencies, errors, and outliers within the datasets before any analysis commenced. Each step of the cleaning process – from handling missing values and correcting data entry mistakes to standardizing formats and resolving ambiguous cases – was thoroughly documented and reproducible. This rigorous approach not only ensured the reliability of the findings but also allowed for independent verification of the data transformations, bolstering confidence in the overall validity of the research and facilitating future meta-analyses or extensions of this work.
To facilitate rigorous scrutiny and collaborative advancement, all computational materials associated with this research-including source code, detailed simulation parameters, and the underlying raw data-have been deposited on the Open Science Framework. This open access approach not only allows for independent verification of the reported findings but also empowers other researchers to build upon this work, adapt the models to new contexts, and explore alternative hypotheses. By making these resources freely available, the study actively promotes a culture of transparency and reproducibility, essential for accelerating scientific progress and ensuring the reliability of computational models in cognitive science.
The research team prioritized an open science approach, making all code and data publicly available to ensure the reproducibility and verifiability of reported findings. This commitment yielded consistent results, notably the replication of medium effect sizes for Status Quo Bias – a cognitive tendency to prefer the current state of affairs – which closely mirrored observations from traditional human behavioral experiments. This successful replication not only validates the computational model’s accuracy but also demonstrates the potential for computational methods to provide robust and verifiable insights into human cognition, ultimately fostering collaborative advancements and accelerating the pace of discovery in the field.
The computational methods detailed within this research extend beyond the specific investigation of Status Quo Bias, offering a versatile framework for modeling a diverse array of cognitive processes. By simulating the underlying mechanisms of decision-making, these techniques provide valuable insights into human behavior applicable to the design of more intuitive and effective human-computer interactions. Furthermore, the ability to accurately model cognitive biases and limitations opens avenues for developing advanced decision support systems tailored to mitigate errors and enhance performance in complex environments, potentially impacting fields ranging from financial analysis to medical diagnosis and beyond. This adaptability underscores the broader utility of computational modeling as a powerful tool for understanding and ultimately improving the interplay between humans and technology.
![A forest plot displays effect sizes and their [latex]95%[/latex] confidence intervals for all models evaluated against human experimental data.](https://arxiv.org/html/2602.05597v1/x5.png)
The study’s success in modeling status quo bias within conversational agents isn’t merely a technical achievement; it’s a demonstration of inherent systemic predictability. These models don’t create bias, they faithfully reflect it. As John von Neumann observed, “The sciences do not try to explain why we exist, but how we exist.” This research echoes that sentiment – it doesn’t illuminate the origins of cognitive biases, but meticulously details how they manifest in interactions, revealing the underlying mechanisms with unsettling accuracy. The ability to simulate such deeply ingrained patterns suggests that monitoring isn’t about preventing failure, but about consciously fearing its inevitable expression. true resilience begins where certainty ends, and this work embraces that uncertainty by providing a means to anticipate, if not control, the echoes of human fallibility within these systems.
What Lies Ahead?
This work reveals a predictable truth: a system mirroring human choice will inevitably inherit human fallibility. The demonstrated reproduction of status quo bias isn’t a triumph of simulation, but a confirmation of inherent limitations. One does not build a rational actor; one cultivates a garden of predictable irrationalities. The question, then, isn’t whether these conversational agents can mimic bias, but what unforeseen consequences arise when such echoes are scaled. The propagation of these biases, embedded within systems presented as objective, demands a shift in focus.
Future work must abandon the pursuit of perfect fidelity to human decision-making, and instead explore the forgiveness of these systems. Resilience doesn’t lie in isolating components from error, but in designing for graceful degradation when predictable failures occur. Can one build conversational agents that actively unlearn bias, or at least flag its influence? The technical challenge isn’t merely reproduction, but controlled devolution.
Ultimately, this research highlights a fundamental principle: systems aren’t tools, they are ecosystems. Each line of code, each parameter adjusted, is a seed planted in fertile ground. One should anticipate not just the intended harvest, but the inevitable weeds. The true measure of success won’t be in mimicking human behavior, but in mitigating its most persistent flaws.
Original article: https://arxiv.org/pdf/2602.05597.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-07 19:44