Author: Denis Avetisyan
New research combines advanced AI techniques to create more human-like autonomous braking systems for safer navigation in complex urban environments.
![Semantic understanding fuels robotic reward: extracted predicates, when applied to linguistic rules, yield confidence values that directly modulate safety and efficiency weighting-as formalized in [latex]Equation 12[/latex]-allowing the system to prioritize task goals based on environmental interpretation.](https://arxiv.org/html/2602.05079v1/Figures/calculate_reward.jpg)
This study integrates hyperdimensional computing, semantic segmentation, and symbolic reasoning within a reinforcement learning framework to enhance autonomous driving safety and efficiency.
Despite advances in deep reinforcement learning, autonomous driving systems often struggle to integrate high-level contextual understanding and human values into decision-making. This is addressed in ‘Reinforcement Learning Enhancement Using Vector Semantic Representation and Symbolic Reasoning for Human-Centered Autonomous Emergency Braking’, which proposes a novel pipeline leveraging hyperdimensional computing, semantic segmentation, and symbolic reasoning to create a more robust and interpretable agent. By combining neuro-symbolic feature representations with a Soft First-Order Logic [latex]\mathcal{SFO}\mathcal{L}[/latex] reward function, the approach demonstrates improved safety and policy robustness in complex simulated urban environments. Could this integration of holistic representations and soft reasoning pave the way for truly context-aware and value-aligned autonomous systems?
Decoding Autonomy: Beyond Pattern Recognition
The pursuit of fully autonomous vehicles extends far beyond simply identifying objects like pedestrians, traffic lights, and other cars. True autonomy necessitates a sophisticated comprehension of intricate real-world scenarios, demanding systems that can interpret context, predict behavior, and reason about uncertainty. A vehicle must not only see a pedestrian approaching a crosswalk, but also assess their likely intent – are they looking at traffic, accelerating, or distracted? This requires moving beyond pattern recognition to embrace a more holistic understanding of the environment, factoring in variables like weather conditions, time of day, and even subtle cues in body language. Effectively navigating complex situations demands a system capable of integrating diverse data streams and making informed decisions based on probabilities, rather than relying solely on pre-programmed responses to specific, pre-defined events.
Despite remarkable advances, conventional deep learning systems exhibit limitations when deployed in real-world autonomous applications. While excelling at pattern recognition within training datasets, these approaches often struggle to generalize to novel situations or unexpected environmental factors. This fragility stems from their “black box” nature; the internal reasoning behind a decision remains opaque, hindering the ability to diagnose errors or ensure reliable performance outside of carefully curated conditions. Consequently, autonomous systems built on these foundations can be easily confused by unusual object orientations, partial occlusions, or unpredictable pedestrian actions, revealing a critical gap between performance in controlled settings and true robustness in unpredictable environments. Addressing this requires moving beyond mere pattern recognition towards systems capable of explicit reasoning and adaptable behavior.
Autonomous systems frequently encounter difficulties when visual data is incomplete – a phenomenon known as occlusion – or when confronted with the unpredictable actions of pedestrians. Current reliance on pattern recognition within deep learning frameworks proves insufficient in these instances, as the systems struggle to infer what lies behind an obstruction or to anticipate deviations from typical pedestrian movement. This limitation isn’t simply a matter of improving sensor resolution; it demands a shift towards more robust reasoning capabilities, allowing the system to build internal models of the environment and utilize contextual understanding to safely navigate ambiguous situations. Effectively addressing these challenges requires the development of algorithms that move beyond mere object detection and towards a more comprehensive, predictive awareness of the surrounding world, ultimately ensuring the reliable operation of autonomous vehicles in complex real-world scenarios.

HDC: Sculpting Intelligence from High Dimensions
Hyperdimensional Computing (HDC) is a computational paradigm modeled after the brain’s capacity for robust and efficient information processing. It represents data as high-dimensional vectors – typically with dimensions ranging from hundreds to thousands – where each element in the vector is a value within a defined range. This high dimensionality provides a vast address space, enabling the representation of a large number of distinct items and relationships. The use of high-dimensional vectors, coupled with mathematical operations like addition and similarity calculations, allows for fault tolerance and graceful degradation; minor perturbations in the vectors have a limited impact on overall performance. Furthermore, HDC’s vector-based approach lends itself to efficient parallel processing, contributing to its computational efficiency. The inherent properties of these vectors facilitate pattern completion and generalization, allowing systems to recognize and respond to incomplete or noisy inputs.
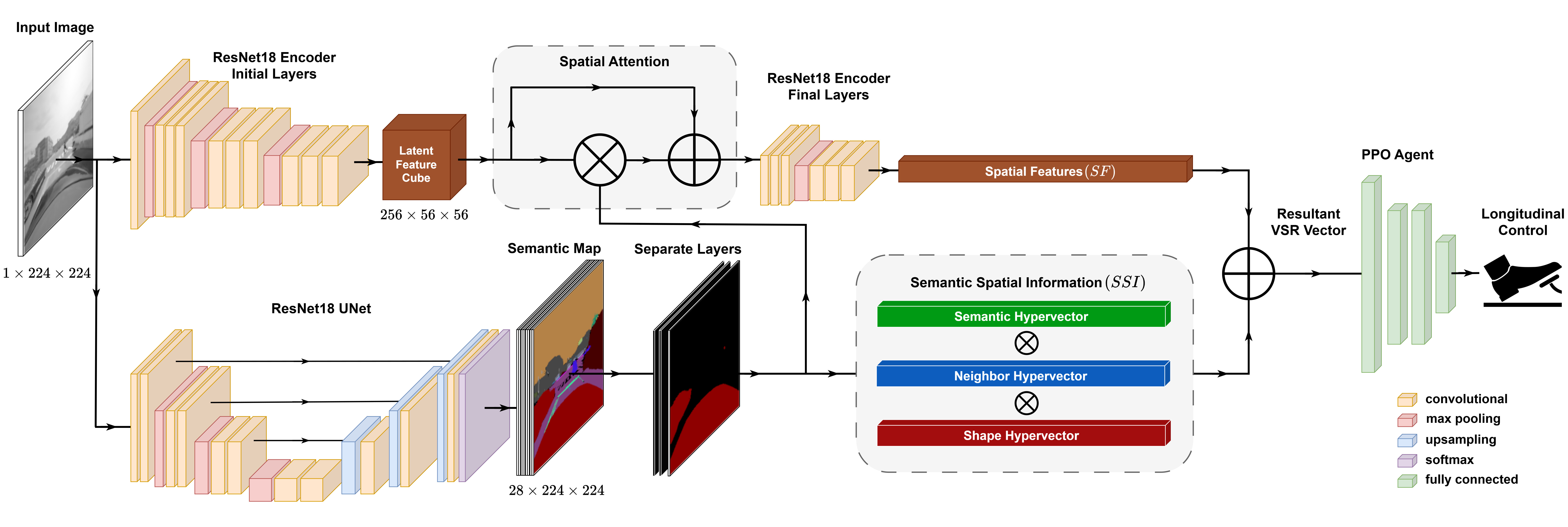
Vector Semantic Representation (VSR) is utilized to translate visual data from camera images into a high-dimensional vector space, leveraging the principles of Holographic Reduced Representation (HRR). This encoding process represents both spatial relationships – the positions and distances between objects – and semantic information, such as object categories and attributes. VSR achieves this by mapping image features into high-dimensional vectors, where similarity in vector space corresponds to similarity in the represented scene. HRR facilitates this mapping through a process of distributing information across the entire vector, enabling robust pattern recognition and efficient storage of complex spatial and semantic data derived from the camera imagery. The resulting high-dimensional vectors serve as a compact and informative representation of the scene’s structure and content.
Within Hyperdimensional Computing (HDC), the Binding and Bundling operations are fundamental to knowledge representation. Binding creates new, unique high-dimensional vectors representing relationships between items; this is achieved through element-wise multiplication of the vectors representing those items. Bundling, conversely, aggregates multiple vectors into a single, composite vector, typically via element-wise addition or averaging, preserving the information from each contributing vector. These operations allow the system to represent complex scenes by combining vectors representing individual objects and their spatial relationships, effectively creating a holistic representation of the environment and enabling reasoning about object interactions and scene context.
Spatial Attention mechanisms are integrated into the HDC encoding process to selectively prioritize informative regions within input images. This is achieved by weighting feature vectors derived from different image areas; regions deemed more relevant to spatial understanding – typically those containing objects or salient landmarks – receive higher weighting during the bundling operation. Consequently, the resulting high-dimensional vector representation more strongly encodes information from these attended regions, reducing the influence of irrelevant background noise and improving the accuracy of spatial encoding. This focused approach also enhances computational efficiency by reducing the dimensionality of effectively processed data, as less emphasis is placed on non-informative areas of the image.
Reinforcement Learning: Forging Intelligence Through Experience
Deep Reinforcement Learning (DRL) forms the core of the agent’s navigational training within complex driving simulations. The agent learns through trial and error, operating within a [latex] Markov Decision Process [/latex] (MDP) defined by states representing the driving environment, actions representing steering and acceleration commands, rewards quantifying driving performance, and transition probabilities dictating state changes based on agent actions. This framework allows the agent to iteratively refine its driving policy by maximizing cumulative rewards. The complexity of the driving scenarios necessitates the use of deep neural networks to approximate the optimal policy and value functions, enabling generalization to unseen situations and efficient handling of high-dimensional state spaces.
Proximal Policy Optimization (PPO) is employed as the primary algorithm for policy refinement within the agent’s decision-making process. PPO is a policy gradient method that iteratively improves the agent’s driving policy by taking small, constrained steps to maximize the expected cumulative reward. This constraint, enforced through a clipped surrogate objective function, prevents drastic policy updates that could lead to instability or unsafe behaviors. By limiting the policy change at each iteration, PPO ensures that the agent consistently learns to drive more efficiently and safely, avoiding potentially hazardous maneuvers while optimizing for desired driving characteristics such as speed and smoothness. The algorithm’s robustness and sample efficiency make it well-suited for training in complex, simulated driving environments.
The standard reward function utilized in reinforcement learning was augmented with principles of Soft First-Order Logic (SFO Logic) to facilitate high-level reasoning capabilities. This extension allows for the incorporation of symbolic knowledge and logical inferences into the reward signal. SFO Logic provides a differentiable approximation of first-order logic, enabling the agent to receive rewards not only for immediate actions but also for satisfying logical preconditions and achieving goals defined by spatial relationships and object properties. This approach moves beyond purely reactive behavior by enabling the agent to anticipate future states and make decisions based on a more comprehensive understanding of the environment, expressed as logical rules and constraints.
The agent’s capacity for anticipatory behavior stems from its ability to process spatial relationships and predict future states beyond immediate sensor data. This is achieved by encoding environmental features – such as the positions of other vehicles, lane markings, and traffic signals – into a spatial representation used for reasoning. The agent doesn’t solely rely on reactive responses to current stimuli; instead, it evaluates potential future scenarios based on these spatial relationships, allowing it to proactively adjust its actions to mitigate potential hazards like collisions or lane departures. This predictive capability extends beyond simple obstacle avoidance, enabling the agent to make informed decisions regarding route planning and maneuver selection based on a projected understanding of the environment.
Beyond Simulation: Towards Truly Intelligent Machines
Evaluations within the CARLA simulator reveal a significant advancement in pedestrian safety through this system’s performance in occluded crossing scenarios. Unlike traditional deep learning models, which often struggle with partially visible pedestrians, this approach consistently demonstrated improved detection and reaction times. The system’s ability to anticipate pedestrian movements, even when visibility is limited, resulted in a demonstrably lower collision rate and a more substantial success rate in safely navigating these challenging situations. This improvement isn’t merely statistical; it represents a crucial step towards building autonomous vehicles capable of handling the unpredictable realities of urban environments and prioritizing the safety of vulnerable road users.
The system’s enhanced performance stems from its utilization of Hierarchical Disentangled Composition (HDC), a technique allowing for more robust reasoning about spatial relationships within the driving environment. By disentangling elements like pedestrian location, vehicle trajectories, and static obstacles into distinct, hierarchical representations, the system avoids the ‘flat’ understanding common in traditional deep learning approaches. This enables it to better predict the behavior of other actors and navigate complex scenarios, particularly those involving occlusions or unpredictable movements. Consequently, the autonomous vehicle exhibits safer and more reliable behavior, demonstrating an improved capacity to anticipate potential hazards and react accordingly – a critical feature for real-world deployment and fostering trust in autonomous systems.
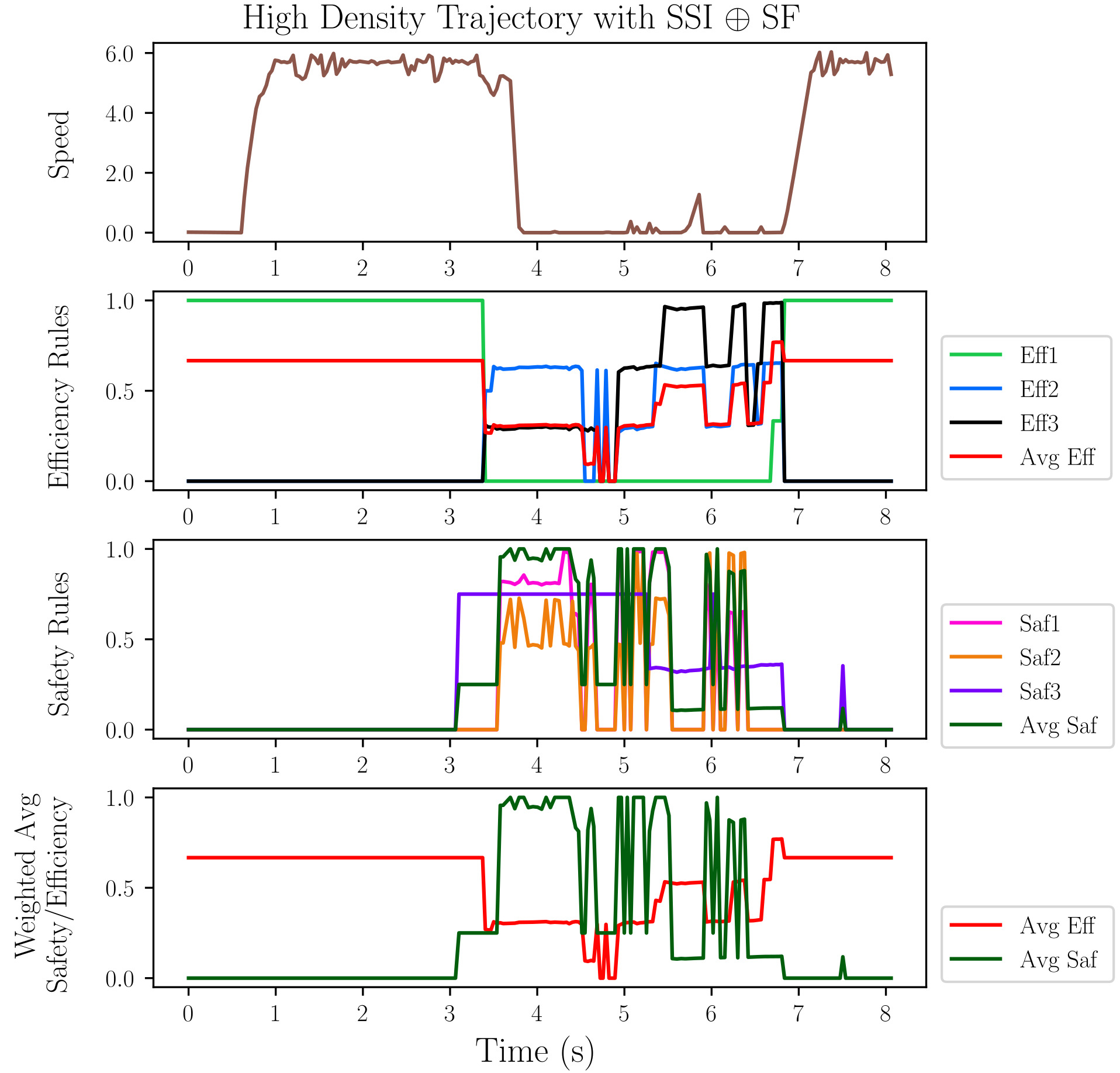
Evaluations within challenging, high-density traffic simulations reveal that the S_SI⊕S_F configuration demonstrably outperforms alternative system setups. This particular configuration achieved the highest success rate in navigating complex urban environments, successfully completing a greater percentage of trials without intervention. Critically, it also minimized collision rates, indicating a significantly improved level of safety compared to other tested arrangements. The robust performance suggests that the synergistic combination of Spatial Semantic Information and feature-based reasoning effectively addresses the core challenges presented by crowded traffic conditions, offering a pathway towards more reliable autonomous navigation in real-world scenarios.
The S_SI⊕S_F configuration not only maximized success rates and minimized collisions within the simulated environment, but also demonstrably improved the vehicle’s responsiveness. Specifically, testing revealed a minimized average stopping distance, suggesting a highly effective braking system capable of reacting swiftly to dynamic situations. This enhanced braking performance was reflected in the system’s training; the configuration consistently achieved a training reward of approximately 270, indicating a robust and efficient learning process that prioritized both safety and effective navigation within challenging traffic conditions. This combination of reduced stopping distance and high reward suggests a system poised for reliable performance in more complex real-world scenarios.
The autonomous driving system distinguishes itself not merely through performance metrics, but through a capacity for transparency in its decision-making process. By explicitly encoding spatial semantic information – the relationships between objects and their environment – the system moves beyond a ‘black box’ approach. This encoding allows for a reconstruction of the reasoning behind actions; for instance, the system can articulate why a pedestrian was identified as a potential collision risk based on their proximity to the vehicle’s path and the observed traffic signals. This inherent explainability is crucial for building trust in autonomous technology, facilitating debugging, and ultimately, ensuring safety, as it provides a clear audit trail of the system’s cognitive process and allows for verification of its logical reasoning.
Further development of this autonomous driving system prioritizes expansion beyond current simulations to encompass the unpredictable complexities of real-world environments. Researchers intend to test the system’s adaptability in scenarios featuring adverse weather conditions, dynamic pedestrian behavior, and intricate urban layouts. Crucially, this scaling effort will involve a multi-sensor integration strategy, combining data from cameras, lidar, radar, and potentially even vehicle-to-everything (V2X) communication. This fusion of sensor modalities aims to create a more robust and reliable perception system, enabling the vehicle to build a comprehensive understanding of its surroundings and ultimately achieve truly autonomous navigation – a system capable of safe and efficient operation in any situation.
The research meticulously dismantles the conventional approach to autonomous emergency braking, probing the limitations of purely data-driven reinforcement learning. It posits that true intelligence isn’t simply reacting to patterns, but understanding why those patterns exist. This echoes Andrey Kolmogorov’s sentiment: “The most important thing in science is not to be afraid of making mistakes.” The pipeline’s integration of symbolic reasoning, particularly its use of first-order logic, represents a deliberate attempt to ‘break the rule’ of relying solely on numerical representations. By explicitly modeling environmental constraints and object relationships, the system moves beyond pattern recognition toward a more robust and interpretable form of intelligence, addressing the core challenge of generalization in complex urban environments, and mirroring Kolmogorov’s emphasis on challenging established norms to advance understanding.
Pushing the Limits
The presented work, while demonstrating a compelling integration of hyperdimensional computing, semantic reasoning, and reinforcement learning, inevitably highlights the fragility of constructed intelligence. The system operates, demonstrably, within the bounds of its training-a comfortable illusion. The true test lies not in navigating pre-defined urban scenarios, but in confronting the deliberately anomalous, the genuinely unexpected edge case. One suspects that a sufficient influx of chaos-a pedestrian juggling flaming torches, perhaps-would swiftly reveal the limitations of even the most robust symbolic representation.
Future investigations should deliberately court such instability. The current reliance on semantic segmentation, while effective, implicitly assumes a world neatly divisible into labeled objects. But reality, as any seasoned driver knows, is awash in ambiguity-shadows, reflections, partially occluded objects, and the sheer unpredictability of human behavior. To truly understand autonomous braking, the system must be forced to grapple with incomplete, contradictory, and ultimately un-representable data.
The pursuit, then, isn’t simply about achieving higher accuracy rates in simulated environments. It’s about constructing a system that understands why it fails, and can adapt-not by refining its existing representations, but by fundamentally questioning its assumptions. If it cannot be broken, it is not understood. The real progress lies in engineering a controlled demolition of the very foundations upon which this intelligence rests.
Original article: https://arxiv.org/pdf/2602.05079.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-07 18:02