Author: Denis Avetisyan
A new framework uses iterative learning and shared skills to dramatically improve how multiple AI agents collaborate on complex tasks.
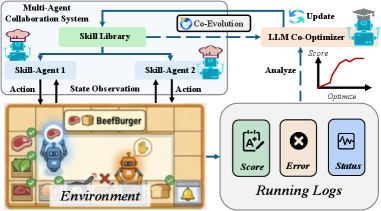
CoWork-X employs experience-optimized co-evolution with large language models and hierarchical task networks to enable sustained performance gains in multi-agent systems with minimal online computation.
Achieving both real-time coordination and sustained learning remains a key challenge in multi-agent systems driven by large language models. This paper introduces [latex]CoWork-X: Experience-Optimized Co-Evolution for Multi-Agent Collaboration System[/latex], a novel framework that casts collaborative task learning as a closed-loop optimization problem, enabling agents to iteratively refine a shared, interpretable skill library. Through active co-evolution and hierarchical task network (HTN)-based planning, CoWork-X achieves stable performance gains while minimizing online latency and token usage. Can this approach unlock more robust and efficient collaboration in complex, dynamic environments requiring continuous adaptation?
The Foundations of Collaborative Understanding
The promise of multi-agent systems-networks of autonomous entities working in concert-rests on a critical foundation: the ability of each agent to understand not just what others are doing, but why. Effective collaboration isn’t simply about coordinating actions; it demands a level of ‘theory of mind’ where agents can infer the intentions, knowledge, and potential future behaviors of their peers. This necessitates moving beyond simple reactive strategies to systems capable of building and maintaining models of other agents, predicting their responses, and adapting plans accordingly. Such reasoning about intentions and capabilities is particularly challenging in dynamic environments where agents may have incomplete information or conflicting goals, requiring sophisticated algorithms for belief updating, trust assessment, and strategic communication to achieve truly synergistic outcomes.
Conventional approaches to decentralized decision-making frequently falter when confronted with the inherent complexities of real-world scenarios. These methods, often reliant on pre-programmed rules or centralized coordination, struggle to adapt to the unpredictable nature of dynamic environments where information is incomplete and agents operate with limited perspectives. The combinatorial explosion of possible states and actions in such systems quickly overwhelms traditional algorithms, leading to computational bottlenecks and suboptimal outcomes. Furthermore, the lack of robust mechanisms for handling conflicting goals, unexpected events, or the evolving capabilities of other agents hinders effective collaboration. Consequently, research increasingly focuses on developing more flexible and scalable techniques – such as reinforcement learning and game theory – to enable agents to navigate these intricate challenges and achieve collective intelligence.
Achieving truly scalable collaborative intelligence demands simultaneous advancements in how individual agents think and how groups formulate plans. Current limitations in agent reasoning – the ability to accurately model environments, predict outcomes, and learn from experience – hinder effective teamwork, particularly as the number of collaborators increases. However, even with highly capable individual agents, a lack of robust collective strategy development can lead to inefficiencies and suboptimal outcomes. Simply increasing processing power isn’t enough; researchers are actively exploring methods for agents to dynamically adapt to each other’s strengths and weaknesses, negotiate shared goals, and coordinate actions in complex, unpredictable settings. This involves developing new algorithms for decentralized decision-making, communication protocols that minimize ambiguity, and mechanisms for resolving conflicts – all critical for unlocking the full potential of multi-agent systems and realizing genuinely intelligent collaboration at scale.
![The CoWork-X system iteratively improves its skill agent’s performance by executing hierarchical task network (HTN) policies, diagnosing execution logs with a large language model, and then refining the policy [latex]\mathcal{S}_k \to \mathcal{S}_{k+1}[/latex] with added preconditions.](https://arxiv.org/html/2602.05004v1/x2.png)
CoWork-X: An Evolving Ecosystem of Collaboration
CoWork-X utilizes an active co-evolution strategy wherein multiple agents concurrently learn and adapt through repeated interactions spanning numerous episodes. This process differs from traditional reinforcement learning by emphasizing reciprocal learning; agents do not operate in a static environment but instead influence each other’s learning trajectories. The system continuously evaluates agent performance across these episodes, using the resulting data to drive iterative improvements in individual agent policies and the shared skill library. This sustained interaction allows agents to discover novel strategies and refine existing skills in response to the evolving capabilities of their peers, fostering a dynamic and emergent learning process.
The CoWork-X framework operates on an iterative ‘Execution-Optimize Loop’. During the execution phase, agents utilize skills currently available within the system’s skill library to attempt task completion. Performance data generated from these executions – including success rates, efficiency metrics, and observed failure modes – are then fed back into the optimization phase. The Co-Optimizer analyzes this data and dynamically refines the skill library through techniques such as skill composition, parameter adjustment, and the introduction of novel skills. This continuous cycle of execution and optimization enables the system to adapt and improve its capabilities over time, facilitating increasingly effective task performance across multiple episodes.
Skill-Agents within the CoWork-X framework utilize a structured Skill Library as the foundational component for task execution. This library contains a catalog of defined skills, each representing a specific action or procedure. The Co-Optimizer module continuously monitors the performance of these skills during agent interactions and employs the resulting data to dynamically update the Skill Library. Updates include modifications to existing skill parameters, the addition of novel skills derived from successful behaviors, and the removal of ineffective or redundant skills. This iterative refinement process ensures the Skill Library remains current and optimized for improved agent performance across multiple episodes and varying task demands.
Hierarchical Skill Representation and Dynamic Refinement
CoWork-X employs Hierarchical Task Network (HTN) planning to structure its skill library. HTN planning defines skills not as primitive actions, but as methods composed of sub-tasks, allowing complex behaviors to be built from reusable components. This hierarchical decomposition enables flexible task planning; a single high-level skill can be adapted to varying situations by altering the decomposition of its sub-tasks. Furthermore, the HTN representation facilitates skill reuse across different tasks and environments, reducing redundancy and improving overall system efficiency by leveraging common sub-task sequences.
The CoWork-X system employs a ‘Co-Optimizer’ which utilizes Large Language Models (LLMs) for automated skill refinement. Specifically, GPT-5.1, Gemini-3-Pro-Preview, Claude-4.5, and DeepSeek-v3.2 are leveraged to analyze data from completed episodes, or ‘episode logs’. This analysis focuses on identifying instances where existing skills performed sub-optimally or failed to achieve desired outcomes. The LLMs extract actionable insights from these logs, pinpointing areas within existing skills requiring modification or highlighting the need for entirely new skill development. This process allows for continuous improvement of the skill library without manual intervention.
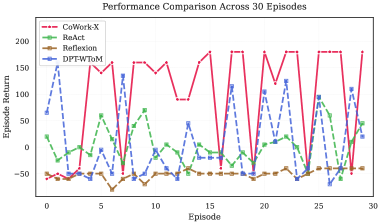
The CoWork-X skill library undergoes continuous refinement based on performance data collected from episode logs. This dynamic process analyzes task execution to identify opportunities for skill improvement, ensuring the library adapts to changing environments and task demands. Empirical results demonstrate a mean return of 96.3% across a substantial dataset of 3030 episodes, indicating sustained performance gains attributable to this iterative refinement strategy. This ongoing optimization contributes to the library’s long-term relevance and effectiveness in complex task execution scenarios.
![CoWork-X demonstrates significantly improved resource efficiency, achieving a score rate of [latex]0.92[/latex] per second and [latex]5.9[/latex] per 1,000 tokens, compared to DPT-WToM’s [latex]0.09[/latex] and [latex]0.20[/latex] respectively.](https://arxiv.org/html/2602.05004v1/x4.png)
Elevating Collaboration Through Reflexion and Theory of Mind
The CoWork-X framework introduces a novel approach to agent collaboration through the integration of ‘Reflexion’, a mechanism enabling agents to critically assess their past actions and learn from planning errors. Unlike traditional systems that simply execute plans, CoWork-X agents actively analyze outcomes, identify deficiencies in their strategies, and refine subsequent behavior – effectively ‘reflecting’ on their performance. This self-improvement process is powerfully augmented by Large Language Models, which provide the reasoning capabilities necessary to not only pinpoint the cause of errors, but also to generate improved plans for future scenarios. By combining retrospective analysis with generative planning, CoWork-X fosters a cycle of continuous learning, allowing agents to adapt and optimize their collaborative strategies over time and achieve increasingly complex objectives.
The CoWork-X framework introduces ‘DPT-Agents’ – a novel approach to multi-agent collaboration founded on the principles of ‘Theory of Mind’. These agents don’t simply react to observed actions; instead, they actively construct models of their teammates’ beliefs, intentions, and potential plans. By reasoning about what a teammate might do, and why, DPT-Agents can proactively anticipate future actions, coordinate efforts more effectively, and resolve conflicts before they escalate. This capability moves beyond simple reactive behavior, enabling agents to engage in genuinely collaborative problem-solving, effectively simulating the nuanced understanding inherent in successful human teamwork and achieving synergistic outcomes impossible for isolated agents.
The CoWork-X framework demonstrably elevates collaborative potential, allowing agents to surmount challenges that would prove insurmountable for solitary operation. This enhanced teamwork isn’t achieved at the cost of efficiency; the system maintains remarkably low online latency – a mere 2.6 seconds per episode – ensuring real-time responsiveness. Crucially, this performance is attained without incurring in-episode Large Language Model (LLM) token usage, representing a significant reduction in computational demand and cost. By skillfully integrating reflection and Theory of Mind-equipped agents, the framework unlocks a new paradigm for complex problem-solving, prioritizing both ambitious goal achievement and practical operational constraints.
Scaling Collaborative Intelligence: Future Directions
CoWork-X represents a significant step toward creating truly collaborative artificial intelligence through the synergistic combination of three key elements. Active co-evolution allows agents to learn and adapt with, rather than simply against, their partners, fostering a dynamic where both improve over time. This is underpinned by Hierarchical Task Network (HTN) skill representation, which provides a structured and understandable framework for defining and sharing capabilities. Crucially, teammate modeling allows agents to anticipate the actions and intentions of their collaborators, enabling more efficient coordination and proactive assistance. This integrated approach moves beyond simple task allocation, creating a system where agents can genuinely work together to solve complex problems, offering a scalable pathway toward increasingly intelligent and effective multi-agent teams.
Future investigations will center on incorporating Population-Based Training (PBT) into the CoWork-X framework, a technique designed to significantly expand the diversity of collaborative partners and bolster the system’s resilience. PBT operates by maintaining a population of agents that continuously learn and evolve through self-play and occasional knowledge sharing; this approach allows the system to move beyond reliance on a single, pre-defined teammate and adapt effectively to a wider range of collaborative styles and skill levels. By continually evaluating and refining its population of agents, the system will become less vulnerable to specific partner weaknesses and more capable of maintaining high performance even in unpredictable or challenging collaborative scenarios, ultimately fostering a more robust and adaptable collaborative intelligence.
The CoWork-X framework is intentionally structured as a collection of independent, interoperable modules, a design choice that facilitates its expansion and adaptation. This modularity isn’t merely architectural; it actively invites the incorporation of cutting-edge techniques from diverse fields, such as advanced reinforcement learning algorithms, novel methods for handling partial observability, and more complex communication protocols. By decoupling core functionalities – like teammate modeling and hierarchical task network (HTN) planning – from the overall system, researchers can readily substitute or augment existing components without requiring a complete overhaul. This streamlined integration process promises to accelerate the development of increasingly sophisticated multi-agent systems capable of tackling complex, real-world challenges, and positions CoWork-X as a versatile platform for ongoing innovation in collaborative intelligence.
The pursuit of robust multi-agent collaboration, as demonstrated by CoWork-X, necessitates a holistic view of system design. The framework’s iterative refinement of a shared skill library, leveraging large language models, embodies the principle that structure dictates behavior. Andrey Kolmogorov observed, “The most important things are the ones you don’t measure.” This sentiment resonates deeply with CoWork-X; while the system focuses on quantifiable performance improvements through active co-evolution and HTN planning, the true strength lies in fostering a collaborative process-an emergent property not easily captured by metrics alone. The elegance of CoWork-X isn’t merely in its technical implementation, but in its capacity to build a self-improving system from minimal online computation, highlighting the value of inherent adaptability.
Future Directions
The pursuit of genuinely collaborative multi-agent systems inevitably circles back to the question of shared understanding. CoWork-X offers a compelling mechanism for evolving such understanding – a skill library refined through iterative experience. However, the framework currently treats skills as discrete units, neglecting the inherent fluidity of action and the potential for compositional generalization. Future work must address how to represent skill relationships – the tacit knowledge of when, why, and how skills blend and morph in response to novel situations.
A further limitation lies in the reliance on LLMs as both the architects and evaluators of skill refinement. This introduces a potential for circularity – the system optimizing towards what the LLM believes constitutes effective collaboration, rather than objectively measuring emergent behavior within a complex environment. The true test will be to decouple evaluation from the generative model, perhaps through the introduction of adversarial agents or intrinsically motivated reward signals.
Ultimately, the elegance of a collaborative system is not found in the sophistication of its planning algorithms, but in the simplicity of its boundaries. CoWork-X provides a scaffold for building these boundaries. The next step is to explore how to distribute agency – how to allow individual agents to not merely execute skills, but to contribute to the evolving library itself, thereby shifting from a system of collaboration to a system of collective intelligence.
Original article: https://arxiv.org/pdf/2602.05004.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-07 16:21