Author: Denis Avetisyan
A new framework leverages the power of artificial intelligence to streamline scientific workflows and accelerate research in complex fields like catalysis.
This paper details a cloud-based, multi-agent system using Large Language Models to automate experimentation and integrate diverse tools for scientific discovery.
While Large Language Models demonstrate promise across scientific disciplines, their inherent limitations in executing complex tasks and accessing external resources hinder full research potential. To address this, we present ‘A Cloud-based Multi-Agentic Workflow for Science’, detailing a domain-agnostic framework leveraging a cloud-native, multi-agent system to automate scientific workflows-integrating tools from literature review to simulation. This system achieves [latex]90\%[/latex] task routing accuracy and successfully completes [latex]97.5\%[/latex] of synthetic tasks, alongside competitive performance on real-world benchmarks, demonstrating its viability as a scalable scientific assistant. Could this approach unlock new levels of automation and accelerate discovery across diverse scientific domains?
Beyond Automation: Towards Agentic Scientific Discovery
Historically, scientific advancement has been significantly constrained by the laborious processes of data preparation and initial hypothesis formulation. Researchers often spend considerable time cleaning, organizing, and interpreting raw data – tasks that, while essential, divert attention from actual discovery. This manual curation isn’t merely time-consuming; it introduces potential for human error and inherent biases in data selection. Moreover, the generation of testable hypotheses frequently relies on expert intuition and existing literature, potentially overlooking novel connections or unexplored avenues of inquiry. The cumulative effect of these bottlenecks slows the pace of scientific progress, limiting the number of experiments that can be designed, executed, and analyzed within a given timeframe and creating a significant need for automated and intelligent solutions to streamline these crucial early stages of research.
Despite the remarkable capacity of Large Language Models (LLMs) to process information beyond textual data-analyzing images, interpreting sensor readings, and even formulating initial hypotheses-their core architecture presents limitations when tackling the nuanced demands of scientific discovery. LLMs excel at pattern recognition and correlation, but struggle with causal inference, counterfactual reasoning, and the iterative refinement of ideas crucial for robust scientific investigation. Consequently, a shift towards ‘agentic’ systems is becoming essential-frameworks where LLMs are integrated with tools for experimentation, simulation, and data analysis, allowing them to independently formulate research questions, design experiments, interpret results, and refine hypotheses in a closed loop. This structured approach aims to overcome the inherent limitations of LLMs, transforming them from powerful information processors into proactive, autonomous scientific investigators capable of accelerating the pace of discovery.
Modern scientific inquiry increasingly relies on the convergence of disparate data – genomic sequences, sensor readings, simulation outputs, and published literature – yet current analytical methods often falter when attempting to synthesize these diverse inputs. Existing pipelines typically require substantial manual effort to harmonize data formats, resolve inconsistencies, and bridge semantic gaps between tools designed for specific modalities. This fragmentation hinders a truly holistic analysis, limiting the ability to uncover complex relationships and emergent phenomena. Consequently, researchers face bottlenecks in translating raw data into actionable insights, and the potential for groundbreaking discoveries remains unrealized as comprehensive understanding is perpetually out of reach. A more integrated and automated approach is crucial to unlock the full value of these multifaceted datasets and accelerate the pace of scientific progress.
Orchestrating Discovery: A Multi-Agent Architecture
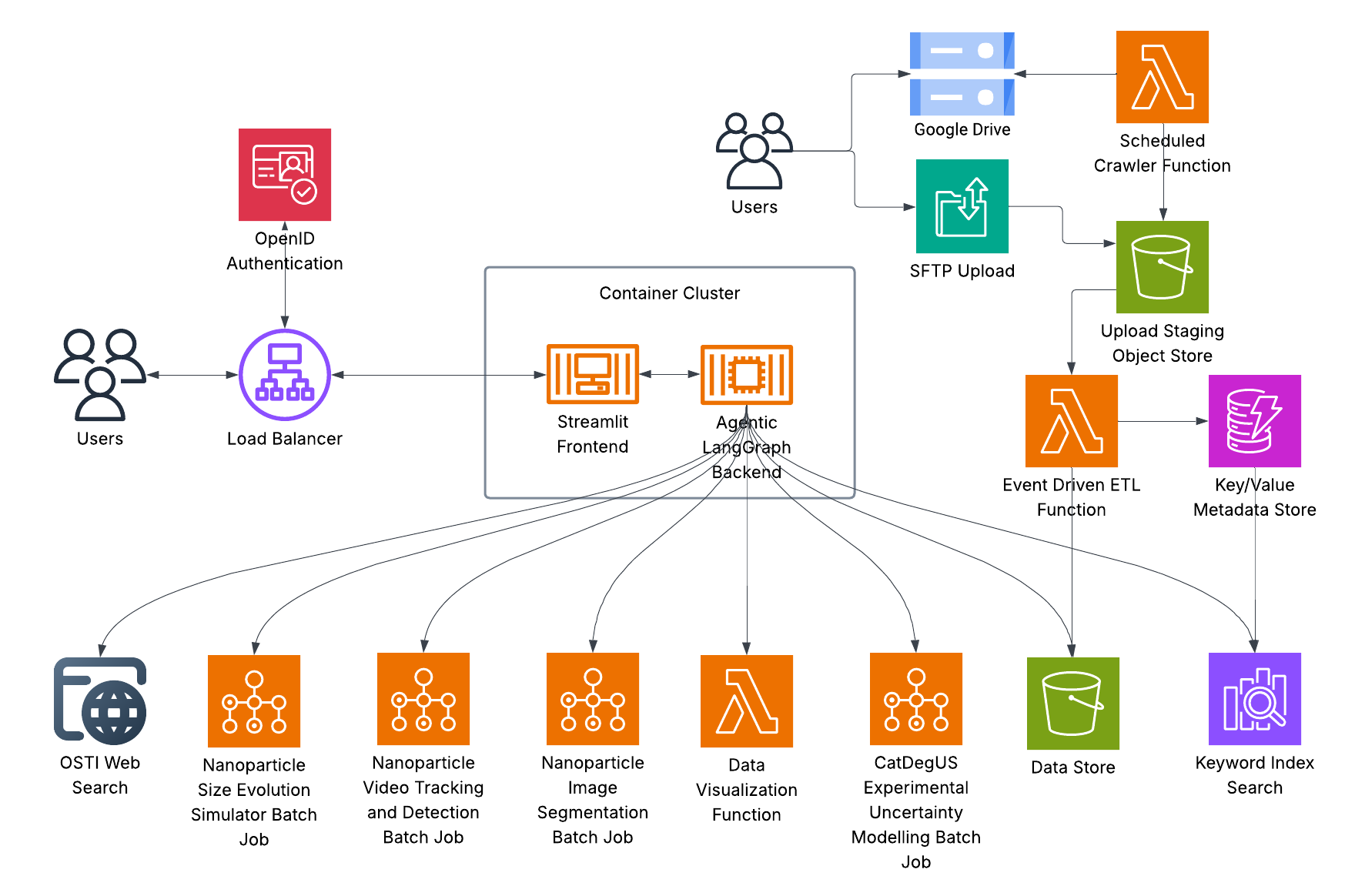
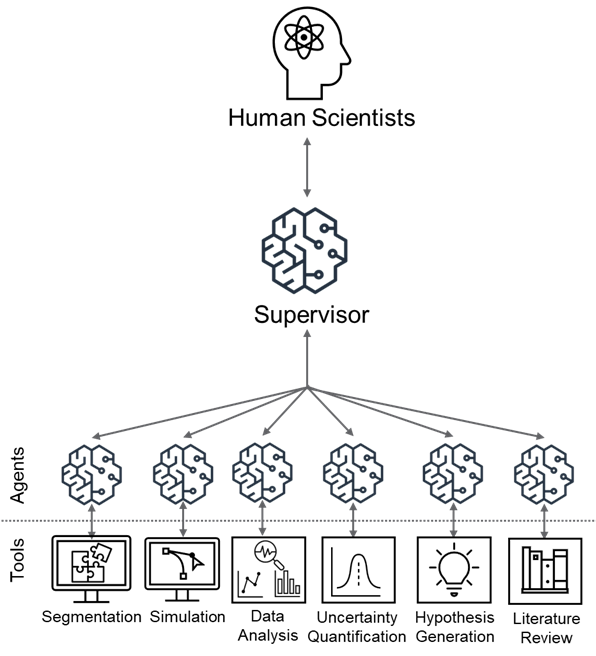
The Multi-agent Framework utilizes a distributed problem-solving approach by assigning specific subtasks to individual Large Language Model (LLM) Agents. This delegation is central to the system’s functionality, allowing each agent to focus its processing capabilities on a narrowed scope of the overall problem. Rather than a single LLM attempting to address the entire challenge, the framework decomposes it into manageable components, increasing efficiency and accuracy. Agents operate autonomously within their assigned tasks, contributing their results to a centralized coordinator for aggregation and final solution formulation. This modular design promotes parallel processing and facilitates the integration of specialized LLMs optimized for particular task types.
The Supervisor Agent functions as the core component of the multi-agent framework, responsible for directing the overall problem-solving process. It receives initial requests, decomposes them into sub-tasks, and assigns these tasks to specialized LLM Agents based on their defined capabilities. Communication between agents is mediated by the Supervisor, which collects results from individual agents, consolidates findings, and manages data flow. This centralized control ensures coherent operation and prevents conflicting outputs, while also enabling the Supervisor to monitor progress, handle errors, and dynamically adjust task assignments to optimize performance. The agent also manages the overall workflow, ensuring tasks are completed in the correct sequence and that dependencies are met.
The framework’s modular design enables the addition or removal of LLM Agents without disrupting the overall system functionality. This scalability is achieved through a defined communication protocol managed by the Supervisor Agent, which allows for the dynamic allocation of tasks to specialized agents based on available resources and task requirements. Integration of diverse tools and data sources is facilitated by standard API connectors and a data-agnostic input/output format, permitting agents to access and process information from various external systems, including databases, web services, and file storage. Consequently, the architecture supports incremental expansion and adaptation to evolving data landscapes and computational demands.
Specialized Agents: From Data Acquisition to Hypothesis Formulation
The Literature Review Agent utilizes the Office of Scientific and Technical Information (OSTI) Application Programming Interface (API) to automate the collection and curation of scientific publications relevant to specified research areas. This API access allows for programmatic searching and retrieval of metadata and, where available, full-text documents from the OSTI collection, which includes research funded by the U.S. Department of Energy. The agent filters results based on keywords, author names, publication dates, and other criteria, constructing a focused knowledge base. This automated process significantly reduces the manual effort required for comprehensive literature reviews and ensures access to a broad range of peer-reviewed research, facilitating informed decision-making in subsequent analysis and hypothesis generation.
The Data Analysis Agent is responsible for processing and interpreting datasets to uncover statistically significant patterns. It employs Pydantic, a Python library, to rigorously validate incoming data, ensuring data types and structures conform to predefined schemas before analysis. This validation step minimizes errors and ensures data integrity. Following validation, the agent performs exploratory data analysis (EDA) utilizing techniques such as descriptive statistics, data visualization, and correlation analysis. The primary objective of this EDA is to identify key trends, outliers, and relationships within the data, which are then communicated to the Hypothesis Generation Agent to inform the formulation of testable hypotheses. The agent outputs these trends as structured data, facilitating automated hypothesis construction.
The Simulation Agent employs computational modeling to investigate complex catalytic processes, with a specific focus on understanding nanoparticle behavior under varying conditions. This agent utilizes numerical methods to simulate reaction kinetics, mass transport phenomena, and nanoparticle interactions. To ensure consistent and reliable results, the agent is containerized using Docker, which packages the simulation software, dependencies, and configurations into a standardized unit. This containerization guarantees reproducibility across different computing environments, enabling independent verification of simulation outcomes and facilitating collaborative research. Simulation outputs provide data-driven insights into nanoparticle dynamics, including aggregation, sintering, and catalytic activity, informing the development of more efficient catalytic materials.
The Hypothesis Generation Agent functions as a central integration point for data-driven discovery. It receives processed data and insights from the Literature Review, Data Analysis, and Simulation Agents. Specifically, it leverages curated publications, identified trends, and modeled process behaviors to construct potential hypotheses. These hypotheses are formulated to be testable through further experimentation or analysis, and are output with associated supporting evidence derived from the contributing agents. The agent prioritizes hypotheses based on the strength of supporting data and the novelty of the proposed relationship, facilitating targeted investigation of promising research directions.
Validation and Deployment: Catalysis and Beyond
The framework’s capabilities are powerfully illustrated through its successful application to the field of catalysis, a notoriously complex area of chemical research. Catalysis demands a holistic analytical approach, requiring the simultaneous consideration of reaction mechanisms, electronic structures, and thermodynamic properties – a challenge perfectly suited to the framework’s multi-faceted design. By effectively integrating diverse data sources and employing a hierarchical reasoning process, the system navigates the intricacies of catalytic systems with notable precision. This demonstration highlights not only the framework’s technical prowess but also its potential to accelerate discovery within a field critically important for sustainable chemistry and materials science, offering a versatile tool for researchers seeking to understand and optimize catalytic processes.
Rigorous evaluation of the framework’s capabilities was conducted using ChembBench, a challenging benchmark for chemical reasoning tasks. This assessment demonstrated a high degree of functionality, with the system achieving a 90.49% task completion rate – indicating its ability to successfully address a wide range of problems. Furthermore, the framework exhibited a 61% correctness rate, positioning its performance as competitive with, and in some instances exceeding, that of currently established state-of-the-art models in the field. These results highlight the framework’s potential as a reliable and effective tool for complex chemical analysis and prediction, suggesting a significant advancement in automated scientific reasoning.
Researchers can readily engage with the developed framework through an intuitive interface constructed with Streamlit and FastAPI. This design prioritizes accessibility, enabling scientists to effortlessly input queries and analyze the generated results without requiring extensive programming expertise. The interface facilitates a seamless exploration of the framework’s capabilities, fostering broader adoption and collaborative investigation within the scientific community. By abstracting away the complexities of the underlying multi-agent system, it empowers researchers to focus on scientific inquiry rather than technical implementation, ultimately accelerating discovery and innovation.
The framework’s multi-agent system benefits significantly from the implementation of LangGraph, a tool designed to manage complex interactions and dependencies between agents. This hierarchical coordination isn’t merely about organizing tasks; it fundamentally improves the system’s ability to scale to more intricate problems and maintain reliable performance. By structuring agents into a defined hierarchy, LangGraph allows for efficient information flow and prevents the communication bottlenecks common in large multi-agent systems. This approach also enhances robustness, as failures in one part of the hierarchy are less likely to cascade and disrupt the entire process, ensuring consistent and accurate results even with increased complexity and computational demands.
Towards a Future of Agentic Scientific Inquiry
The system’s architecture is intentionally built upon a modular framework, enabling seamless incorporation of novel agents and analytical tools as scientific demands shift. This design prioritizes adaptability, allowing researchers to readily update or expand the system’s capabilities without requiring substantial code revisions or systemic overhauls. New agents, specializing in tasks from literature review to data visualization, can be integrated with minimal disruption, and existing tools can be easily swapped or upgraded. Such flexibility ensures the framework remains relevant and effective across diverse scientific disciplines and throughout the rapidly evolving landscape of research technologies, ultimately fostering a sustainable and scalable platform for accelerated discovery.
Continued development centers on elevating the agents’ capacity for complex reasoning and integrating advanced data analytics methodologies. Current efforts explore techniques such as neuro-symbolic AI, allowing the agents to combine the strengths of neural networks – pattern recognition – with symbolic reasoning – logical deduction. This will enable not just data retrieval, but also hypothesis generation and experimental design refinement. Furthermore, the incorporation of techniques like Bayesian inference and causal modeling promises to move beyond correlation to uncover underlying mechanisms, fostering a deeper understanding of scientific phenomena and accelerating the pace of reliable discovery. These enhancements are projected to significantly improve the agents’ ability to tackle increasingly complex scientific challenges and contribute to more nuanced and insightful analyses.
The system demonstrated a high degree of success in directing information to the appropriate agent, achieving 90% routing accuracy across all implemented agents. This indicates a robust capacity for discerning relevant data and efficiently allocating tasks within the framework. While the majority of agents performed at this elevated level, the Simulation agent currently achieves 75% accuracy; ongoing development is focused on optimizing its performance to align with the system-wide standard. This strong routing capability is critical for ensuring the overall efficiency and reliability of the agentic workflow, allowing for automated and accurate processing of scientific information.
Maintaining the agentic system requires an estimated monthly expenditure of 1,500 USD, a figure largely driven by the costs associated with the keyword index. This index, which facilitates efficient information retrieval and agent routing, currently accounts for approximately 50% of the total operational budget. While substantial, this cost is considered reasonable given the scale of data processed and the potential for accelerating scientific discovery. Ongoing optimization of the keyword index, alongside exploration of more cost-effective data storage solutions, are key areas of focus for future development, aiming to minimize operational expenses without compromising system performance or accuracy.
The implementation of agentic systems in scientific research promises a fundamental shift in how discovery unfolds across numerous fields. By autonomously managing tasks like literature review, data analysis, and even hypothesis generation, these agents circumvent traditional bottlenecks and enable researchers to focus on higher-level interpretation and creative problem-solving. This distributed, task-oriented approach doesn’t merely automate existing processes; it facilitates exploration of broader parameter spaces and identification of non-obvious connections within complex datasets. The potential extends beyond individual labs, offering a scalable framework for collaborative research and accelerated innovation, ultimately reshaping the scientific landscape by fostering a more dynamic and efficient cycle of inquiry and advancement.
The pursuit of automated scientific workflows, as detailed in this work, demands a relentless focus on foundational principles. It recalls David Hilbert’s assertion: “We must be able to answer the question: what are the logical prerequisites for doing mathematics?” This framework, leveraging LLM agents and cloud computing, isn’t merely about assembling tools; it’s about establishing a rigorous, logically sound system for catalysis research. The multi-agent system, by breaking down complex experimentation into discrete, manageable steps, echoes Hilbert’s emphasis on formalization. Each agent functions as an axiom, contributing to a provable chain of discovery, and reducing the inherent ambiguity in scientific exploration. The aim is not simply to accelerate research, but to ground it in demonstrable, reproducible logic.
What Lies Ahead?
The presented framework, while demonstrating a functional confluence of Large Language Models and scientific workflow, merely scratches the surface of a considerably more profound challenge. Automation, in this context, is not the ultimate goal, but a necessary prelude to true cognitive assistance. The current iteration addresses the ‘how’ of experimentation-orchestrating tools and data-but remains largely silent on the ‘why’. A future system will not simply execute a prescribed protocol, but actively refine it, proposing alternatives based on nuanced interpretations of incomplete data and acknowledging the inherent uncertainty of the physical world.
The reliance on explicit prompt engineering, a temporary scaffolding for interaction, represents a significant limitation. A truly adaptable system must internalize domain knowledge-not as static facts, but as probabilistic relationships-and generate hypotheses autonomously. The pursuit of ‘general’ scientific agents is a distraction; specialization, coupled with robust mechanisms for inter-agent communication, offers a more pragmatic path forward. The elegance of a solution is often inversely proportional to its complexity; the true test will lie in stripping away unnecessary features, leaving only the essential core.
Ultimately, the value of such systems will not be measured in experiments completed, but in questions asked. The framework should serve as a catalyst for curiosity, a tool that amplifies the researcher’s intuition, and, perhaps most importantly, identifies the limitations of its own knowledge. The disappearance of the author, in this case the explicit programmer, is not an endpoint, but a continuous refinement toward an objective truth.
Original article: https://arxiv.org/pdf/2601.12607.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-22 04:53