Author: Denis Avetisyan
A new review examines how large language models are being used to automate and improve the creation of software documentation and modeling.
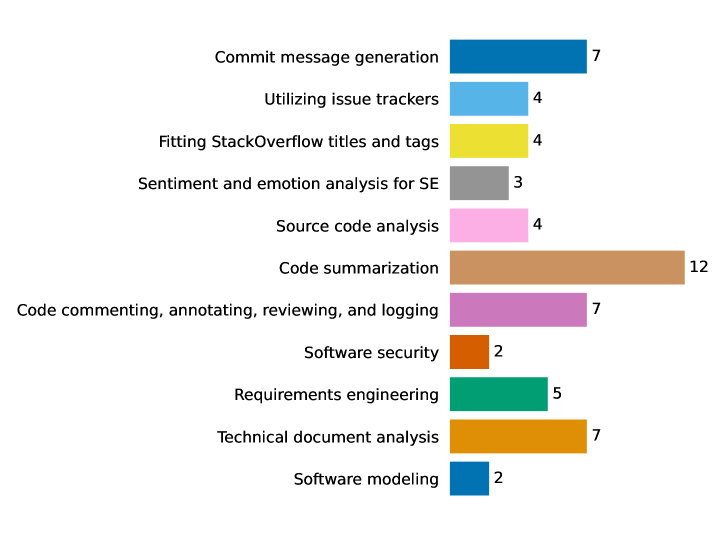
This systematic literature review of 57 studies assesses the current state of large language model applications in software engineering, focusing on code summarization, documentation, and prompt engineering techniques.
Despite considerable excitement surrounding generative artificial intelligence, its transformative impact on established software engineering practices remains an open question. This paper, ‘Large Language Models in Software Documentation and Modeling: A Literature Review and Findings’, systematically reviews 57 studies exploring the application of large language models (LLMs) to tasks involving software documentation and modeling. Our analysis reveals that while LLMs demonstrate potential for improving existing workflows-particularly in areas like code summarization-they haven’t yet fundamentally reshaped the field. As LLMs become increasingly integrated into software development, what further innovations in prompt engineering and evaluation metrics will be necessary to unlock their full capabilities?
The Inevitable Complexity of Modern Software
Contemporary software engineering faces escalating challenges stemming from system complexity, a consequence of increasing feature demands, intricate architectures, and the rapid pace of technological change. Traditional methodologies, while foundational, often prove insufficient in managing this complexity, leading to project delays, budget overruns, and diminished software quality. The sheer volume of code, coupled with the need for constant updates and integrations, creates a cognitive burden on developers, hindering innovation and increasing the risk of errors. This situation necessitates a shift towards more automated, intelligent, and adaptive approaches – techniques capable of handling the scale and dynamism inherent in modern software development. The current limitations of established practices are driving exploration into novel paradigms, seeking solutions that can streamline processes, enhance reliability, and ultimately, deliver software more efficiently.
Large Language Models are poised to redefine software engineering practices, moving beyond incremental improvements to offer a fundamental shift in how software is conceived, developed, and maintained. This transformation stems from their capacity to automate traditionally manual tasks throughout the entire Software Development Life Cycle – from requirements elicitation and code generation to testing, debugging, and documentation. LLMs aren’t simply tools to accelerate existing processes; they introduce the potential for intelligent automation, capable of understanding complex software designs, identifying potential vulnerabilities, and even suggesting optimal solutions. This offers the prospect of significantly reduced development times, improved software quality, and lowered barriers to entry for aspiring developers, ultimately promising a more agile and innovative software landscape.
A comprehensive analysis of 57 research papers reveals the critical need for systematic investigation into the true capabilities of Large Language Models (LLMs) when applied to software engineering tasks. This rigorous examination demonstrates that simply introducing LLMs into the Software Development Life Cycle is insufficient; a nuanced understanding of their strengths and limitations is paramount. The studies highlight the necessity of evaluating LLMs not just on general language proficiency, but specifically on their performance in code generation, bug detection, documentation, and other software-specific applications. Such detailed analysis is foundational for unlocking the full potential of LLMs and ensuring their responsible and effective integration into practical software engineering workflows, moving beyond hype to evidence-based implementation.
Automated Documentation: A Necessary Foundation
Software documentation is a foundational element of the software development lifecycle, yet consistently receives insufficient attention. This neglect results in substantial maintenance burdens due to increased time spent understanding undocumented or poorly documented codebases. These burdens manifest as higher debugging costs, slower onboarding for new developers, and increased risk of introducing errors during modifications. The lack of current documentation directly impacts long-term project viability and scalability, as understanding the original intent and functionality becomes increasingly difficult over time. Comprehensive and maintained documentation is, therefore, not merely a best practice, but a critical component of responsible software engineering and cost-effective maintenance.
Code summarization utilizes Large Language Models (LLMs) to automatically generate natural language descriptions of source code. This process analyzes code structure and content to produce documentation that explains the code’s functionality, intended purpose, and key algorithms. By automating documentation creation, organizations can significantly reduce the manual effort and associated costs of maintaining up-to-date and accurate documentation. Improved code comprehension, facilitated by these summaries, also benefits developers during onboarding, code review, and maintenance tasks, ultimately decreasing development time and enhancing software quality.
Evaluation of automatically generated code summaries relies on established natural language processing metrics. BLEU (Bilingual Evaluation Understudy) assesses n-gram overlap with reference summaries, while ROUGE (Recall-Oriented Understudy for Gisting Evaluation) focuses on recall of n-grams, longest common subsequences, and skip-bigrams. Side Metric, a more recent addition, measures semantic similarity by comparing the embeddings of generated and reference summaries. A comprehensive analysis of 57 research papers demonstrates a consistent trend: Large Language Models (LLMs) are increasingly integrated into code summarization workflows, resulting in measurable improvements across these evaluation metrics and indicating enhanced utility of automated documentation tools.
Streamlining Issue Tracking Through Intelligent Automation
Effective issue tracking is a fundamental component of software project management, requiring the identification, categorization, prioritization, and assignment of tasks related to bugs, feature requests, and technical debt. However, performing these steps manually presents significant challenges, particularly as project scale and complexity increase. Manual categorization is prone to inconsistencies and requires substantial time investment from engineering and project management personnel. Prioritization, often based on subjective assessments or limited data, can lead to delays in addressing critical issues. This manual effort detracts from core development activities and can negatively impact project timelines and overall software quality. Consequently, organizations are increasingly exploring automated solutions to streamline issue management processes.
The integration of Large Language Models (LLMs), such as GPT-4, into issue tracking systems automates the categorization and prioritization of reported issues. This automation reduces the manual effort previously required for issue triage, thereby streamlining the software development workflow. By leveraging LLMs to analyze issue descriptions, systems can assign relevant labels, severity levels, and assignees with increased efficiency and consistency. This accelerated processing contributes to faster resolution times and improved project management, allowing development teams to focus on coding rather than administrative tasks related to issue organization.
Large Language Models (LLMs) are being utilized to improve developer collaboration on platforms like StackOverflow through tools such as SOTitle+ and PTM4Tag+. These tools employ models like CodeT5 to automatically generate post titles and tags, aiming to increase the discoverability and relevance of information shared within the developer community. Importantly, all research analyzed regarding the development and evaluation of these LLM-powered tools is fully funded by the EU NextGenerationEU initiative, indicating a focused European investment in enhancing software development workflows and knowledge sharing.
The Validation Imperative: Rigorous Evaluation of LLM4SE
Effective version control relies heavily on commit messages, yet the practice of crafting informative and descriptive messages is frequently underestimated in software development. These messages serve as a project’s historical record, enabling developers to understand the rationale behind changes, facilitating debugging, and simplifying collaboration. While code alterations are meticulously tracked, poorly written or absent commit messages create a significant knowledge gap, hindering future maintainability and increasing the cost of software evolution. Consequently, automated approaches to commit message generation are gaining traction, aiming to bridge this gap and promote a more sustainable and understandable codebase by providing concise summaries of the implemented changes.
Automated commit message generation increasingly relies on large language models, with systems like CommitBART, KADEL, and OMEGA representing prominent approaches to this challenge. These models are specifically designed to analyze code changes and synthesize concise, informative commit messages, aiming to improve software development workflows. Performance is commonly benchmarked using datasets such as the MCMD (Mining Commit Message Dataset), which provides a standardized collection of code diffs paired with corresponding human-written commit messages. This allows researchers to quantitatively assess the quality of generated messages, focusing on aspects like semantic similarity and information coverage, and facilitates iterative improvements in these automated systems.
Effective validation of Large Language Models for Software Engineering (LLM4SE) necessitates a multifaceted evaluation strategy, extending beyond simple algorithmic accuracy. While automated metrics – such as BERTScore, which assesses semantic similarity, and sentiment analysis, gauging the tone of generated commit messages – provide quantifiable data, they often fail to capture nuanced aspects of practical utility. Consequently, robust evaluations consistently incorporate human assessment, where developers directly review generated outputs for clarity, conciseness, and overall helpfulness in the version control workflow. This combined approach ensures that LLM4SE tools not only produce technically correct outputs, but also genuinely enhance developer experience and are readily adopted into existing software development practices, bridging the gap between research innovation and real-world impact.
Charting the Future: Dissemination and Evolution of LLM4SE
The rapidly evolving field of Large Language Models for Software Engineering (LLM4SE) is gaining significant traction within the academic community, evidenced by a growing body of peer-reviewed publications. Research in this area is not merely exploratory; it’s actively disseminated through highly respected and selective journals, including IEEE Transactions on Software Engineering, ACM Transactions on Software Engineering and Methodology, and Springer Empirical Software Engineering. This presence in leading venues signals a maturation of the field, moving beyond initial experimentation towards rigorous validation and established scholarly contribution, attracting increased attention from both researchers and industry professionals seeking to leverage the potential of LLMs throughout the software development process.
A comprehensive systematic literature review proves critical for navigating the rapidly evolving landscape of Large Language Models in Software Engineering (LLM4SE). This analytical process distills insights from a substantial body of work – currently encompassing 57 peer-reviewed papers – to reveal prevailing themes and pinpoint emerging trends. Such reviews move beyond simple summaries, instead synthesizing fragmented findings into a cohesive understanding of LLM4SE’s current state. By meticulously examining existing research, gaps in knowledge become apparent, and directions for future innovation are clearly illuminated, fostering more focused and impactful research efforts within the field. The review’s findings offer a valuable resource for both established researchers and newcomers seeking to understand and contribute to the advancement of LLM-driven software engineering practices.
The trajectory of research on Large Language Models for Software Engineering (LLM4SE) points toward a concentrated effort to overcome current limitations and bolster model dependability. Future studies are anticipated to prioritize enhancing robustness against adversarial inputs and variations in code style, alongside tackling challenges like hallucination and ensuring the ethical implications of LLM-generated code are thoroughly addressed. Beyond refinement, innovation will likely center on extending LLM applications throughout the entire Software Development Life Cycle – from automated requirements elicitation and design to code generation, testing, debugging, and even deployment and maintenance – promising a transformative impact on software creation processes and potentially unlocking entirely new paradigms for software engineering.
The systematic review highlights a crucial point: current applications of Large Language Models in software engineering, while demonstrating utility, largely refine existing practices rather than instigate fundamental shifts. This observation resonates with Marvin Minsky’s assertion: “The more we learn about computation, the more we realize how little we know about thinking.” The pursuit of automating software documentation and modeling with LLMs, as evidenced by the 57 studies analyzed, isn’t about replicating intelligence, but about enhancing computational processes. The focus remains firmly on provable algorithms and scalable solutions – a pursuit of correctness, rather than a simulation of understanding. The limitations revealed in the literature underscore that true innovation lies not simply in generating outputs, but in establishing a firm theoretical foundation for these systems.
What Remains to Be Proven?
The systematic exploration of Large Language Models within software engineering, as evidenced by this review of 57 studies, reveals a curious state of affairs. The observed improvements in documentation and modeling are, undeniably, improvements. However, the field remains stubbornly resistant to any claim of fundamental transformation. The algorithms function; rigorous proof of their correctness, or even formal guarantees of reliability, remains largely absent. The current reliance on empirical evaluation-that is, ‘it works on these tests’-is a precarious foundation for any engineering discipline predicated on precision.
Future investigation must shift from merely demonstrating capability to establishing provable properties. The focus should not be on generating more fluent summaries, but on formally verifying the consistency between code, documentation, and the models themselves. Can a language model guarantee the absence of semantic drift between implementation and description? Until such questions are addressed with mathematical rigor, the promise of these models will remain just that-a promise, elegantly expressed, but lacking in formal justification.
Ultimately, the true test lies not in automating existing workflows, but in enabling the creation of software systems with demonstrably higher levels of correctness and maintainability. The field requires a move beyond statistical approximation and towards a more axiomatic approach – a demand for provability, not merely plausibility.
Original article: https://arxiv.org/pdf/2602.04938.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-07 06:55