Author: Denis Avetisyan
New research reveals a significant gap between AI performance on standard benchmarks and its ability to handle complex, real-world tasks in 3D environments.
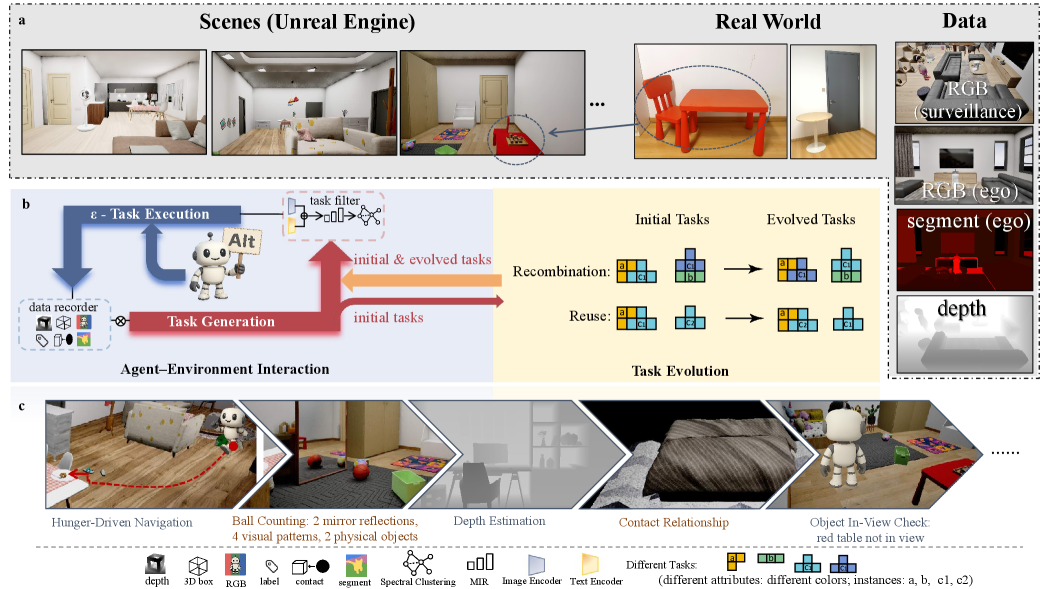
A framework for automatically generating graph-structured tasks within Unreal Engine demonstrates that current state-of-the-art vision-language models struggle with in-situ evaluation.
Despite advances in artificial intelligence, evaluating embodied agents in genuinely novel environments remains a critical challenge, often hampered by contaminated benchmarks and a lack of scene specificity. This limitation motivates the work ‘Automatic Cognitive Task Generation for In-Situ Evaluation of Embodied Agents’, which introduces a system for dynamically generating realistic cognitive tasks within unseen 3D spaces, inspired by human cognition. Experiments reveal that state-of-the-art models, despite strong performance on existing benchmarks, surprisingly struggle with basic perception and 3D interaction in these in-situ evaluations. These findings underscore the urgent need for robust, environment-specific evaluation protocols-but can we truly bridge the gap between benchmark success and real-world deployment?
The Illusion of Evaluation: Why Current Benchmarks Fail Embodied AI
The difficulty in assessing embodied artificial intelligence stems from the sheer scale of potential scenarios an agent might encounter. Unlike traditional AI systems operating within constrained datasets, an embodied agent – a robot or virtual body – must navigate and interact with endlessly variable environments. Each new space presents a unique combination of objects, layouts, and physical properties, and the number of possible tasks – from simple object retrieval to complex multi-step plans – quickly becomes astronomical. This combinatorial explosion makes it impractical to exhaustively test an agent’s capabilities, necessitating the development of robust evaluation metrics and strategies that can generalize beyond the specific scenarios presented during training. Consequently, determining true intelligence in embodied agents requires moving beyond narrow benchmarks and towards measures that reflect adaptability, resilience, and genuine understanding of the physical world.
Current methods for assessing embodied artificial intelligence frequently produce misleading results due to inherent flaws in evaluation benchmarks. A significant issue is data contamination, where information from the test environments inadvertently leaks into the training data, artificially inflating performance scores. Beyond this, many benchmarks lack the necessary diversity in scenarios, objects, and agent interactions, failing to adequately challenge an agent’s generalization capabilities. Consequently, reported metrics often overestimate an agent’s true proficiency in novel, real-world situations, creating a disconnect between laboratory success and practical application. This reliance on flawed benchmarks hinders progress, as improvements measured within these limited contexts may not translate to robust, adaptable intelligence when deployed outside controlled settings.
A significant obstacle to deploying embodied artificial intelligence in the real world lies in the persistent discrepancy between simulated training grounds and the complexities of authentic environments – a phenomenon known as the ‘Domain Gap’. While agents can achieve impressive performance within meticulously crafted simulations, these virtual worlds often fail to fully capture the unpredictable nuances of reality, such as variations in lighting, friction, sensor noise, or unexpected object interactions. Consequently, skills honed in simulation frequently exhibit diminished or failed transfer when deployed in the physical world, necessitating costly and time-consuming adaptation or retraining. Bridging this gap demands innovative approaches, including domain randomization – deliberately varying simulation parameters to expose agents to a wider range of conditions – and techniques like domain adaptation, which aim to align the feature spaces of simulation and reality, ultimately fostering more robust and generalizable embodied intelligence.
![Across ten scenes, our method consistently enhances task diversity as demonstrated by a statistically significant improvement in mean intersection rate (MIR) compared to four other visual language models ([latex]p<0.01[/latex], [latex]p<0.001[/latex]).](https://arxiv.org/html/2602.05249v1/x4.png)
Dynamic Challenge: The TEA Framework for Robust Evaluation
The TEA Framework employs a two-stage system for automated task generation for embodied agents, consisting of an interaction stage and an evolution stage. The interaction stage uses agent-environment feedback to assess current agent capabilities and environmental features, informing the creation of initial tasks. Subsequently, the evolution stage utilizes methods to refine and diversify these tasks, generating more complex challenges through techniques like task recombination and reuse. This iterative process allows the framework to dynamically create tasks tailored to the agent’s learning progress and the specific environment, facilitating robust evaluation in a variety of scenarios.
The TEA Framework utilizes agent-environment interaction as a core mechanism for dynamic task generation. This involves continuously assessing the agent’s performance and the characteristics of the surrounding 3D environment to inform the creation of new tasks. Specifically, the agent’s current capabilities – including successful and unsuccessful actions, learned skills, and areas of weakness – are analyzed. Simultaneously, the framework evaluates environmental features such as object positions, room layouts, and available affordances. This combined assessment allows the system to generate tasks that are appropriately challenging given the agent’s skill level and relevant to the specific environmental context, ensuring a targeted and adaptive evaluation process.
Task Evolution within the TEA Framework utilizes methods such as Task Recombination and Task Reuse to generate progressively more challenging scenarios for embodied agents. Task Recombination involves combining elements from existing tasks – altering object placements, goal locations, or required actions – to create novel task instances. Task Reuse focuses on adapting previously successful tasks to new environments or agent states, increasing the complexity by introducing variations in conditions. These methods avoid simply increasing the number of task components; instead, they focus on intelligently modifying and extending existing tasks to produce a wider range of challenges and assess the agent’s generalization capabilities.
The TEA Framework successfully generated 87,876 unique tasks within previously unexplored 3D environments. This automated task generation process yielded a measurable improvement in task diversity compared to existing methodologies. The quantity of generated tasks facilitates more comprehensive and robust evaluation of embodied agents, allowing for assessment across a wider range of scenarios and challenges. This scale of task generation is critical for addressing the limitations of hand-crafted task suites and promoting generalization capabilities in agents operating in complex, real-world settings.
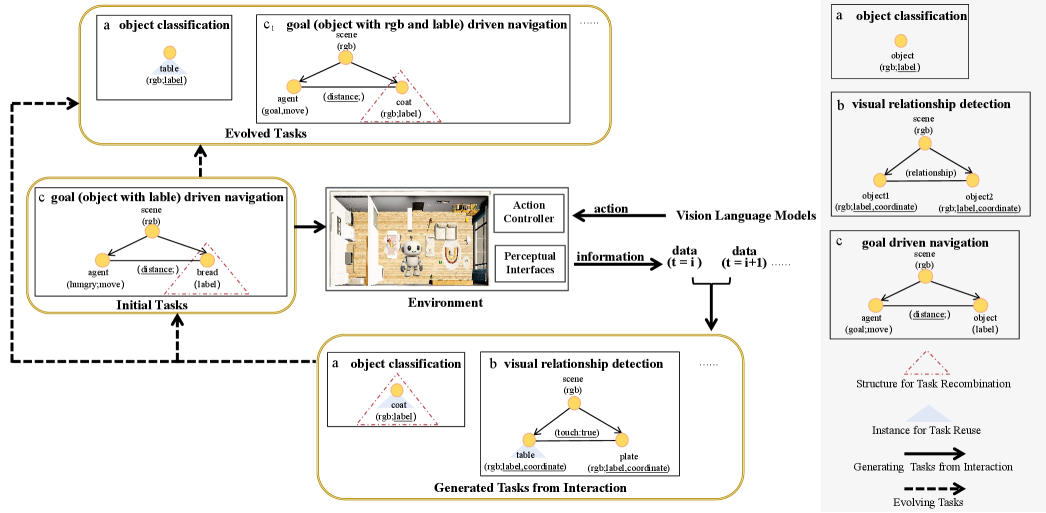
Graph-structured tasks within the TEA Framework represent task dependencies and relationships as a graph, where nodes define individual sub-tasks and edges denote sequential or conditional relationships between them. This allows for the creation of complex, multi-step tasks that extend beyond simple sequential instructions; for example, a task might require an agent to locate object A before attempting to manipulate object B, a dependency explicitly represented in the graph. The graph structure facilitates task decomposition and recombination, enabling the automated generation of diverse challenges by rearranging or extending existing task graphs. Furthermore, this representation supports variations in task complexity, allowing for the creation of tasks with varying numbers of steps and conditional branches, ultimately enhancing the robustness of embodied agent evaluation.
Measuring the Untestable: Quantifying Diversity and Comprehensive Evaluation
The TEA Framework utilizes spatial statistics and the Maximum Independent Ratio (MIR) as metrics to assess the distribution and diversity of tasks within generated task sets. MIR quantifies the dissimilarity between tasks, with higher values indicating greater diversity; the framework achieves an average MIR of 0.75 when evaluating evolved tasks across different scenes and models. This quantitative approach ensures comprehensive evaluation by verifying that generated tasks are not overly redundant and cover a broad range of spatial arrangements and required agent behaviors, providing a statistically grounded measure of task set quality.
The TEA framework is designed to accommodate a diverse set of tasks crucial for comprehensive agent evaluation. These include ‘Embodied Counting’, requiring agents to enumerate objects within a scene; ‘Object Localization’, focusing on precise object identification by spatial coordinates; ‘Relationship Detection’, which assesses the ability to recognize connections between objects; ‘Navigation’, testing pathfinding and movement skills; ‘Object Classification’, evaluating the categorization of observed items; and ‘Object In-View Check’, verifying the agent’s ability to determine if specific objects are within its field of vision. This task diversity ensures a robust assessment of agent capabilities beyond single-skill performance.
The initial task set generated by the TEA framework exhibited a high degree of diversity, as quantified by the Maximum Independent Ratio (MIR). Assessment using GPT-4o yielded an average MIR score exceeding 0.8, indicating substantial independence between the tasks and suggesting comprehensive coverage of the intended skill space. This high MIR value was calculated based on the semantic similarity between task descriptions, with lower similarity scores contributing to a higher overall ratio and confirming the creation of a varied and challenging evaluation suite. The metric provides an objective measure of task distribution, ensuring that the evaluation process does not disproportionately favor performance on a limited subset of skills.
The Task Execution Arena (TEA) framework utilizes Unreal Engine as its core simulation environment, enabling the creation of high-fidelity 3D scenes for agent evaluation. This implementation provides physically realistic rendering, dynamic lighting, and accurate physics simulation, all crucial for assessing agent performance in embodied AI tasks. Unreal Engine’s capabilities allow for complex scene construction, diverse object placement, and the simulation of sensor data – including RGB images and depth maps – which are then used as input for the evaluated agents. The engine’s robust tooling also facilitates programmatic control of the environment, enabling automated task generation, data collection, and systematic evaluation of agent behaviors across a range of scenarios.
The evaluation process within the TEA framework leverages the capabilities of GPT-4o for both task generation and analytical assessment. Comparative analysis utilizing GPT-4o has demonstrated a significant performance disparity between human performance and current models on fundamental perception tasks; specifically, models exhibit a performance gap exceeding 0.7 when benchmarked against human capabilities in these areas. This metric highlights the challenges remaining in achieving human-level perception for embodied agents and informs further development and evaluation strategies.
![Tasks are categorized based on their operational dimension-either [latex]2D[/latex] images or [latex]3D[/latex] physical space-and the level of cognitive demand, ranging from basic perception to complex reasoning and decision-making.](https://arxiv.org/html/2602.05249v1/x3.png)
Beyond the Illusion: Towards Truly Generalizable Embodied Intelligence
Current evaluation benchmarks for embodied artificial intelligence often produce deceptively high performance scores due to inherent limitations in task diversity and environmental complexity. The TEA (Task, Environment, and Agent) framework directly addresses this challenge by systematically identifying and mitigating sources of inflated metrics. Unlike traditional methods that rely on narrowly defined scenarios, TEA promotes the generation of a broad spectrum of tasks, varying in difficulty and requiring diverse skill sets. Crucially, the framework also emphasizes the creation of realistic and challenging environments, incorporating factors like sensor noise, imperfect actuators, and dynamic obstacles. This comprehensive approach ensures a more rigorous and reliable assessment of an agent’s true capabilities, moving beyond superficial success in contrived settings and fostering the development of genuinely robust and generalizable embodied intelligence.
The pursuit of truly intelligent embodied agents hinges not simply on mastering individual tasks, but on adapting to unforeseen challenges – a capability significantly enhanced by the TEA framework. This system actively encourages the design of increasingly diverse and complex scenarios, moving beyond the limitations of narrowly defined benchmarks. By forcing agents to confront a broader spectrum of situations, the framework compels developers to prioritize generalization and robustness over rote memorization of specific solutions. Consequently, the resulting agents exhibit improved performance not just within the training environment, but also when faced with novel conditions or unexpected disturbances – a critical step towards deploying reliable AI in the unpredictable real world. This emphasis on adaptability fundamentally shifts the focus from achieving high scores on limited tests to fostering genuinely intelligent behavior.
The TEA framework offers a significant advancement in embodied AI evaluation through its scalable and automated capabilities. Rather than relying on manually designed benchmarks, the system dynamically generates a diverse array of environments and tasks, allowing for comprehensive testing of agent performance across a broad spectrum of conditions. This automation isn’t merely about efficiency; it’s about uncovering vulnerabilities and limitations that might remain hidden in curated datasets. By systematically varying factors like object placement, lighting, and task complexity, the system can push agents beyond their training parameters and reveal their true generalization capabilities. The resulting data provides a granular understanding of an agent’s strengths and weaknesses, facilitating targeted improvements and accelerating the development of truly robust and adaptable embodied intelligence.
A significant hurdle in deploying embodied artificial intelligence lies in the disparity between controlled simulation environments and the unpredictable nature of the real world. Current training often yields agents proficient within the simulation, yet falter when confronted with even slight variations in lighting, texture, or unforeseen obstacles. This research addresses this ‘reality gap’ through a systematic evaluation framework designed to expose agents to increasingly complex and diverse scenarios. By rigorously testing performance across a spectrum of conditions – from idealized simulations to more realistic, noisy environments – the approach identifies vulnerabilities and guides the development of more robust and adaptable agents. Consequently, this work isn’t simply about achieving high scores in a virtual space; it’s about building the foundation for AI systems capable of navigating and interacting with the complexities of the physical world, ultimately accelerating the translation of laboratory advancements into practical, real-world applications.
The pursuit of robust embodied agents necessitates a shift in evaluation paradigms. This work, detailing automatic cognitive task generation, reveals a troubling disconnect between performance on curated benchmarks and genuine in-situ capability. It seems the systems, despite appearing proficient, are merely navigating predictable landscapes. As Linus Torvalds once observed, “Talk is cheap. Show me the code.” The generated tasks, born from complex graph structures and VLMs, demand more than superficial intelligence; they require agents to adapt within dynamic, unpredictable environments. Every dependency on pre-defined success metrics is a promise made to the past, and these agents, when faced with true novelty, often find those promises unfulfilled. The cycle continues: build, test, reveal limitations, and begin again.
The Road Ahead
The proliferation of benchmarks, however meticulously constructed, offers only the appearance of progress. This work demonstrates that performance on contrived evaluations bears diminishing correlation with competence in genuine environments. The observed fragility of state-of-the-art embodied agents, when confronted with automatically generated tasks, isn’t a failing of the algorithms themselves, but a predictable consequence of simplifying the world into solvable abstractions. A guarantee of success, even within a defined simulation, is merely a contract with probability; the real world rarely adheres to such terms.
Future effort will not be spent chasing incremental gains on existing metrics. The challenge lies in shifting the focus from building agents to growing systems. Task generation, therefore, isn’t an end in itself, but a tool for cultivating increasingly complex and unpredictable environments. The goal isn’t to create agents that solve tasks, but systems that respond to them – adapting, evolving, and occasionally failing with a degree of graceful degradation.
Stability is merely an illusion that caches well. The inherent chaos of real-world interaction isn’t a bug to be eliminated, but nature’s syntax. The next generation of research must embrace this complexity, accepting that the most interesting outcomes will emerge not from control, but from the careful orchestration of emergent behavior.
Original article: https://arxiv.org/pdf/2602.05249.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-06 23:22