Author: Denis Avetisyan
Researchers have developed a new AI framework that mimics human perception by actively seeking out information to improve its ability to manipulate objects in complex environments.
The CoMe-VLA framework formalizes active perception as a non-Markovian decision process, leveraging large-scale human egocentric data to drive information gain and robust manipulation.
Achieving truly generalizable robotic manipulation requires proactive information seeking, yet current active perception methods struggle with the complexity of real-world environments. This limitation motivates the work ‘Act, Sense, Act: Learning Non-Markovian Active Perception Strategies from Large-Scale Egocentric Human Data’, which formalizes active perception as a non-Markovian process and introduces CoMe-VLA-a cognitive and memory-aware vision-language-action framework trained on large-scale human egocentric data. By learning from human demonstrations and integrating proprioceptive and visual contexts, CoMe-VLA demonstrates robust performance across diverse long-horizon tasks. Could this approach pave the way for robots that learn to explore and manipulate the world with human-level adaptability and foresight?
The Illusion of Control: Why Robots Struggle to See
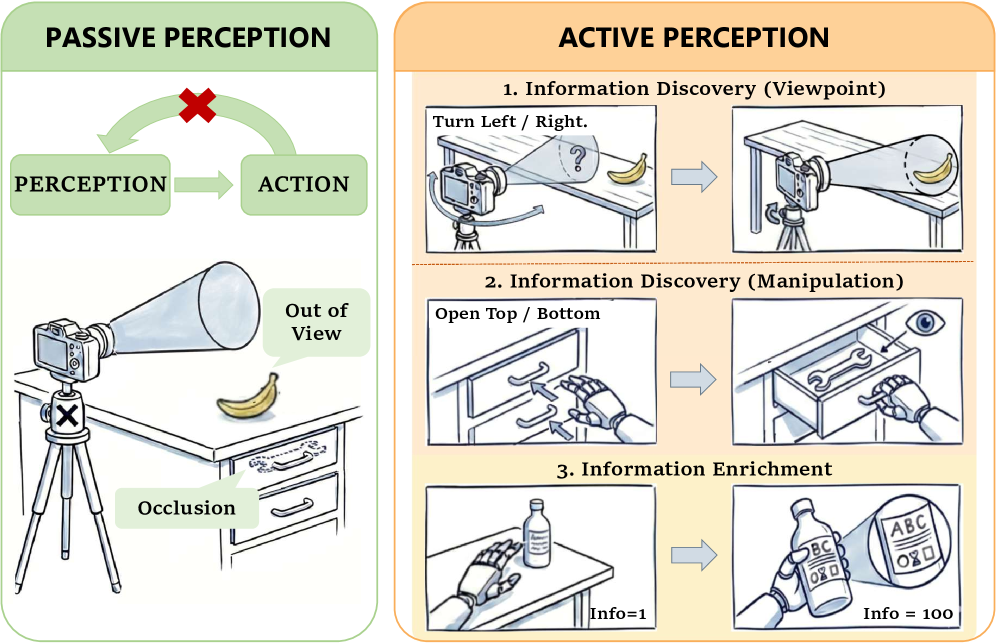
Conventional robotic systems frequently operate on a foundation of pre-defined behaviors or immediate, reactive responses to stimuli, which significantly restricts their performance when faced with the unpredictability of real-world settings. This approach, while effective in highly structured environments, struggles with the inherent ambiguity and constant change found in complex scenarios. A robot governed by these principles may execute a programmed sequence flawlessly, but falters when confronted with an unexpected obstacle or a novel situation demanding improvisation. The limitation stems from a lack of robust internal models capable of predicting outcomes and adapting strategies, effectively confining the robot to a narrow band of predictable circumstances and hindering its ability to generalize learned skills to new, unforeseen challenges.
Robotic manipulation frequently falters not because of a lack of visual data, but because systems struggle to actively reduce uncertainty during interactions. Unlike passive observation, successful grasping and manipulation demand a strategy of information gathering – a robot must intelligently move an object, or its sensors, to confirm assumptions and resolve ambiguities about an object’s properties, like its weight, fragility, or precise location. This ‘active perception’ is crucial because real-world environments are rarely perfectly known; a robot cannot simply ‘see’ a solution, it must actively seek the information needed to validate its plans and correct for unforeseen circumstances. This challenge necessitates algorithms that go beyond recognizing objects and instead prioritize actions that minimize uncertainty, effectively allowing the robot to ‘learn’ through interaction and refine its understanding of the physical world.
Robotic tasks frequently present challenges exceeding the scope of standard decision-making processes; they often operate as Non-Markovian Decision Processes. This means a robot’s current state isn’t enough to predict future outcomes – the history of actions significantly impacts what happens next. Unlike scenarios where only the present matters, a robot manipulating deformable objects, navigating cluttered spaces, or assembling complex structures must account for how prior movements have altered the environment and its own configuration. Successfully executing these tasks, therefore, demands sophisticated long-term planning capabilities, where the robot anticipates the cascading effects of its actions and adjusts its strategy accordingly. The robot must effectively ‘remember’ its past to accurately predict and shape the future, a considerable hurdle in achieving truly adaptable and intelligent robotic systems.

Mimicking the Mind: A Framework for Cognitive Robotics
The pre-training of our model utilizes human egocentric data, specifically first-person video recordings capturing everyday activities. This data provides a rich source of human priors, allowing the model to learn implicit understandings of how tasks are typically performed and the affordances of objects within the environment. By observing human actions from a first-person perspective, the model develops a natural understanding of task-relevant visual cues and anticipates likely subsequent actions. This pre-training process effectively instills knowledge about object functionality and typical interaction sequences, improving performance on downstream tasks by reducing the need for extensive task-specific training and enabling more intuitive behavior.
The CoMe-VLA framework is built upon established Vision-Language Models (VLMs), which provide the core capability to process and integrate information from both visual and textual sources. These VLMs are pre-trained on extensive datasets of image-text pairs, enabling them to establish correspondences between visual elements and their linguistic descriptions. This foundation allows CoMe-VLA to accept both visual input, such as images or video frames, and textual instructions or queries, and to generate outputs grounded in the understanding of both modalities. The use of VLMs facilitates a unified representation of visual and textual data, critical for interpreting complex task requirements and executing appropriate actions.
The CoMe-VLA framework employs a two-stage cognitive process mirroring human task completion. First, complex tasks are broken down into a sequence of manageable sub-tasks through a dedicated decomposition module. Second, a Cognitive Auxiliary Head predicts the progression through these sub-tasks, estimating the current stage of task completion based on visual and linguistic inputs. This predictive capability allows the model to anticipate necessary actions and maintain contextual understanding throughout the task, effectively simulating human cognitive strategies for improved performance and adaptability.
![CoMe-VLA leverages a pre-trained vision-language model (Qwen3-VL-2B) and a proprioceptive memory encoder to create temporal visual-semantic contexts, enabling a flow-matching decoder to generate [latex]29[/latex]-dimensional action chunks and facilitating autonomous task transitions via a cognitive auxiliary head, all trained across three stages using both human and robot data.](https://arxiv.org/html/2602.04600v1/x3.png)
The Architecture of Awareness: Memory and Action Intertwined
CoMe-VLA’s Dual-Track Memory architecture addresses the need for detailed context awareness by maintaining separate memory streams for visual and proprioceptive data. Visual information, encompassing camera inputs and scene understanding, is stored independently from proprioceptive data, which details the robot’s own state – joint angles, velocities, and forces. This separation allows the model to more effectively capture subtle environmental changes and the robot’s interaction with those changes; for example, distinguishing between a static visual obstruction and one that requires a dynamic robot response. By processing these data streams independently and then fusing them at a later stage, the system can more accurately interpret the environment and inform appropriate action planning.
Flow Matching serves as the action decoder within the model, translating the learned cognitive state into continuous robot actions. This technique differs from discrete action selection methods by directly regressing to action values, enabling the generation of smoother and more natural movements. Specifically, Flow Matching frames the action decoding process as learning a vector field that maps cognitive states to corresponding robot control signals. This continuous representation minimizes abrupt changes in robot behavior, leading to improved trajectory quality and enhanced realism in the executed actions. The method utilizes a probabilistic framework, allowing the model to account for inherent uncertainties in the state estimation and action execution processes.
Robot teleoperation was employed as the primary data collection method to generate a robot-centric dataset. This involved human operators controlling the robot’s actions in diverse environments, providing direct supervision and intervention when necessary. The resulting dataset consists of paired sensory inputs – visual and proprioceptive data – and corresponding operator actions. This approach ensures the learned behaviors are physically plausible, as they are grounded in real-world robot kinematics and dynamics. Furthermore, the teleoperation data inherently incorporates robustness to unforeseen circumstances, since operators actively resolve ambiguities and correct errors during interaction, effectively augmenting the learning process with human expertise and adaptability.

Beyond Replication: A Glimpse into True Robotic Cognition
In challenging active perception tasks, the CoMe-VLA framework achieves a remarkable 83.3% success rate, significantly surpassing the performance of established imitation learning methods. When compared to approaches like Diffusion Policy and ACT, which rely on passively learning from demonstrations, CoMe-VLA’s ability to proactively seek information dramatically improves its robustness and efficiency. This enhanced performance isn’t simply about replicating observed actions; it represents a leap towards genuine robotic intelligence, allowing the system to confidently navigate uncertainty and successfully complete tasks in dynamic environments where pre-programmed responses are insufficient.
The current generation of robotic intelligence often relies on vision-language action models, such as OpenVLA-OFT, to translate perceived environments into executable actions. However, these models frequently lack the capacity for complex problem-solving and sustained interaction. This research introduces a framework that significantly expands upon these capabilities by incorporating elements of cognitive reasoning and memory. By equipping the robot with the ability to not simply react to visual input, but to actively consider potential outcomes, plan multi-step actions, and retain information about past experiences, the system achieves a more nuanced and adaptable approach to manipulation. This integration allows the robot to move beyond rote imitation and exhibit a form of proactive intelligence, crucial for navigating unpredictable real-world scenarios and achieving robust performance.
The CoMe-VLA framework introduces an active perception loop guided by [latex]Information Gain[/latex], enabling the robot to intelligently seek out the most informative viewpoints and actions during manipulation. Unlike reactive approaches, this allows the system to proactively reduce uncertainty about the environment and the task at hand, resulting in significantly more efficient and robust performance. In rigorous testing, this methodology demonstrably surpasses existing vision-language action models; CoMe-VLA achieves an 83.3% success rate, markedly exceeding the performance of OpenVLA-OFT (70.6%), π0.5 (67.3%), ACT (57.0%), and Diffusion Policy (67.3%). This improvement highlights the critical role of proactive uncertainty resolution in achieving reliable robotic manipulation in complex scenarios.
Rigorous testing of the CoMe-VLA framework revealed the critical roles of its cognitive reasoning and memory components. Through a series of ablation studies, researchers systematically removed each element to assess its individual contribution to overall performance. Results consistently demonstrated a marked decrease in success rates when either cognitive reasoning or the memory module was disabled, confirming that both are essential for robust robotic intelligence. This suggests that simply perceiving and reacting to the environment is insufficient; effective manipulation requires the ability to reason about uncertainties and retain crucial information from past experiences to inform present actions, highlighting a significant advancement beyond traditional reactive robotic systems.
The pursuit of robust manipulation, as detailed in this work, echoes a fundamental truth about complex systems. They do not yield to brute force, but to gentle probing, a continuous act of sensing and adaptation. This mirrors the framework’s emphasis on formalizing active perception as a non-Markovian decision process – a system that acknowledges the weight of past observations. As Carl Friedrich Gauss observed, “If I have seen further it is by standing on the shoulders of giants.” CoMe-VLA doesn’t seek to build intelligence, but to cultivate it from the rich dataset of human egocentric data, building upon the accumulated wisdom of countless interactions with the world. Each cycle of act, sense, and act is a testament to the fact that growth, not construction, is the true path forward.
The Horizon of Seeking
This work formalizes active perception within a non-Markovian framework, a gesture toward acknowledging the inherent incompleteness of any state representation. It is a necessary step, yet one that merely shifts the problem. The system learns to seek information, but every query expands the surface of the unknown, revealing new dependencies. The more it ‘sees’, the more it is bound to the contingencies of a world it cannot fully grasp. The pursuit of information gain, divorced from a theory of sufficient information, feels less like intelligence and more like a beautifully rendered anxiety.
The reliance on egocentric data, while pragmatic, introduces a subtle but critical limitation. The system learns to manipulate the world as it is seen, reinforcing the observer’s biases and potentially missing opportunities beyond the narrow scope of current perception. The architecture, for all its cognitive awareness, remains tethered to a single point of view. It is a refinement of the gaze, not a transcendence of it.
Future work will inevitably focus on scaling these models, increasing the complexity of the environments, and expanding the repertoire of actions. But the true challenge lies not in adding more layers or parameters, but in confronting the fundamental paradox of control. The system seeks to act on the world, but every action reshapes the very conditions of its perception. It splits the decision process, but not its ultimate fate. Everything connected will someday fall together.
Original article: https://arxiv.org/pdf/2602.04600.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-05 15:19