Author: Denis Avetisyan
A new analysis reveals a surge in artificial intelligence research output, but finds limited evidence of increased partnerships between academia and industry.
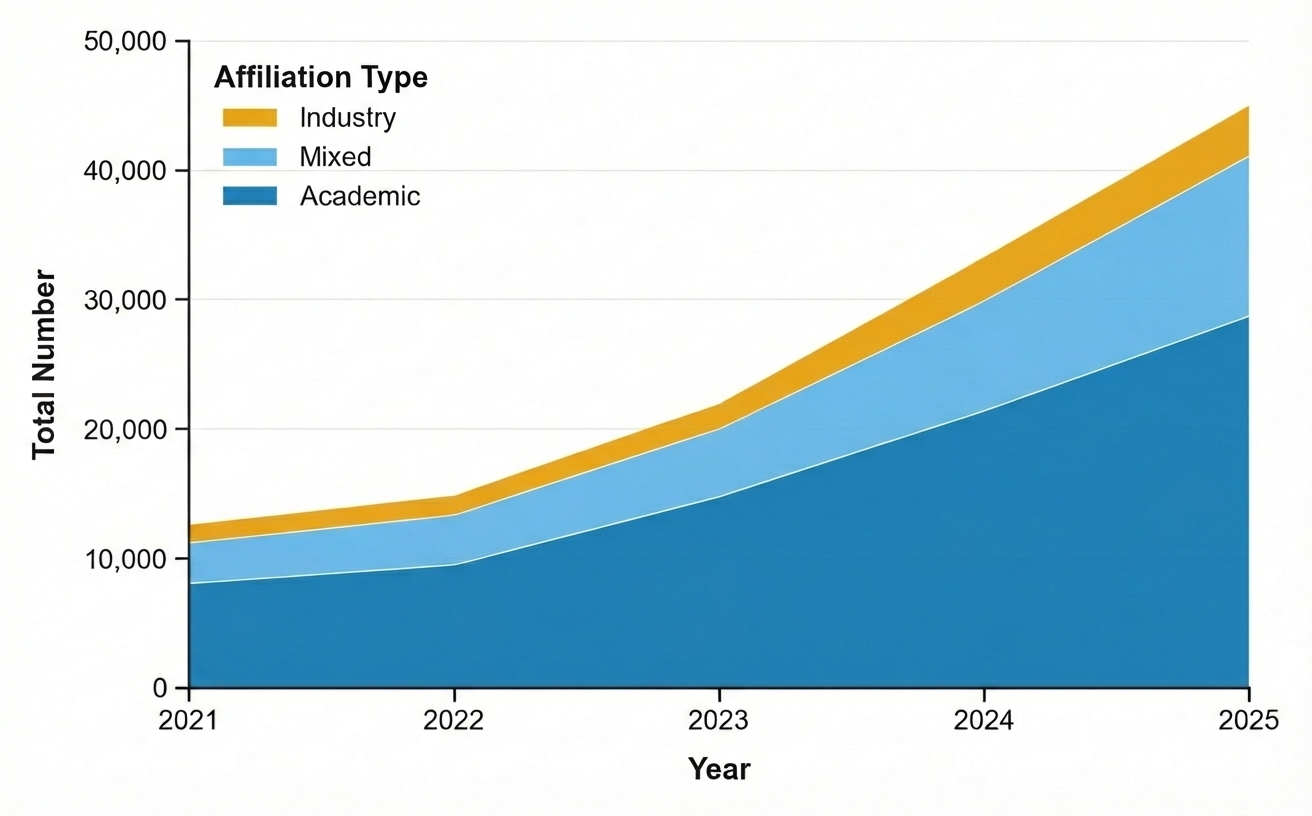
This study examines shifts in institutional participation and collaboration within the AI research landscape as measured by preprints on arXiv.
Despite rapid advancements in artificial intelligence, collaborative patterns within the field remain surprisingly fragmented. This is the central question addressed in ‘Structural shifts in institutional participation and collaboration within the AI arXiv preprint research ecosystem’, which analyzes a dataset of preprints to map evolving research dynamics. Our findings reveal a substantial surge in AI publication output coinciding with the emergence of large language models, yet academic-industry collaboration, as measured by a Normalized Collaboration Index, remains significantly below expectations. Does this persistent institutional divide signal a fundamental reshaping of scientific collaboration driven by the capital-intensive nature of generative AI research?
The Accelerating Landscape of Artificial Intelligence
The exponential growth of artificial intelligence research, particularly fueled by advancements in Large Language Models, offers an unprecedented case study for the field of Science of Science. This surge in publications isn’t merely quantitative; it represents a qualitative shift in how research is conducted, disseminated, and absorbed. Traditionally, scientific fields evolve incrementally, allowing established methodologies to track progress. However, the rapid innovation surrounding models like ChatGPT has compressed years of development into months, creating a dynamic landscape where traditional analytical tools struggle to keep pace. Consequently, researchers are now uniquely positioned to apply, and refine, Science of Science techniques – examining citation patterns, collaboration networks, and topic modeling – to understand not just what is being researched, but how this novel field is evolving in real-time, potentially informing strategies for accelerating innovation across all scientific disciplines.
The advent of ChatGPT instigated a notable acceleration in artificial intelligence research, evidenced by a substantial 35.6% increase in publication volume between 2024 and 2025. This surge isn’t merely quantitative; it necessitates innovative analytical approaches to discern emerging trends and key areas of focus within the field. Traditional scientometric methods, designed for more gradual growth, are proving insufficient to process and interpret the rapidly expanding body of literature. Consequently, researchers are actively developing and implementing new techniques-including advanced natural language processing and machine learning algorithms-to effectively map the evolving landscape of AI research, identify influential contributions, and predict future directions with greater accuracy. This shift compels a reevaluation of how knowledge is disseminated, evaluated, and ultimately, built upon in this dynamic scientific domain.
![A two-stage pipeline collects papers from arXiv, enriches them with data from OpenAlex, classifies them using a large language model, and then analyzes resulting collaborations to address research questions concerning [latex]RQ_1[/latex]-[latex]RQ_3[/latex].](https://arxiv.org/html/2602.03969v1/Pipeline_2.jpeg)
Deconstructing the AI Research Ecosystem
The artificial intelligence research landscape is fundamentally structured around two core institutional types: academic institutions and industry institutions. Academic entities, including universities and research labs, prioritize open publication, foundational research, and the training of future researchers, often operating with public or grant funding. Industry institutions, conversely, typically focus on applied research, product development, and maintaining a competitive advantage, frequently operating under conditions of intellectual property protection. While distinct in their primary objectives and operational models, these institutions are increasingly interconnected through researcher mobility, sponsored research agreements, and the shared pursuit of advancing the field of AI, creating a complex ecosystem where innovation relies on the contributions of both sectors.
The trend of mixed academic-industry collaboration is demonstrably increasing within artificial intelligence research. This manifests as joint publications, sponsored research initiatives, and the movement of personnel between universities and corporate research labs. While historically distinct, these institutions are now frequently co-authoring papers and sharing resources, particularly in computationally intensive fields. This collaborative environment is believed to accelerate progress by combining academic theoretical foundations with industry’s access to data, engineering resources, and real-world problem application. The increased interaction aims to translate research findings into practical applications more efficiently and to provide academic researchers with access to larger datasets and computational power.
Analysis of publication data across three core computer science subfields – large language models (cs.LG), computer vision (cs.CV), and computational linguistics (cs.CL) – demonstrates a consistently low Normalized Collaboration Index (NCI). The NCI, a metric quantifying collaborative output relative to expected random collaboration, remains below 1 across all examined subfields. This indicates that observed co-authorship rates are lower than would be anticipated by chance, suggesting a potential disconnect or limited interaction between academic and industry research institutions despite increasing overlap in research topics and personnel. The consistently sub-unitary NCI values therefore point to a structural barrier hindering broader collaborative efforts within the AI research landscape.
![The normalized collaboration index [latex]\mathrm{NCI}[/latex] reflects monthly shifts in collaborative publication activity relative to a random baseline, as illustrated by its correlation with publication volume and the proportion of mixed collaborations.](https://arxiv.org/html/2602.03969v1/nci_panel_B_1.png)
Mapping Collaboration Through Data Enrichment
Metadata enrichment is employed to systematically extract relevant data points from published AI research. This process goes beyond basic bibliographic information – such as author names and publication titles – to include details like research topics, funding sources, and associated keywords. Data is sourced from multiple fields within publication records, including abstracts, author affiliations, and cited references. Automated techniques, including Natural Language Processing (NLP) and machine learning algorithms, are utilized to standardize and categorize this information, resolving ambiguities and inconsistencies. The resulting enriched metadata provides a structured and comprehensive dataset for analyzing collaborative relationships and identifying key trends within the AI research community.
Email Domain Inference operates by parsing author email addresses found within publication metadata to determine institutional affiliation. This process involves extracting the domain portion of the email address (e.g., @mit.edu) and mapping it to a standardized institutional name, utilizing a regularly updated knowledge base of domain-to-institution mappings. Accuracy is maintained through fuzzy matching algorithms to account for variations in domain naming conventions and potential errors in data entry, and disambiguation rules to handle cases where multiple institutions share a common domain. The resulting data provides a quantifiable link between researchers and their affiliated institutions, enabling analysis of collaborative networks based on documented affiliations.
Network analysis, performed on the enriched metadata, identifies collaboration patterns by representing researchers and institutions as nodes, and their co-authorships or shared projects as edges. Quantitative metrics, such as degree centrality, betweenness centrality, and eigenvector centrality, are then calculated to assess the influence and importance of each node within the network. These analyses reveal key collaborators, influential institutions, and the structure of knowledge diffusion within the AI research landscape, highlighting both direct and indirect relationships that might not be apparent through simple publication lists. The resulting network maps are used to visualize these relationships and identify communities of practice focused on specific AI subfields.

The Rise of Large Teams and Concentrated Resources
A noticeable shift towards larger author teams characterizes contemporary artificial intelligence research, as evidenced by recent publication trends. This expansion isn’t simply academic inflation; it directly correlates with the escalating complexity of AI models and the inherent coordination costs associated with their development. Modern AI projects frequently necessitate expertise spanning multiple disciplines – including machine learning, software engineering, data science, and specific domain knowledge – requiring collaborative efforts beyond the scope of individual researchers. The increasing demand for substantial computational resources and meticulously curated datasets further necessitates larger teams capable of managing these complex logistical and technical challenges, ultimately driving the trend towards increasingly collaborative authorship in the field.
The escalating demands of contemporary artificial intelligence research are increasingly reliant on substantial computational resources, a need largely fulfilled by industry institutions. Training advanced AI models, particularly those employing deep learning techniques, requires access to powerful hardware – including specialized processors and vast memory capacities – alongside the energy infrastructure to operate them. These requirements create a significant barrier to entry for academic and public sector researchers, who often lack the financial and logistical means to independently procure and maintain such infrastructure. Consequently, industry entities – possessing both the resources and the incentive – have become pivotal in enabling progress in the field, effectively acting as the engine driving many of the most ambitious AI projects and shaping the landscape of innovation through access to these critical tools.
Analysis of authorship trends in artificial intelligence research consistently demonstrates a surprisingly limited degree of cross-sector collaboration, even as team sizes and computational demands escalate. Despite a clear increase in the number of researchers contributing to each publication and the vital role industry institutions play in supplying necessary resources, the Normalized Collaboration Index (NCI) remains below 1. This finding, robust even when conservatively reassigning previously unknown affiliations to plausible industry partners, suggests a significant disconnect between academic and industrial AI efforts. The data indicates that researchers largely collaborate within their respective sectors, hindering the potential for synergistic innovation that could arise from more integrated partnerships and shared expertise.
Towards a More Rigorous Science of Artificial Intelligence
Artificial intelligence is experiencing a period of unprecedented advancement, fueled by concurrent breakthroughs in core disciplines like machine learning, natural language processing, and computer vision. This rapid evolution necessitates sustained and focused research efforts; the interconnectedness of these fields means progress in one area often unlocks possibilities in others, creating a positive feedback loop of innovation. Ongoing investigation is not simply about incremental improvements, but about anticipating and addressing the fundamental challenges that arise as AI systems become more complex and integrated into daily life – from ensuring algorithmic fairness and robustness to understanding the long-term societal impacts of increasingly autonomous technologies. The current momentum suggests a trajectory of continued disruption and transformation, making dedicated scientific inquiry essential to harness the full potential of AI responsibly and effectively.
The burgeoning field of Artificial Intelligence stands to benefit significantly from the application of the Science of Science, a meta-scientific field dedicated to studying the practice of science itself. This approach moves beyond simply doing research to analyzing how innovation occurs – identifying patterns in collaboration, funding, knowledge diffusion, and the evolution of research topics. By quantifying these dynamics, researchers can pinpoint factors that accelerate discovery, such as the optimal balance between exploratory and exploitative research, the impact of diverse teams, or the effectiveness of different funding mechanisms. This understanding isn’t limited to AI; principles derived from the Science of Science have already proven valuable in fields like materials science and biomedicine, suggesting a powerful, transferable framework for optimizing the entire research lifecycle and ultimately, fostering faster, more impactful breakthroughs in Artificial Intelligence.
The future of artificial intelligence hinges on a concerted, interdisciplinary effort. Addressing the multifaceted challenges – from algorithmic bias and ethical considerations to ensuring robustness and trustworthiness – requires expertise extending beyond traditional computer science. Progress demands collaboration between social scientists, ethicists, legal scholars, and domain experts in fields poised to be transformed by AI, such as healthcare, finance, and education. This broadened perspective will not only mitigate potential risks but also unlock unforeseen opportunities, fostering innovation that is both technically sophisticated and socially responsible. By integrating diverse knowledge bases, the field can move beyond incremental improvements toward genuinely transformative advancements and ensure that AI benefits all of humanity.
The study meticulously details a surge in AI preprint submissions, revealing a quantifiable shift in research dissemination. However, the findings regarding collaboration-or rather, the lack thereof-underscore a critical point about the integrity of the research process. As Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” This sentiment, while often applied to innovation speed, resonates with the observed trend. The rapid increase in publications doesn’t inherently translate to collaborative advancement; instead, it suggests a landscape where individual or narrowly focused contributions dominate, potentially prioritizing output over rigorously vetted, collectively achieved progress. A proof of correctness, through collaborative validation, would significantly outweigh simply increasing the volume of research.
What’s Next?
The observed proliferation of preprints, while numerically significant, does not, in and of itself, constitute progress. The study reveals a landscape where increased output doesn’t necessarily translate to genuinely collaborative advancement. The Normalized Collaboration Index, a metric demanding mathematical rigor, highlights a concerning trend: growth primarily within existing structures, rather than across the academic-industrial divide. This suggests an ecosystem expanding in volume, but not necessarily in conceptual space.
Future work must move beyond mere descriptive statistics. A critical examination of citation networks – tracing the mathematical lineage of ideas – will be essential. Identifying truly novel contributions, those demonstrably building upon, or challenging, existing theorems, requires more than keyword analysis. The current focus on LLMs as subjects of study should shift towards analyzing them as tools – quantifying their impact on the rate of mathematical proof, or the generation of verifiable hypotheses.
In the chaos of data, only mathematical discipline endures. The study’s limitations – the inherent difficulties in quantifying ‘collaboration’ and the potential for algorithmic bias – demand attention. The next phase of inquiry should prioritize the development of robust, mathematically grounded metrics, capable of discerning genuine scientific synergy from mere co-authorship. Only then can a truly accurate assessment of the LLM era’s impact on AI research be achieved.
Original article: https://arxiv.org/pdf/2602.03969.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-05 11:58