Author: Denis Avetisyan
A new approach dramatically speeds up the process of finding optimal solutions by focusing on the meaning of code updates, not just the code itself.
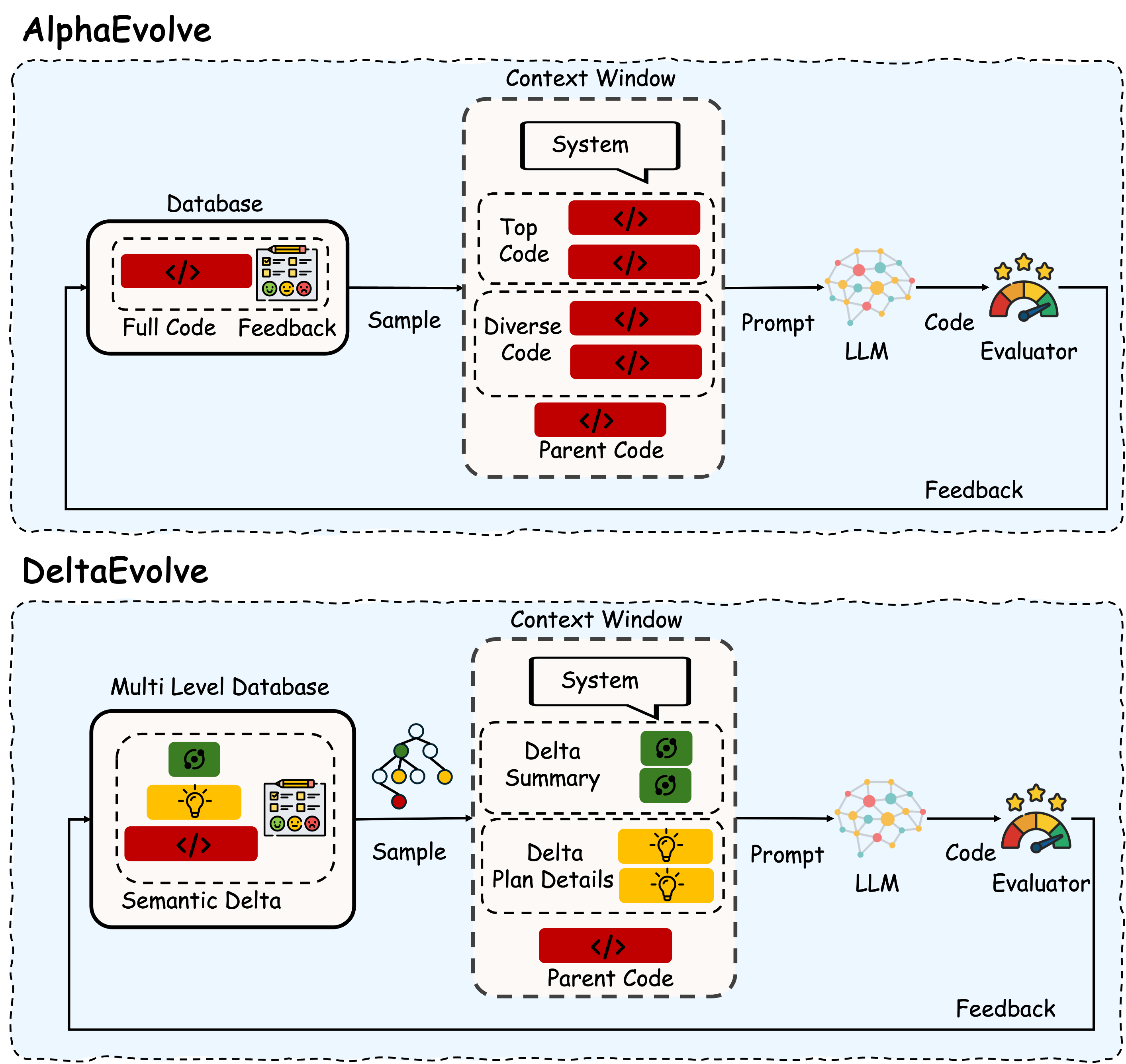
DeltaEvolve leverages semantic deltas and a momentum-driven framework to accelerate LLM-driven program synthesis and reduce token consumption.
While recent advances in LLM-driven evolutionary systems hold promise for automated scientific discovery, existing approaches often suffer from inefficiencies due to reliance on full-code histories as evolutionary guidance. This work introduces ‘DeltaEvolve: Accelerating Scientific Discovery through Momentum-Driven Evolution’, a novel framework that addresses this limitation by representing program changes as compact ‘semantic deltas’-structured summaries of how and why modifications impact performance. By distilling evolutionary information into transferable semantic changes and employing a progressive disclosure mechanism, DeltaEvolve significantly reduces token consumption while discovering superior solutions across diverse scientific domains. Could this momentum-driven approach unlock a new era of efficient and scalable automated science?
Navigating Complexity: The Limits of Traditional Optimization
Many optimization challenges encountered in practical applications fall under the category of blackbox optimization, a situation where the precise mathematical form of the problem’s objective function is unknown or computationally intractable to analyze. This opacity arises frequently in fields like drug discovery, materials science, and complex engineering design, where evaluating a proposed solution might require running a costly simulation or physical experiment. Consequently, algorithms must treat the objective function as a ‘blackbox’ – they can input parameters and observe the resulting output, but lack insight into the internal workings that govern the relationship between inputs and outputs. This necessitates relying on iterative sampling and approximation techniques to navigate the solution space, making efficient exploration a critical hurdle, particularly as the number of variables increases and the landscape becomes riddled with local optima and high dimensionality.
The pursuit of optimal solutions often leads to problems defined by expansive search spaces-the sheer number of possibilities grows exponentially with increasing complexity. Traditional optimization techniques, while effective on simpler problems, quickly become computationally prohibitive when confronted with these vast landscapes. This challenge is acutely felt when employing Large Language Models (LLMs) for optimization, as each evaluation of a potential solution requires significant processing power and time. The inherent complexity of LLMs, combined with the need to explore numerous possibilities, creates a substantial computational burden, limiting their practical application to problems with manageable search spaces and hindering the exploration of genuinely complex optimization challenges. Consequently, advancements are needed to make LLM-driven optimization scalable and efficient for real-world applications.
Large Language Models, while powerful, are fundamentally constrained by their limited context windows – the amount of text they can process at once. This presents a significant hurdle in blackbox optimization, where effective exploration requires considering a potentially vast history of attempted solutions and their corresponding results. The model’s inability to ‘remember’ beyond this window restricts its capacity for complex reasoning and prevents it from identifying subtle patterns or long-term dependencies crucial for navigating intricate search spaces. Consequently, the optimization process can become shortsighted, leading to premature convergence on suboptimal solutions or an inability to escape local minima. Essentially, the model operates with a fragmented understanding of the problem, hindering its ability to strategically plan and execute a comprehensive search for the global optimum.
The practical application of Large Language Models (LLMs) to complex optimization problems is often hindered by substantial token consumption, driving up computational costs and limiting the scale of solvable tasks. Each interaction with an LLM requires tokens for both input and output, and these costs accumulate rapidly during iterative optimization processes. Recent advancements, such as the DeltaEvolve framework, directly address this limitation by significantly reducing token usage. Through a novel approach to encoding and processing information, DeltaEvolve achieves an average reduction in token consumption of approximately 36.79%, enabling more efficient exploration of complex search spaces and making LLM-powered optimization viable for a broader range of real-world applications. This reduction not only lowers costs but also allows for deeper reasoning and more extensive problem-solving within the constraints of LLM context windows.
![Across 100 iterations of black-box optimization, [latex]\Delta\text{Evolve}[/latex] consistently outperforms AlphaEvolve, achieving higher scores while consuming fewer tokens, with point size indicating context diversity.](https://arxiv.org/html/2602.02919v1/figures/compare_alpha_delta.png)
Evolving Solutions: The Power of Semantic Deltas
DeltaEvolve minimizes computational expense by representing program evolution not as modifications to complete codebases, but as semantic deltas. These deltas are concise data structures capturing the precise changes between successive program states – for example, a function call replacement or a variable reassignment. By operating on these deltas, rather than entire programs, the computational burden is significantly reduced, particularly in LLM-driven evolutionary processes. The size of a semantic delta is typically orders of magnitude smaller than the full program it modifies, leading to decreased processing time and resource consumption during evaluation and mutation phases. This approach is crucial for scaling program evolution to complex tasks and larger codebases.
DeltaEvolve minimizes the computational burden on Large Language Models (LLMs) by employing a strategy of evolving semantic deltas instead of complete programs. Traditional program evolution requires processing and maintaining the entire codebase within the LLM’s context window, which is a significant limitation given the size of complex software. DeltaEvolve represents program changes as concise deltas – minimal modifications to existing code – and focuses the LLM’s attention solely on these incremental alterations. This approach drastically reduces the amount of data the LLM must process at each iteration, allowing for evolution of larger and more complex programs within fixed context window constraints. The size reduction is proportional to the complexity of the changes relative to the overall program size, enabling efficient exploration of the solution space.
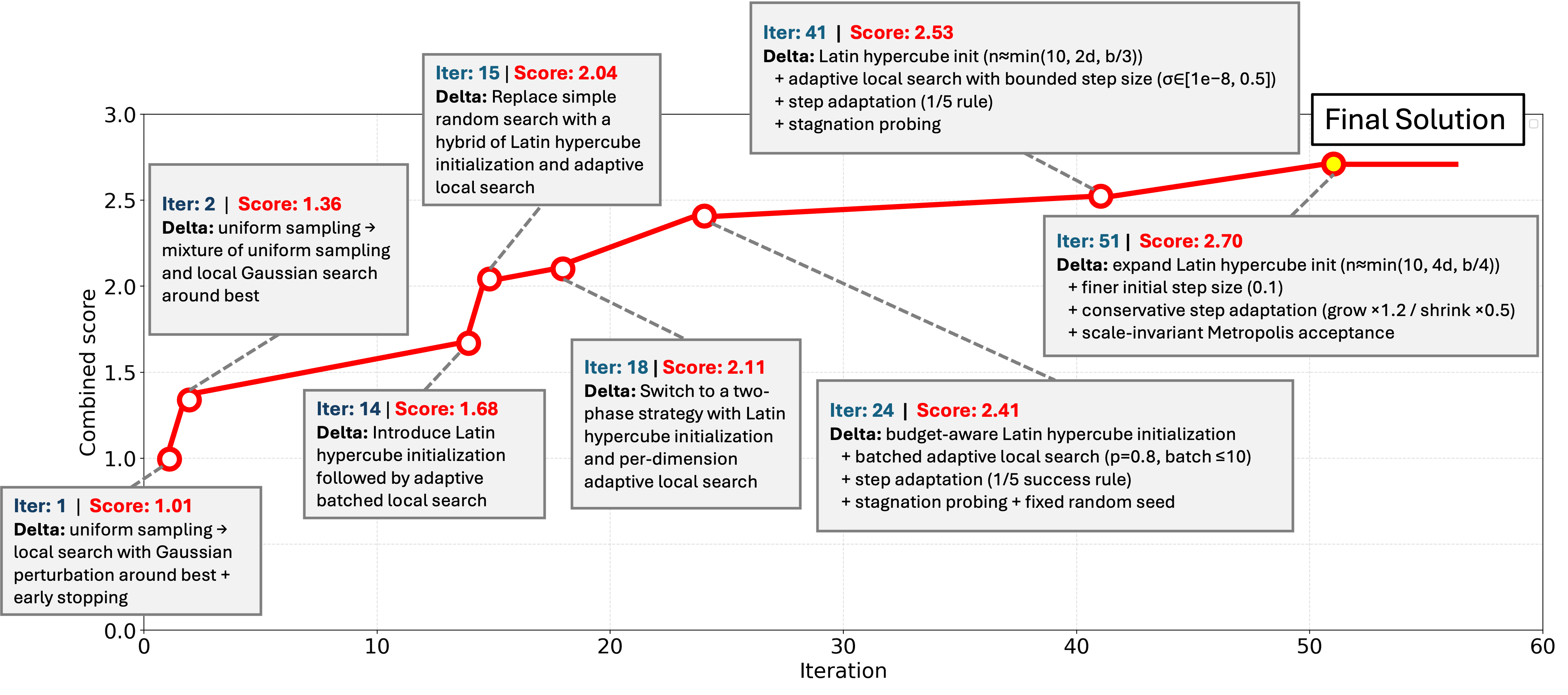
DeltaEvolve incorporates momentum to enhance the efficiency of its evolutionary process by retaining information about previous updates to the semantic delta. This is achieved by factoring in the change in delta values from prior iterations when calculating the current update, analogous to momentum in gradient descent optimization. Specifically, a fraction of the previous delta update is added to the current update, effectively smoothing the search process and preventing oscillations. This allows DeltaEvolve to navigate the solution space more rapidly, accelerating learning and improving convergence, particularly in scenarios with noisy or sparse reward signals.
DeltaEvolve utilizes a multi-level database architecture to manage program information, optimizing both storage and retrieval efficiency. This database is structured with three primary layers: delta summaries, which provide high-level overviews of program changes; delta plans, detailing the specific steps required to implement those changes; and full code representations of the program at any given state. Delta summaries enable rapid identification of relevant program evolutions, while delta plans facilitate targeted modifications without requiring complete program re-evaluation. Access to the full code layer is reserved for final program construction or detailed analysis. This tiered approach minimizes data transfer and processing requirements, allowing for scalable management of complex program evolution histories.
![Unlike existing methods that rely on storing complete programs, [latex]\Delta\text{Evolve}[/latex] stores semantic deltas-changes and their rationales-to create a momentum-based memory system that facilitates more effective program reuse and guidance.](https://arxiv.org/html/2602.02919v1/figures/deltaevolve_main_arxiv.png)
Demonstrating Capability: Diverse Problem-Solving Performance
DeltaEvolve has been evaluated on tasks requiring complex problem-solving capabilities, consistently achieving high performance. In symbolic regression, the framework successfully identifies mathematical equations that fit provided data. Performance was also demonstrated in hexagon packing problems, where DeltaEvolve efficiently arranged hexagonal shapes to maximize space utilization. Furthermore, the system has shown competence in solving partial differential equations (PDESolver), a computationally intensive task with applications in physics and engineering, indicating a capacity for handling problems demanding both analytical and numerical skills.
DeltaEvolve’s efficiency is improved through the use of an LLM Ensemble, a technique that leverages the complementary capabilities of multiple large language models. Rather than relying on a single LLM, the ensemble combines predictions and outputs from several models, mitigating the weaknesses of any individual model and capitalizing on their collective strengths. This approach enhances the robustness and accuracy of the problem-solving process by reducing the risk of errors stemming from biases or limitations inherent in a single LLM. The ensemble allows for a more comprehensive exploration of the solution space, leading to improved performance across diverse tasks and a reduction in computational cost compared to utilizing a single, highly complex model.
DeltaEvolve incorporates MAP-Elites, a quality-diversity algorithm, to cultivate a broad range of solutions during the optimization process. MAP-Elites achieves this by maintaining a population of individuals categorized by both their performance, as measured by a fitness score, and their behavioral characteristics, defined by a feature vector. This allows the algorithm to explore and retain solutions that may not be globally optimal but represent distinct strategies for problem solving. The resulting diverse population improves the robustness of DeltaEvolve by providing alternative solutions that can perform well under varying conditions or in the face of unforeseen challenges, mitigating the risk of relying on a single, potentially brittle, optimal solution.
The Progressive Disclosure Sampler is a technique employed to optimize interaction with Large Language Models (LLMs) by dynamically controlling the granularity of information provided. Instead of presenting the LLM with the complete problem state initially, the sampler begins with a minimal representation and incrementally adds details based on the LLM’s responses and observed information gain. This adaptive approach reduces the number of tokens required per interaction, lowering computational cost and addressing LLM context window limitations. By prioritizing the delivery of information that demonstrably impacts solution quality, the sampler accelerates convergence and improves the efficiency of the problem-solving process, effectively maximizing the value derived from each LLM query.
![[latex]\Delta\text{Evolve}[/latex] outperforms other methods by achieving a superior combined accuracy/speed score while simultaneously reducing token usage.](https://arxiv.org/html/2602.02919v1/figures/compare_tokens_pde.png)
Beyond Current Limits: A Trajectory Towards Sustainable AI
DeltaEvolve tackles a significant challenge in leveraging large language models (LLMs) for intricate problem-solving: computational efficiency. Current approaches often require LLMs to process extensive code histories, creating a substantial bottleneck in both time and resources. This framework instead prioritizes a streamlined representation focusing on semantic deltas – the meaningful changes between code iterations. By concentrating on these crucial adjustments, DeltaEvolve drastically reduces the information LLMs must handle, enabling faster processing and lower computational costs without sacrificing performance. This incremental approach not only makes complex problem-solving more feasible but also opens doors for continuous learning and adaptation, allowing agents to refine their strategies over time with greater efficiency.
DeltaEvolve distinguishes itself through its capacity for ongoing refinement, achieved by focusing on semantic deltas – the meaningful changes between successive iterations of an agent’s strategy. Rather than storing complete code histories, the framework selectively retains only the crucial modifications that contribute to improved performance. This approach allows agents to learn and adapt continuously, building upon prior successes and correcting errors without the computational burden of processing redundant information. By prioritizing these semantic shifts, DeltaEvolve effectively creates a pathway for persistent learning, enabling agents to hone their problem-solving skills over extended periods and navigate increasingly complex challenges with greater efficiency and resilience.
Recent research highlights a significant advancement in the efficiency of applying large language models to complex problem-solving through a novel approach to code representation. While prior systems, such as AlphaEvolve, relied on maintaining a complete history of code modifications, DeltaEvolve demonstrates that focusing on semantic deltas – the meaningful changes between code iterations – can yield comparable, and often superior, performance. This streamlined methodology reduces token consumption by an average of 36.79% across diverse scientific domains, including physics, chemistry, and biology. By transmitting only the essential modifications, DeltaEvolve not only decreases computational demands but also facilitates faster adaptation and learning, paving the way for more sustainable and scalable AI-driven scientific discovery.
Ongoing research aims to synergize DeltaEvolve with complementary evolutionary algorithms, notably Expectation-Maximization (EM). This integration proposes a hybrid approach where DeltaEvolve’s efficient semantic delta representation guides the search for optimal solutions, while EM refines the underlying probabilistic models driving the agent’s decision-making process. By combining DeltaEvolve’s strengths in focused adaptation with EM’s capacity for robust model estimation, researchers anticipate a significant boost in problem-solving capabilities, potentially unlocking solutions to increasingly complex scientific challenges and accelerating the development of autonomous agents capable of continuous learning and improvement in dynamic environments.
The pursuit of efficient program synthesis, as detailed in DeltaEvolve, echoes a fundamental principle of system design: structure dictates behavior. This framework’s focus on ‘semantic deltas’-compact representations of change-demonstrates a commitment to distilling essential information. Donald Davies aptly observed, “Simplicity is not minimalism but the discipline of distinguishing the essential from the accidental.” DeltaEvolve embodies this discipline, minimizing token consumption not through arbitrary reduction, but by intelligently focusing on meaningful program alterations. This approach, prioritizing clarity and conciseness, allows the framework to accelerate scientific discovery by optimizing for the core elements driving evolutionary progress.
The Road Ahead
DeltaEvolve demonstrates the power of shifting focus from complete reconstruction to incremental refinement. Yet, the very efficiency gained through semantic deltas reveals a deeper constraint. Every compression, every abstraction, introduces a potential loss of expressive power. The framework operates under the assumption that ‘meaningful’ change can be captured in a compact representation; a proposition that, while empirically supported here, begs the question of what remains unsaid. The hidden cost of freedom from token limitations is the potential for solutions to converge upon a local optimum, bounded by the very constraints designed to accelerate discovery.
Future work must address the tension between compression and completeness. Exploring methods to dynamically adjust the granularity of semantic deltas – to ‘zoom in’ when necessary – may prove crucial. Furthermore, the reliance on momentum-driven evolution, while effective, presents a risk of premature convergence. Investigating alternative selection pressures, perhaps incorporating elements of novelty-seeking or disruptive mutation, could broaden the search space and prevent stagnation.
Ultimately, this line of inquiry highlights a fundamental truth: optimization is not merely about achieving a solution, but about defining the space within which that solution can exist. The elegance of a system lies not in its complexity, but in the clarity with which its boundaries are defined.
Original article: https://arxiv.org/pdf/2602.02919.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-05 05:31