Author: Denis Avetisyan
New research reveals that our gaze shifts not based on whether a video is real or fake, but on our conscious effort to determine its authenticity.
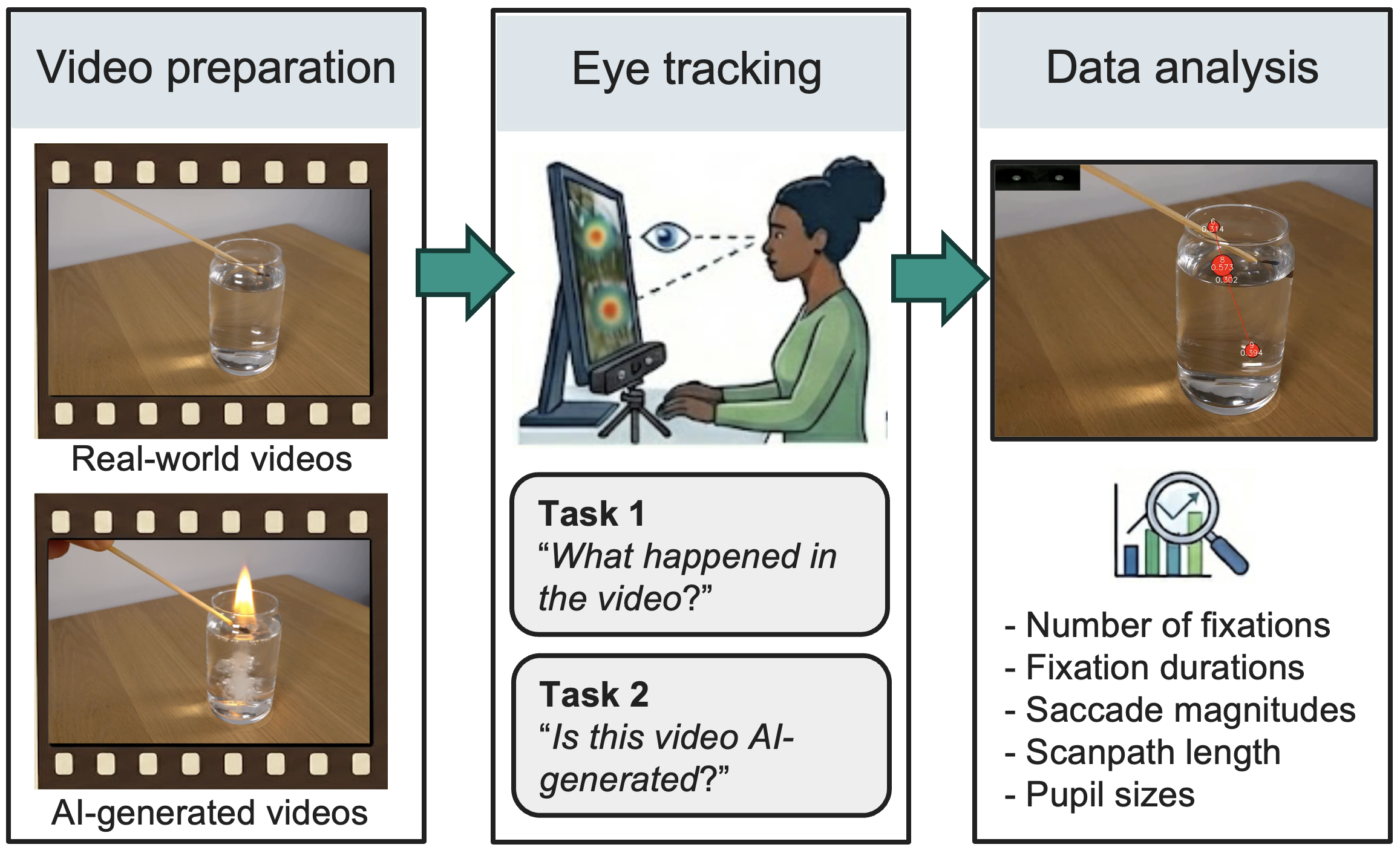
Eye-tracking data shows that the attempt to detect AI-generated content, and a person’s belief about a video’s origin, significantly alters visual attention patterns.
The increasing photorealism of AI-generated videos presents a paradox: as synthetic media become indistinguishable from reality, understanding how humans perceive them becomes critical for maintaining trust in visual information. This study, ‘How do people watch AI-generated videos of physical scenes?’, investigates human gaze behavior while viewing both real and AI-generated footage, revealing that viewers’ attention is less driven by a video’s actual authenticity and more by their belief in its authenticity. Specifically, the mere awareness of potential AI generation shifts media consumption from passive viewing to an active search for inconsistencies. Will these altered viewing patterns ultimately inform more effective AI detection methods, or will synthetic media continue to erode our ability to discern fact from fiction?
Unmasking the Illusion: The Erosion of Visual Truth
The rapid advancement of artificial intelligence is manifesting in video generation capabilities that are increasingly difficult to distinguish from reality. Contemporary generative models now produce videos with nuanced facial expressions, realistic lighting, and coherent narratives, surpassing earlier iterations plagued by noticeable artifacts. This heightened fidelity isn’t simply a matter of improved resolution; algorithms now convincingly simulate subtle human behaviors and environmental details, creating fabricated content that bypasses traditional detection methods reliant on identifying visual inconsistencies. The consequence is a growing erosion of trust in visual media, as viewers struggle to differentiate between genuine footage and skillfully constructed simulations, potentially impacting areas ranging from news consumption to legal evidence.
The proliferation of convincingly realistic, AI-generated videos introduces a significant challenge to human perception and media literacy. As generative models rapidly advance, the visual cues traditionally relied upon to verify authenticity – subtle inconsistencies in lighting, unnatural movements, or illogical scenarios – are becoming increasingly difficult to detect. This erosion of visual trust means viewers are now facing an environment where fabricated events can appear indistinguishable from reality, potentially influencing opinions, spreading misinformation, and undermining faith in legitimate sources. The human visual system, evolved to interpret a world of naturally occurring phenomena, is proving vulnerable to these meticulously crafted simulations, demanding new strategies for critical evaluation and content verification.
Traditional techniques for identifying manipulated videos, initially developed to counter early DeepFakes, are rapidly losing efficacy as generative models become more advanced. These earlier detection methods often relied on identifying specific artifacts – glitches in blinking, inconsistencies in lighting, or unnatural facial expressions – introduced by the limitations of previous AI. However, contemporary generative adversarial networks (GANs) and diffusion models now produce strikingly realistic content, minimizing these telltale signs. The improvements in resolution, frame consistency, and nuanced detail mean that current algorithms struggle to reliably differentiate between genuine footage and AI-generated simulations, necessitating a shift towards more sophisticated detection strategies that focus on subtle inconsistencies in the semantic content rather than purely visual artifacts. This evolving landscape presents a significant challenge, demanding continuous innovation in forensic analysis to stay ahead of increasingly convincing digital forgeries.
As artificial intelligence rapidly advances in its capacity to generate photorealistic video, a critical need arises to examine the fundamental processes of human visual perception. The escalating fidelity of AI-created content isn’t simply a technological hurdle; it directly challenges the cognitive mechanisms humans employ to assess authenticity. Researchers are now investigating how subtle inconsistencies – often imperceptible on a conscious level – might be detected by the visual system, and whether these cues are being effectively countered by increasingly refined generative models. This involves exploring areas like the perception of micro-expressions, natural body movements, and the consistency of lighting and shadows, with the aim of identifying vulnerabilities in human visual processing that AI can exploit, and conversely, developing methods to bolster our ability to discern genuine imagery from sophisticated simulations.
Decoding the Gaze: The Language of Visual Attention
Eye-tracking technology functions on the principle that visual attention is tightly coupled with eye movements. Specifically, it measures where an individual is looking – their point of gaze – and for how long. This data provides insights into cognitive processes because the eyes typically fixate on areas of interest within a visual field, with rapid movements, known as saccades, connecting these fixations. The sequence of fixations and saccades, or scanpath, represents a record of visual exploration and is directly related to information processing, object recognition, and decision-making. By analyzing these patterns, researchers can infer the cognitive demands of a visual stimulus and understand how attentional resources are allocated during perception.
Eye-tracking technology quantifies visual exploration through the measurement of several key metrics. Fixations represent periods where the eye remains relatively still, indicating active processing of information within that specific area of the visual field. Saccades are the rapid, ballistic movements between fixations, and their characteristics – amplitude, velocity, and direction – provide insight into the viewer’s search strategy. A scanpath is the complete sequence of fixations and saccades, effectively mapping the order in which a viewer attends to different elements within a scene. By analyzing these data points, researchers can reconstruct a detailed picture of how a viewer’s gaze traverses a visual stimulus, revealing areas of interest and the cognitive processes involved in visual perception.
Gaze behavior, as measured by eye-tracking, provides quantifiable data regarding cognitive load and attentional resource allocation. Longer fixation durations typically indicate increased cognitive processing demands on a specific area of interest, suggesting more complex feature extraction or decision-making. Conversely, rapid saccades – the quick movements between fixations – suggest efficient scanning of less demanding areas. The frequency and distribution of saccades, alongside fixation durations, reveal how attentional resources are distributed across a visual stimulus; areas receiving more frequent or prolonged attention are prioritized by the cognitive system. Consequently, analyzing scanpaths – the sequence of fixations and saccades – allows researchers to infer the cognitive processes involved in visual perception and information processing, and to quantify the mental effort required to process specific visual content.
The study posited that videos generated using artificial intelligence would produce measurably different gaze patterns in viewers compared to recordings of authentic visual scenes. This hypothesis stems from the expectation that subtle inconsistencies in AI-generated content – relating to physics, common sense reasoning, or realistic human behavior – would draw increased visual attention in the form of longer fixations or altered scanpaths. Specifically, viewers might spend more time examining areas where the AI-generated content deviates from expected norms, resulting in statistically significant differences in metrics such as fixation count, average fixation duration, and saccade amplitude when comparing gaze data from AI and authentic videos. These divergences in gaze behavior are proposed as potential indicators of the artificial origin of the video content.
Unveiling the Fabrications: Gaze as a Lie Detector
The AI detection task involved human participants viewing a curated set of video stimuli comprising both AI-generated and authentic, naturally-recorded videos. Participants were presented with these videos and asked to classify each one as either AI-generated or real. The selection of AI-generated videos utilized current generative models, while real videos represented a diverse range of content to ensure ecological validity. Data collected during the task included participant responses – their classification of each video – as well as detailed recordings of their visual behavior, specifically eye movements and pupillary responses, which were captured using an eye-tracking system synchronized with video presentation.
Gaze behavior analysis during the AI detection task revealed statistically significant differences in both scanpaths and pupillary response between AI-generated and real videos. Scanpaths, representing the sequence of fixations, demonstrated divergent patterns, indicating how participants visually explored the content differed based on authenticity. Furthermore, pupillary response, measured by changes in pupil size, also showed significant variation. These physiological responses are linked to cognitive processing and attentional effort; therefore, discrepancies in scanpaths and pupil size provide quantifiable data suggesting a distinct cognitive load associated with viewing AI-generated versus real video content.
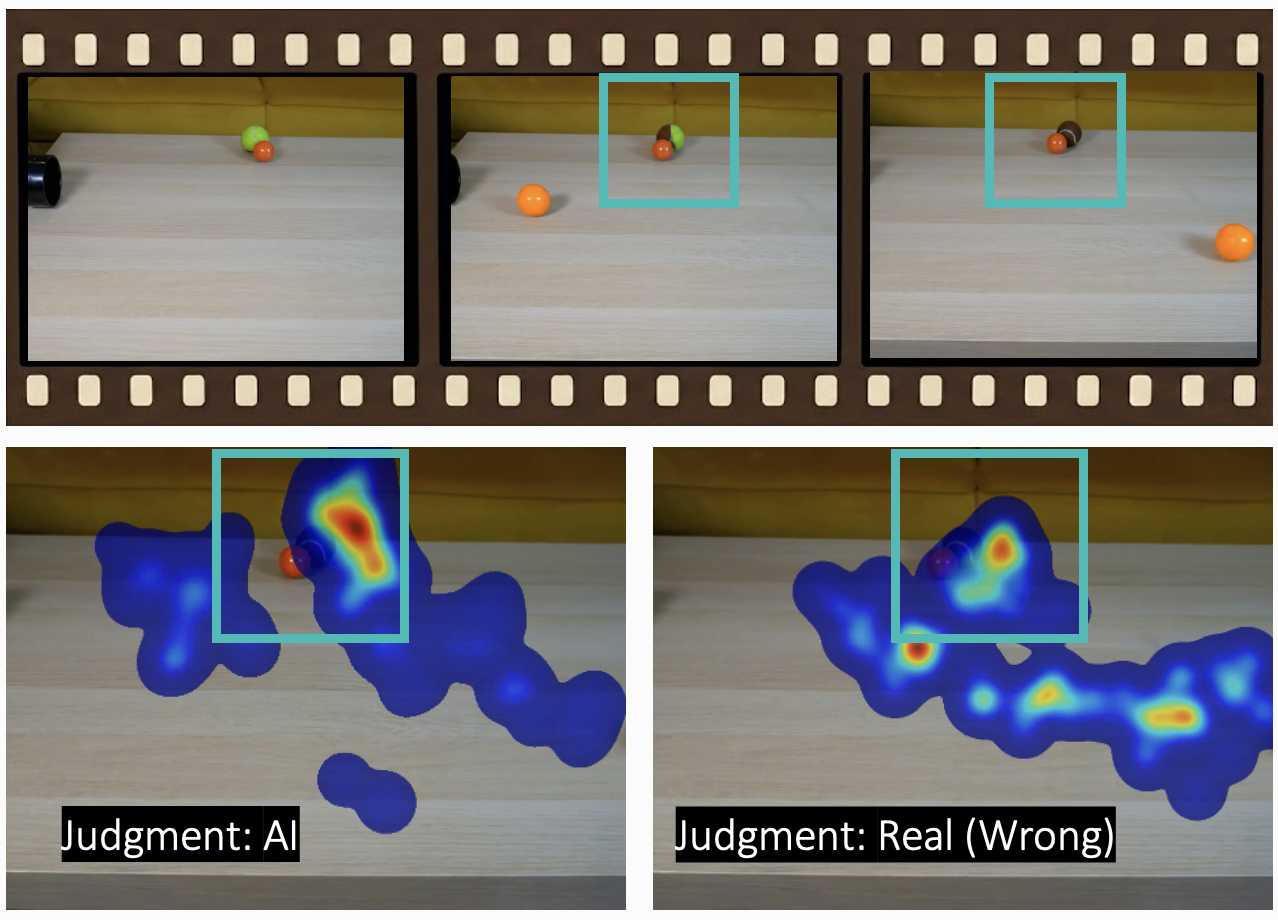
Analysis of participant eye-tracking data revealed that AI-generated videos consistently prompted longer fixation durations on discrete areas within the visual field. This contrasts with viewing real videos, which exhibited more dynamic scanpaths characterized by shorter, more frequent shifts in gaze. The extended fixations observed during the viewing of AI-generated content suggest a potential lack of natural visual flow, as if viewers are spending more time processing individual elements due to a perceived absence of coherent movement or realistic detail. This pattern implies that the artificial nature of these videos may disrupt the typical saccadic eye movements associated with observing real-world scenes.
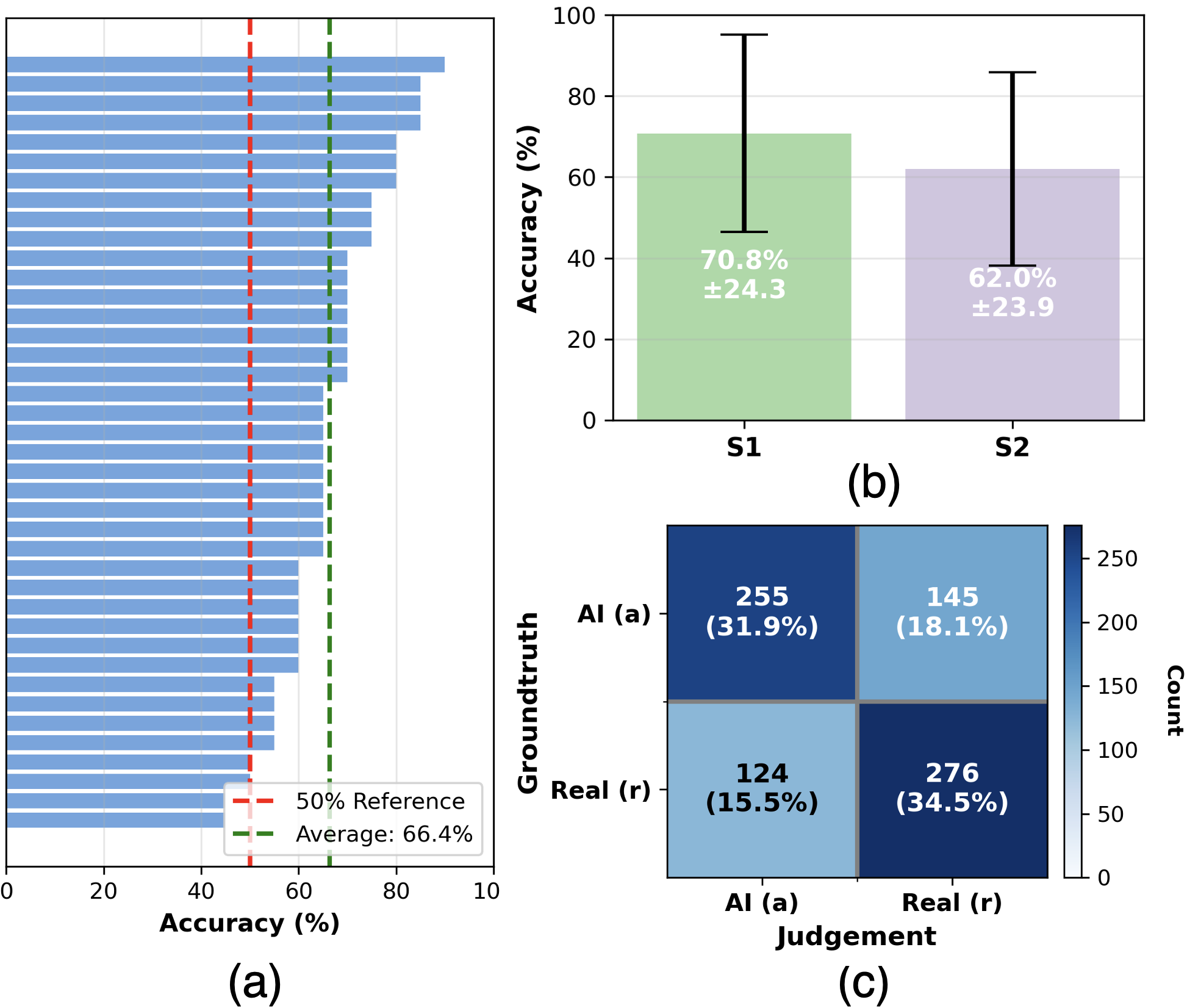
Participants in the AI detection task achieved a mean accuracy rate of 66.4% in correctly identifying AI-generated videos. This indicates a statistically significant, though not perfect, ability to differentiate between synthetic and authentic video content. While the accuracy rate suggests a potential for human discernment, the remaining 33.6% error rate highlights the increasing sophistication of AI video generation techniques and the challenges in reliably detecting them. Further analysis of the factors contributing to both correct and incorrect classifications is necessary to improve detection rates and understand the perceptual cues influencing human judgment.
Analysis of participant eye-tracking data during the AI detection task revealed a statistically significant correlation between perceived video authenticity and gaze behavior. Specifically, participants exhibited a greater number of fixations (p<0.05) when they believed a video to be real, indicating increased visual sampling of the content. Conversely, fixation durations were significantly shorter (p<0.01) during instances where participants identified, or believed they were viewing, an AI-generated video. These findings suggest that the cognitive processing associated with viewing perceived authentic video content differs measurably from that of perceived synthetic video, as reflected in altered patterns of visual attention and information processing speed.
Analysis of human visual attention during video assessment demonstrates potential for use in authenticity detection. Specifically, observed differences in scanpaths and pupillary response – including fixation count and duration – between real and AI-generated videos indicate a measurable physiological response to manipulated content. Statistical significance (p<0.05 for fixation count, p<0.01 for duration) supports the reliability of these patterns as indicators. While current detection accuracy averages 66.4%, the consistent divergence in visual attention suggests that further refinement of gaze-based metrics could improve automated detection capabilities and provide a valuable tool for verifying video authenticity.
The Critical Eye: Strategies for Discerning Reality
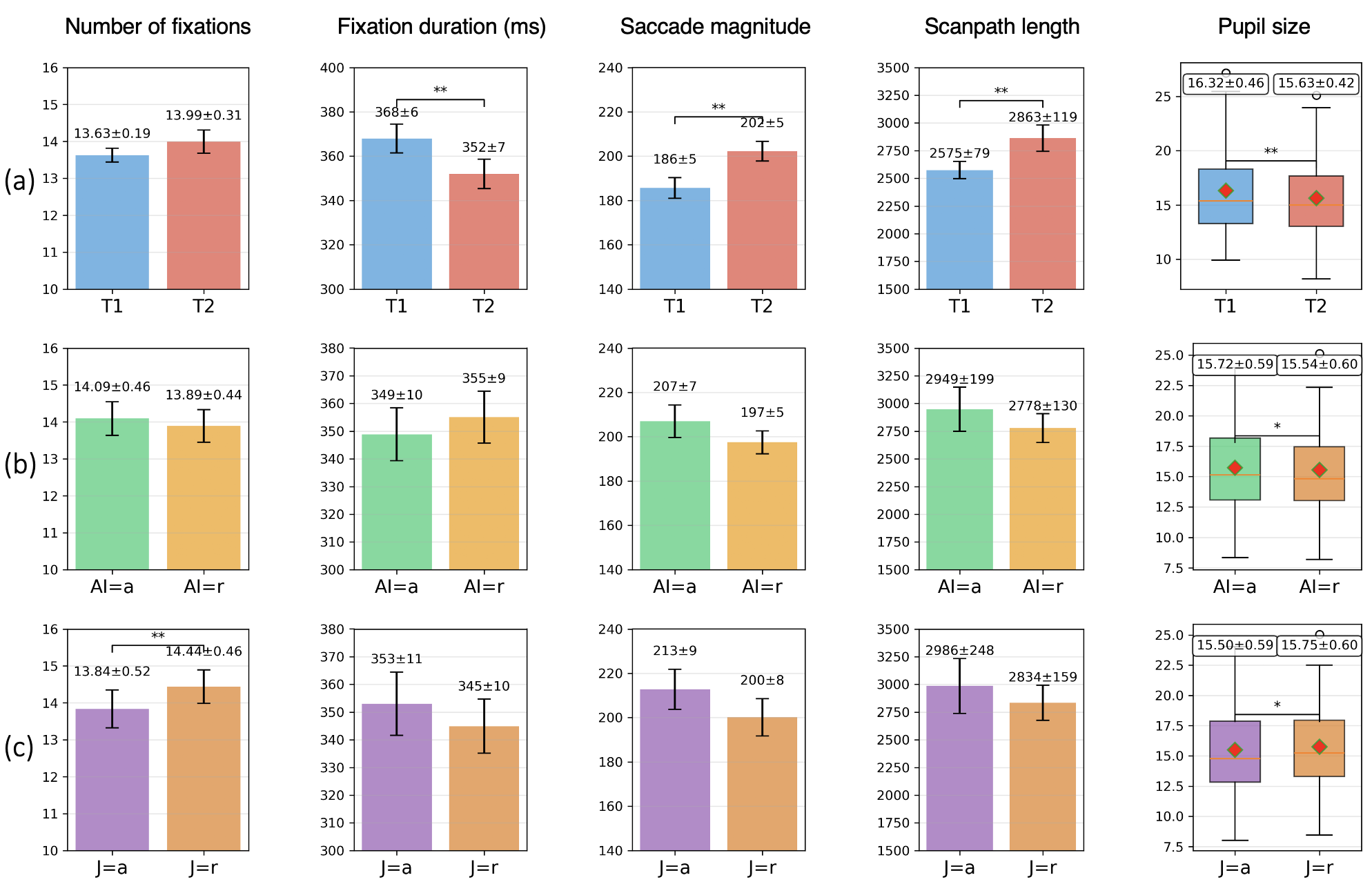
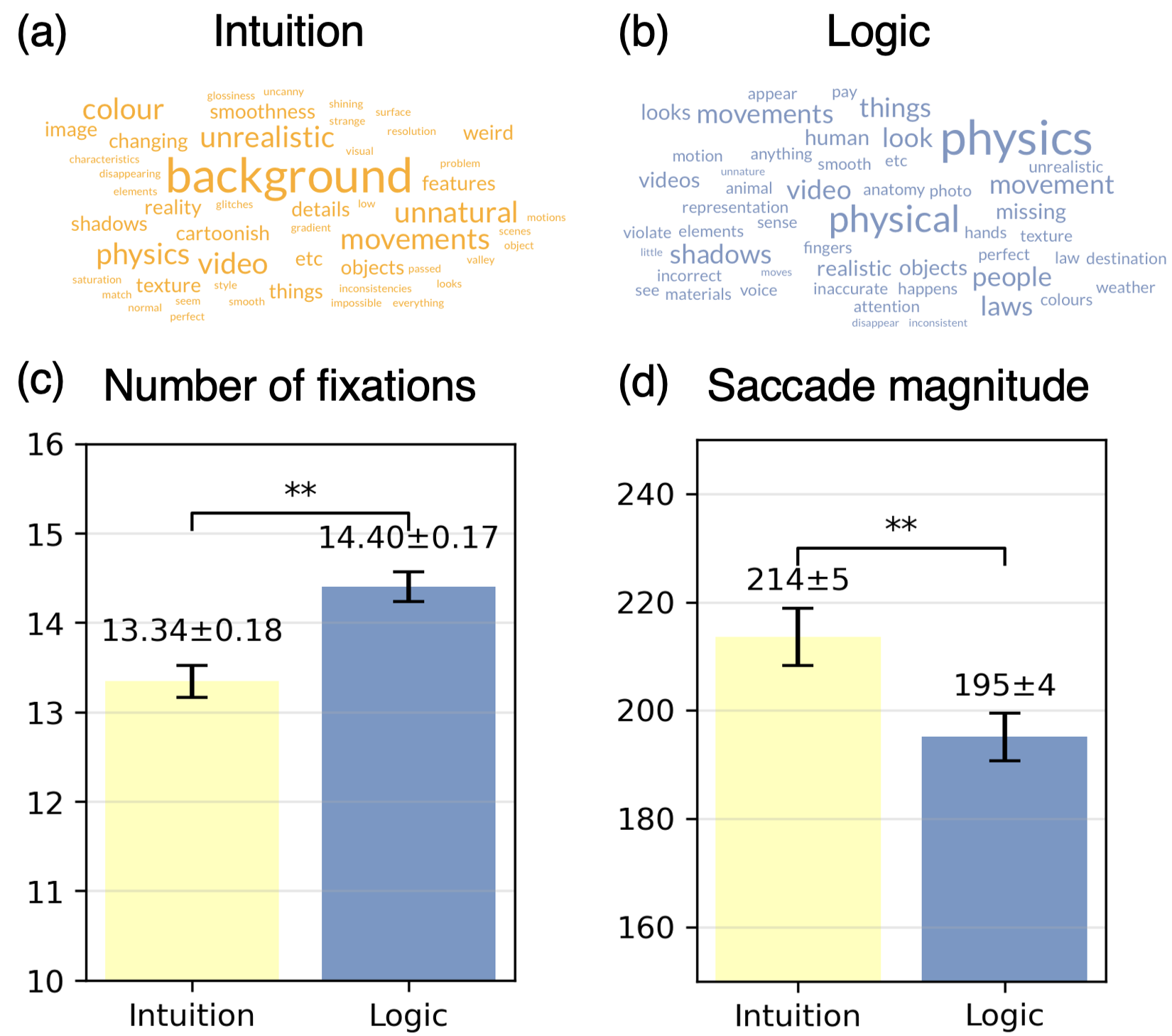
Recent research indicates that a deliberate, analytical approach – termed a ‘logical strategy’ – significantly improves the detection of AI-generated videos. This strategy involves viewers consciously scrutinizing content for inconsistencies or artifacts indicative of artificial creation, rather than relying on gut feelings or initial impressions. Findings reveal that individuals employing this method actively seek out anomalies in physics and professionally-edited videos, demonstrating the generalizability of this technique across diverse content types. The effectiveness of this logical strategy is further underscored by observed physiological differences; participants utilizing this approach exhibited smaller, more focused eye movements, suggesting a concentrated visual search for telltale signs of AI manipulation. While increasingly sophisticated models like Google Veo pose evolving challenges, this research highlights the power of focused observation in discerning authentic content from synthetic media.
Reliance on an intuitive strategy for identifying AI-generated videos appears to be a less robust method, potentially increasing the risk of incorrectly labeling content. This approach, characterized by quick, often subconscious assessments, proved significantly less accurate in studies assessing viewers’ ability to distinguish between real and artificially created footage. Participants employing intuition tended to focus on superficial details or emotional responses, leading to misidentification when subtle anomalies – those detectable through more deliberate analysis – were present. The research suggests that a dependence on ‘gut feelings’ can be easily misled by the increasing sophistication of AI video generation, particularly as algorithms become more adept at mimicking natural visual cues and human behaviors, potentially causing viewers to accept fabricated content as authentic.
A significant majority of participants, specifically 25 out of 40 individuals involved in the AI detection tasks, actively employed a deliberate, analytical approach – termed a ‘logic’ strategy – to discern AI-generated content. This suggests that, when confronted with visual media, people don’t simply rely on gut feelings; instead, they tend to systematically search for inconsistencies or anomalies that might betray artificial origins. The prevalence of this logical approach highlights a natural human tendency towards critical assessment, even when presented with seemingly realistic imagery, and indicates a potential pathway for developing more effective detection tools that leverage this innate cognitive process.
Analysis of eye-tracking data revealed a significant correlation between cognitive strategy and visual exploration patterns; participants employing a ‘logic’ strategy – actively seeking inconsistencies or artifacts – demonstrated notably shorter saccade magnitudes (p<0.05). This suggests a more focused and efficient visual search, where attention is concentrated on specific details rather than broad scanning of the video frame. The reduced distance of these rapid eye movements indicates that individuals utilizing a logical approach quickly pinpointed and assessed potential anomalies, requiring less extensive visual exploration to arrive at a judgement regarding AI-generated content. This efficient processing contrasts with the broader, less-directed eye movements observed in participants relying on intuition, highlighting the neurological basis for the superior accuracy of the logical strategy.
The robustness of detection strategies was assessed through the utilization of diverse video content, specifically physics demonstrations and professionally-edited clips. This approach aimed to move beyond the limitations of studying AI-generated videos in isolation, and to establish whether observed patterns – namely, the effectiveness of logical anomaly detection – held true across different visual complexities and production qualities. Results indicated consistent application of logical strategies regardless of video type, suggesting that the cognitive processes involved in identifying AI-generated content aren’t specific to particular aesthetic or thematic features. The use of both highly-structured physics videos and polished, professionally-edited content strengthens the claim that these findings represent a generalizable principle of human perception when confronting synthetic media.
The advent of sophisticated video generation models, particularly Google’s Veo, poses a significant hurdle to current AI detection techniques due to its capacity for producing remarkably realistic content. However, recent investigations demonstrate promising initial success in discerning Veo-generated videos from authentic footage. While existing methods struggle with the subtle inconsistencies often present in AI-generated visuals, a strategic approach focused on actively searching for anomalies-rather than relying on intuitive assessments-yields improved identification rates. This suggests that, despite the increasing sophistication of generative AI, targeted analytical techniques can still effectively reveal the fingerprints of artificial creation, offering a crucial step towards maintaining authenticity in the digital video landscape.
The study’s findings illuminate how human perception isn’t passively accepting visual input, but actively interrogating it. This resonates deeply with a sentiment expressed by Linus Torvalds: “Talk is cheap. Show me the code.” Similarly, simply watching a video isn’t enough; the brain instinctively attempts to ‘debug’ the reality presented. The research demonstrates that gaze patterns shift not based on whether a video is AI-generated, but on the viewer’s conscious effort to discern its authenticity – a process of reverse-engineering the visual information to understand its underlying construction. This aligns with a core tenet: true understanding comes from dissecting and challenging systems, not merely observing them.
Beyond the Turing Test: Gaze as a Reverse-Engineering Tool
The study’s most subtle exploit of comprehension isn’t revealing whether humans can detect AI-generated scenes, but that the very act of trying reshapes visual attention. The gaze isn’t a passive recorder of reality; it becomes an active probe, systematically dismantling the visual field in search of inconsistencies. This suggests that focusing on detection rates alone misses a critical point: the cognitive architecture deployed during scrutiny is itself informative. Future work should abandon the binary ‘real’ versus ‘fake’ and instead map the specific gaze strategies associated with different types of analytical approaches – what features trigger heightened examination, and how does that differ based on prior belief?
The implication is not merely about improving AI realism, but about understanding the human visual system as a kind of adversarial network, constantly building and testing internal models of the world. Current metrics of ‘realism’ are, fundamentally, attempts to bypass this internal scrutiny, to fool the system rather than understand it. A more fruitful avenue lies in intentionally provoking that scrutiny – designing AI-generated content specifically to reveal the limits of human perception and the heuristics employed in constructing visual reality.
Ultimately, the question isn’t whether AI can mimic reality, but whether analyzing how humans attempt to deconstruct AI-generated content can reverse-engineer the processes underlying genuine visual comprehension. This is less about building better simulations and more about dissecting the observer, turning the gaze itself into the primary subject of inquiry.
Original article: https://arxiv.org/pdf/2602.03374.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-05 02:09