Author: Denis Avetisyan
A new reinforcement learning system allows four-legged robots to dramatically improve long-distance travel by strategically using personal transportation platforms.
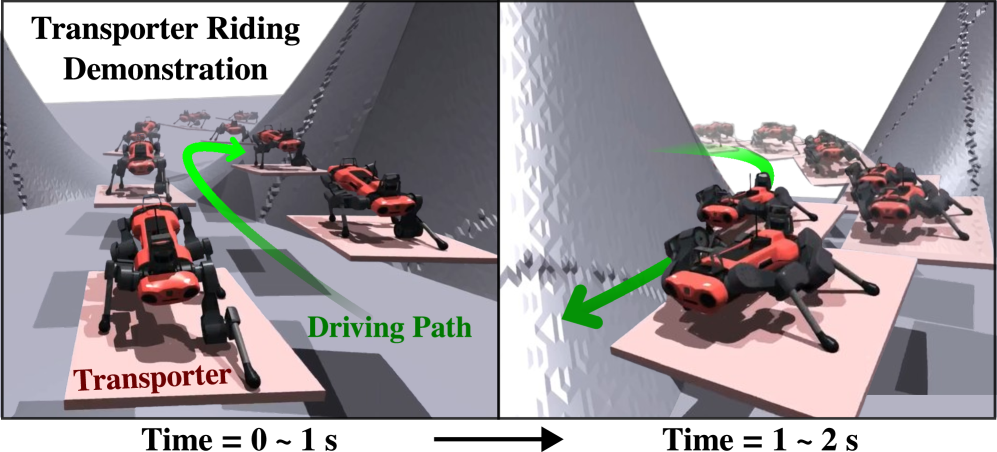
This work details a reinforcement learning-based approach (RL-ATR) enabling quadruped robots to leverage transporters for enhanced speed and energy efficiency during locomotion.
While quadruped robots offer versatile locomotion, their legged gait presents limitations in long-range efficiency and energy expenditure. This paper, ‘Enhancing Navigation Efficiency of Quadruped Robots via Leveraging Personal Transportation Platforms’, introduces a novel Reinforcement Learning-based Active Transporter Riding method (RL-ATR) inspired by human use of personal transporters. The RL-ATR enables these robots to strategically utilize transporters, demonstrably reducing energy consumption and improving navigational speed compared to purely legged locomotion. Could this approach unlock expanded operational ranges and broaden the application of quadruped robots in diverse environments?
The Imperative of Efficient Locomotion
Quadruped robots have demonstrated remarkable progress in navigating complex environments using legged locomotion, yet sustaining both balance and energetic efficiency across varied terrain presents a persistent hurdle. The inherent instability of dynamic walking, compounded by unpredictable ground conditions like slopes, rocks, or loose soil, demands continuous adjustments and substantial energy expenditure. Maintaining stable gaits requires precise coordination of multiple joints and rapid feedback control, placing significant strain on actuators and power systems. This challenge is particularly acute when robots are tasked with carrying payloads or operating for extended durations, as the energetic cost of locomotion quickly limits operational range and payload capacity. Consequently, improvements in balance control and efficient gait planning are crucial for unlocking the full potential of these robots in real-world applications.
Conventional quadrupedal robots often face limitations due to the substantial energetic demands of dynamic locomotion. Each step, turn, and adjustment to uneven terrain requires considerable power, quickly depleting onboard energy sources and curtailing operational time. This energetic cost isn’t merely a matter of battery life; it directly impacts the robot’s payload capacity, as a larger battery adds weight and further increases energy consumption. The complex interplay between joint torques, body posture, and ground reaction forces inherent in legged movement creates inherent inefficiencies, hindering the deployment of these robots in real-world scenarios demanding prolonged operation or substantial carried loads. Minimizing this energetic burden is, therefore, critical for expanding the practical applications of quadrupedal robots.
Researchers are exploring hybrid locomotion systems, specifically integrating mobile transporters with quadruped robots to dramatically improve energetic efficiency. This approach acknowledges the limitations of purely legged movement across challenging terrain, where maintaining balance and coordinating complex gaits consumes substantial energy. Studies reveal that by offloading a portion of the payload onto a separate, independently mobile platform, the quadruped robot experiences a marked reduction in the cost of transport – the energy expended to move a given mass over a specific distance. This synergistic combination allows the robot to focus its energy on navigating obstacles and maintaining stability, while the transporter handles the bulk of the load, ultimately extending operational endurance and increasing payload capacity beyond the capabilities of legged locomotion alone.
![Transporter riding tasks utilize coordinate frames for the robot body ([latex]\mathcal{B}[/latex]), platform ([latex]\mathcal{P}[/latex]), and world ([latex]\mathcal{W}[/latex]), alongside entities representing the robot body (BB) and multiple platforms (PP, PRP\_{R}, PLP\_{L}), to manage foot contact forces ([latex]\mathbf{f}_{c}[/latex]) and their relative positions ([latex]\mathbf{r}_{c}[/latex]).](https://arxiv.org/html/2602.03397v1/x2.png)
Reinforcement Learning: A Principled Approach to Mobile Manipulation
RL-ATR (Reinforcement Learning-based Active Transporter Riding) is a method designed to allow quadruped robots to dynamically utilize a moving transporter platform. This system employs reinforcement learning algorithms to enable autonomous operation while riding the transporter, effectively extending the robot’s operational range and capabilities. The core functionality centers on the robot’s ability to maintain stability and navigate while the transporter is in motion, requiring the development of control policies that account for the dynamic interplay between the robot’s movements and the transporter’s trajectory. RL-ATR differs from traditional methods by enabling the robot to actively adapt to varying transporter speeds and directions without relying on pre-defined paths or external tracking systems.
RL-ATR employs reinforcement learning to develop control policies for quadruped robots utilizing a transporter, focusing on the dynamic interaction between the two systems. The implemented algorithms enable the robot to learn optimal actions – including stepping, balancing, and adjusting to transporter movements – through trial and error, maximizing successful completion of assigned tasks. This learning process results in policies that are robust to variations in transporter dynamics, robot parameters, and environmental conditions. Specifically, the system learns to coordinate the robot’s locomotion with the transporter’s motion, achieving stable and efficient transportation across diverse terrains and scenarios without requiring explicit modeling of the combined system’s dynamics.
RL-ATR employs curriculum learning via a method termed ‘Command Scheduling’ to enhance training efficiency and resultant performance. This technique systematically increases task complexity during the reinforcement learning process. Initial training phases involve simpler commands and shorter traversal distances, gradually progressing to more complex maneuvers and extended operational ranges. This progressive approach accelerates learning by allowing the robot to first master fundamental skills before tackling more challenging scenarios. Empirical results demonstrate that Command Scheduling leads to significantly improved command area coverage – the proportion of a designated area the robot can successfully navigate – across diverse quadruped robot and transporter combinations, exceeding performance achieved with non-curriculum-based training methods.
![The Reinforcement Learning-based Active Transporter Riding Method (RL-ATR) utilizes a framework integrating simulation, systematic task difficulty scheduling, policy optimization, and an active riding policy-with training components highlighted in red, deployment components in yellow, and shared components in both colors-to develop a robust riding policy [latex]\pi_{\theta}[/latex].](https://arxiv.org/html/2602.03397v1/x3.png)
High-Fidelity Simulation: A Foundation for Robust Control
The training of the Reinforcement Learning-based Autonomous Transport Robot (RL-ATR) controller is performed using a high-fidelity physics simulation hosted within the Isaac Gym environment. This simulation platform enables the creation of dynamically accurate scenarios and facilitates parallelization, significantly accelerating the training process. Isaac Gym leverages NVIDIA’s hardware capabilities to compute physics in parallel across multiple GPUs, allowing for the simulation of numerous robot instances concurrently. This approach is critical for efficiently exploring the state and action spaces required for robust RL training, and enables the development of policies that can be reliably transferred to a physical robot.
System Identification is a crucial process for creating accurate physics simulations used in reinforcement learning. It involves estimating the parameters that define a system’s dynamic behavior. For the RL-ATR controller, this means determining both intrinsic parameters – those inherent to the robot and transporter, such as mass, inertia, and joint friction – and extrinsic parameters, which describe interactions with the environment, like ground friction and contact damping. These parameters are not typically known a priori and require experimental data or specialized algorithms to estimate. Precise estimation of these parameters is essential for minimizing the discrepancy between simulation and reality, leading to more effective training of the RL controller and improved transfer to real-world scenarios.
System identification utilizes both intrinsic and extrinsic estimators to create a high-fidelity simulation. Intrinsic estimators focus on parameters inherent to the robot and transporter, such as mass, inertia, and joint friction. Extrinsic estimators, conversely, quantify external factors influencing dynamics, including ground friction and contact characteristics. By simultaneously estimating these intrinsic and extrinsic parameters through techniques like Bayesian optimization and Kalman filtering, the simulation accurately captures the complex interplay of forces and dynamics. This results in a model with relatively low prediction errors – typically within a few percent – which is crucial for the effective training of the RL-ATR controller and successful transfer to real-world scenarios.
The high-fidelity simulation, generated through system identification, enables efficient training of the Reinforcement Learning-based Autonomous Transport Robot (RL-ATR) controller by facilitating a large number of parallel simulations. This scalability is achieved through vectorized physics computations within the Isaac Gym environment, reducing the time required for the RL agent to explore the state space and converge on an optimal policy. The resulting controller, trained in simulation with minimal prediction error, exhibits improved transferability to real-world scenarios, reducing the need for extensive real-robot fine-tuning and accelerating the deployment process. This approach significantly lowers the computational cost and time associated with developing robust robotic control systems.
Harnessing Physical Principles: Dynamics and Control
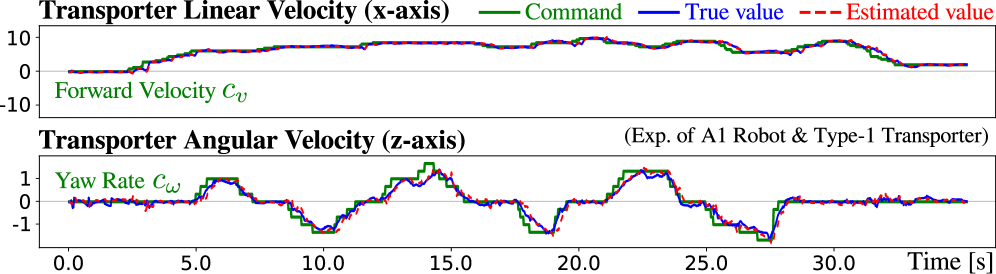
The robot’s dynamic movements are orchestrated through a sophisticated control system leveraging ‘Velocity Command’ signals. These signals don’t simply dictate speed; they function as a precise language between the quadruped robot and its mobile transporter, ensuring synchronized and efficient locomotion. By carefully coordinating the velocities of both platforms, the system overcomes the challenges of maintaining stability while in motion – effectively distributing forces and minimizing energy expenditure. This approach allows the robot to navigate varied terrains and adapt to changing conditions with remarkable agility, extending operational range and improving overall performance compared to systems relying on independent movement of the robot alone. The controller anticipates and compensates for shifts in the combined center of mass, resulting in fluid, balanced, and remarkably energy-efficient transport.
Effective control of a dynamically moving quadruped robot, such as one integrated with a mobile transporter, fundamentally depends on applying principles of physics, most notably Newton’s Laws of Motion. These laws govern how forces influence the robot’s acceleration, velocity, and overall trajectory; accurate prediction of these effects is crucial for stable locomotion. Furthermore, the effects of inertial forces – resistance to changes in motion – are paramount; a robot’s mass and velocity directly impact the forces required for stabilization. Ignoring these forces results in instability and inefficient movement, whereas precise calculation and compensation-through control algorithms-enable the robot to maintain balance and navigate complex terrains. Consequently, a strong grounding in physics is not merely theoretical but directly translates into enhanced robotic performance and energy efficiency.
A quadruped robot’s ability to maintain balance during locomotion hinges on a precise understanding of its physical properties, specifically the location of its [latex]Center\, of\, Mass[/latex]. This point represents the average location of the robot’s weight distribution, and its careful calculation is paramount for stability. The robot doesn’t attempt to eliminate all forces, but rather controls them to ensure they sum to zero at the [latex]Zero\, Moment\, Point[/latex] – the point of contact between the robot’s foot and the ground. By keeping this point aligned with the center of mass, the robot avoids generating torques that would cause it to tip over. This principle allows for dynamic balancing, enabling the robot to navigate uneven terrain and recover from disturbances while minimizing energy expenditure and maximizing operational endurance.
The fusion of robotic locomotion with external transport represents a substantial leap in energy conservation for quadruped robots. Traditional legged movement demands considerable energy expenditure simply to overcome inertia and maintain balance with each step; however, by strategically offloading weight and leveraging the momentum of a mobile transporter, the robot dramatically reduces its individual energy needs. This integrated system doesn’t merely assist movement, but fundamentally alters the energetic equation, resulting in demonstrably lower ‘cost of transport’ – the energy required to move a given mass over a specific distance. Studies reveal significant gains in operational endurance, allowing the robot to traverse longer distances and perform tasks for extended periods before requiring recharge, potentially unlocking applications previously limited by power constraints.
![An ablation study using heatmaps and command area graphs reveals that combined tracking errors for both forward ([latex]cvc_v[/latex]) and angular ([latex]cωc_{\omega}[/latex]) velocity commands are consistent across the A1 robot and type-1 transporter.](https://arxiv.org/html/2602.03397v1/x7.png)
The pursuit of efficient locomotion, as demonstrated by this work on quadruped robots and personal transporters, echoes a fundamental principle of information theory. As Claude Shannon stated, “The most important thing in communication is to convey the message with the least amount of energy.” This research, leveraging reinforcement learning to optimize the robot’s gait and transport usage, directly addresses this minimization of ‘energy’ – in this case, energy expenditure during long-range navigation. The RL-ATR system effectively seeks the most concise ‘message’ – the fastest, most efficient path – by intelligently combining legged locomotion with the supplementary capability of a transporter. Let N approach infinity – what remains invariant is the need for elegant, provably optimal solutions, even amidst the complexities of dynamic systems and state estimation.
Where Do We Go From Here?
The demonstrated symbiosis between quadrupedal locomotion and external transport platforms, while logically sound, merely scratches the surface of a deeper, more fundamental challenge. The reliance on reinforcement learning, a method inherently reliant on empirical observation, introduces a degree of stochasticity that is, frankly, unsettling. A truly elegant solution demands a deterministic underpinning – a provable control law guaranteeing stability and efficiency, rather than a system that ‘works well’ on a given training set. The current approach feels less like engineering and more like a sophisticated form of trial and error.
Future work must address the limitations of state estimation in complex, real-world scenarios. The fidelity of the robot’s perception directly dictates the reliability of the control system; errors propagate exponentially when dealing with dynamic systems. Furthermore, the question of generalization remains. Can a control policy trained on a specific transporter platform be seamlessly transferred to another? Or are we destined to perpetually retrain algorithms for each new iteration of personal mobility devices?
Ultimately, the pursuit of efficient quadrupedal navigation is not simply about speed or energy conservation. It is about achieving a level of predictability and robustness that transcends the limitations of purely data-driven methods. Until the algorithms can be formally verified – until the behavior is demonstrably correct rather than merely effective – the endeavor remains, at best, incomplete.
Original article: https://arxiv.org/pdf/2602.03397.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-04 21:05