Author: Denis Avetisyan
A new architecture, Kimi K2.5, is pushing the boundaries of artificial intelligence by enabling machines to learn from both text and vision, and coordinate complex tasks in parallel.

Kimi K2.5 integrates multimodal learning, agent swarms, and optimized reinforcement learning to achieve state-of-the-art performance in complex problem-solving.
Despite advancements in artificial intelligence, achieving truly general agentic capabilities requires synergistic processing of diverse information streams. This is addressed in ‘Kimi K2.5: Visual Agentic Intelligence’, which introduces a novel multimodal model optimized for both text and vision through techniques including joint pre-training and reinforcement learning. The resulting Kimi K2.5, coupled with its Agent Swarm framework for parallel task decomposition, achieves state-of-the-art performance across coding, reasoning, and vision-language tasks-reducing latency by up to [latex]4.5\times[/latex] compared to single-agent approaches. Will this integrated approach pave the way for more adaptable and efficient AI systems capable of tackling increasingly complex real-world challenges?
The Limits of Disjoint Representation
Contemporary artificial intelligence systems frequently analyze textual and visual information through distinct, isolated pathways, creating a fundamental barrier to holistic comprehension. This separation prevents the AI from establishing the crucial connections between what is described and what is seen – a skill effortless for humans. Consequently, these systems struggle with tasks requiring integrated reasoning, such as answering questions that necessitate understanding both the content of an image and accompanying text. The inability to synthesize information across modalities limits performance on complex challenges and hinders the development of truly intelligent systems capable of contextual awareness and genuine understanding, rather than merely pattern recognition within individual data streams.
Truly intelligent artificial intelligence demands more than simply processing different data types – it necessitates a unified cognitive architecture capable of seamlessly integrating and reasoning across modalities. Current systems often treat text and visual information as independent inputs, limiting their ability to draw connections and perform complex inference. A robust framework facilitates cross-modal inference, allowing the system to, for instance, understand the relationship between a textual description and a corresponding image, or predict what might happen next in a video based on prior knowledge gained from textual sources. Crucially, this unified approach also enables effective knowledge transfer; insights derived from analyzing text can enrich the interpretation of visual data, and vice versa, leading to a more comprehensive and nuanced understanding of the world – a capability essential for advanced reasoning and problem-solving.
Processing multimodal data – combining information from sources like text, images, and audio – presents significant computational hurdles for traditional artificial intelligence systems. These challenges stem from the exponential growth in data dimensionality as modalities are added; each new input stream dramatically increases the number of parameters a model must learn and the processing power required for analysis. Existing architectures often rely on processing each modality independently before attempting integration, creating bottlenecks and hindering the ability to capture nuanced relationships. Furthermore, the asynchronous nature of multimodal data – varying rates of data arrival and differing temporal resolutions – complicates synchronization and efficient feature extraction. Consequently, scaling these approaches to handle real-world complexity demands innovative techniques in model compression, distributed computing, and optimized data representation to overcome these inherent computational limitations.
![Training curves reveal that early fusion strategies employing lower vision-to-text ratios [10:90, 20:80, 50:50] consistently outperform those with higher ratios when operating under a fixed vision-text token budget across both vision and language tasks.](https://arxiv.org/html/2602.02276v1/x7.png)
Kimi K2.5: A Unified Architecture for Multimodal Reasoning
Kimi K2.5 employs a novel architecture distinguished by its upfront, joint optimization of text and vision modalities during pre-training. Unlike conventional approaches that process these modalities separately and fuse them at a later stage, Kimi K2.5 integrates them from the initial layers. This is achieved through a shared embedding space and cross-attention mechanisms that allow for bidirectional information flow between the textual and visual inputs. The architecture’s design enables gradients to flow directly between modalities during training, fostering a more cohesive and nuanced understanding of cross-modal relationships and facilitating improved feature extraction for downstream tasks.
Late-stage fusion techniques in multimodal models typically process text and visual data independently before combining representations in later layers. This approach can limit the model’s ability to establish intricate relationships between modalities during initial processing. Kimi K2.5, conversely, employs joint optimization that fuses text and vision modalities from the beginning of the network. This enables the model to learn cross-modal interactions at a granular level, fostering a deeper understanding of the relationships between visual and textual information and improving reasoning capabilities that require integrated multimodal comprehension.
Kimi K2.5 utilizes Native Multimodal Pre-training, a process wherein the model learns text and visual representations concurrently from the outset, rather than integrating them at a later stage. This approach establishes a foundational understanding of the relationships between modalities, creating robust multimodal representations that facilitate advanced reasoning. Evaluations demonstrate that Kimi K2.5 achieves state-of-the-art performance on diverse agentic tasks – those requiring autonomous action and decision-making – and standard multimodal benchmarks, including image and video understanding, visual question answering, and cross-modal retrieval.
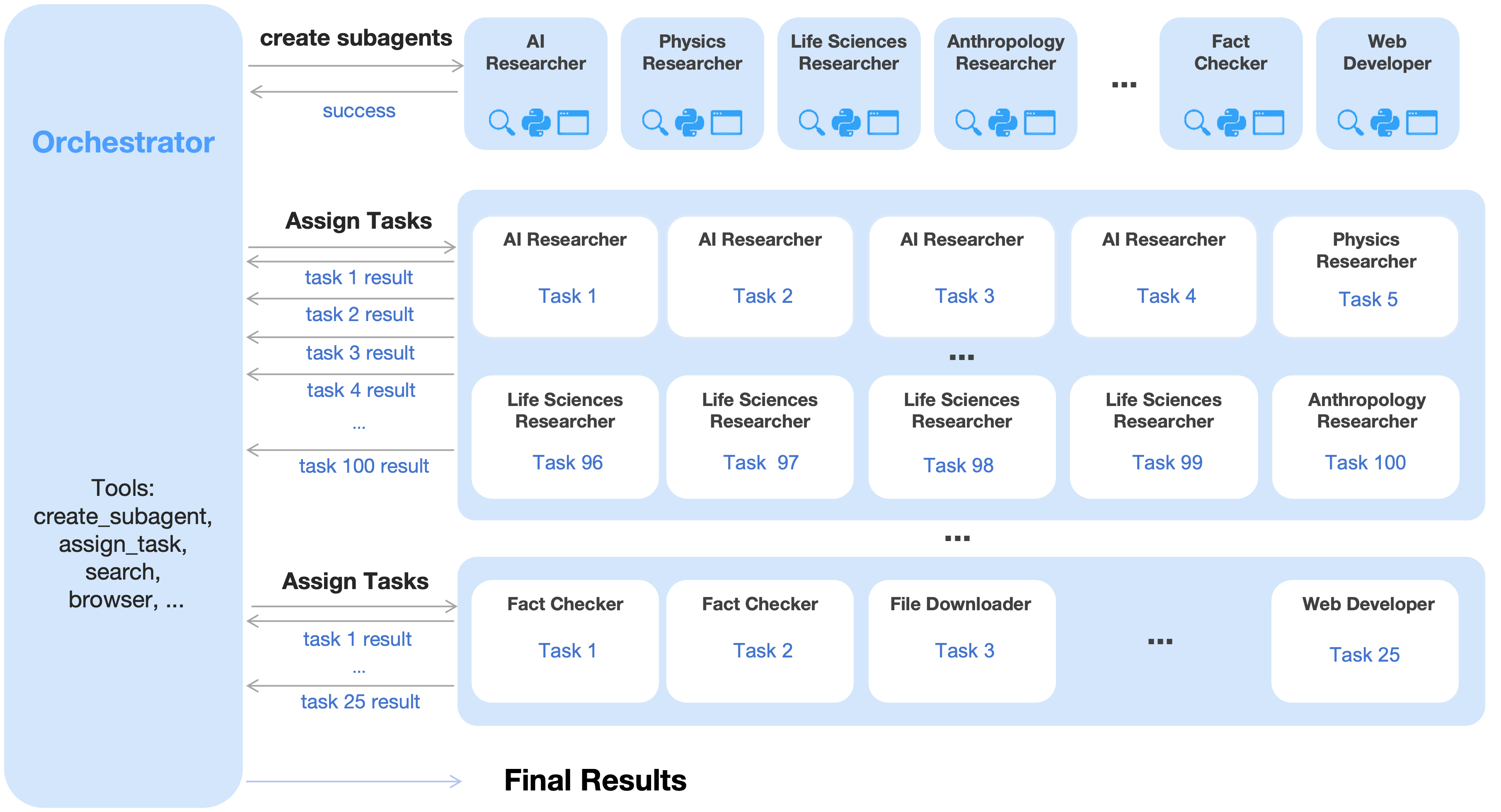
Orchestrated Parallelism: Scaling Intelligence Through Agent Swarms
Agent Swarm, the parallel agent orchestration framework utilized in Kimi K2.5, functions by dissecting complex tasks into smaller, independent subtasks. These subtasks are then dynamically assigned to a diverse pool of specialized agents, each designed for optimal performance on a specific type of operation. This decomposition and distribution strategy enables concurrent processing, maximizing computational resources and allowing for a more efficient overall execution flow. The framework manages agent communication and coordination, ensuring that individual agent outputs are integrated effectively to achieve the original task objective.
Parallel Agent Reinforcement Learning (PARL) is the foundational methodology enabling Kimi K2.5’s Agent Swarm to achieve coordinated behavior. Unlike traditional reinforcement learning which focuses on a single agent, PARL allows multiple agents to learn and interact concurrently within a shared environment. This is achieved by distributing the learning process and enabling agents to specialize in sub-tasks, fostering a division of labor. Crucially, PARL incorporates mechanisms for inter-agent communication and coordination, allowing agents to share information and adjust their actions based on the behavior of others, ultimately leading to more efficient task completion and improved overall system performance.
Performance gains in Kimi K2.5 are achieved through the implementation of several parallelization techniques. Data Parallelism replicates the model across multiple devices, processing different data batches concurrently. Expert Parallelism distributes the workload across specialized agents, each trained on a specific subset of tasks. Selective Recomputation optimizes training and inference by recomputing only necessary parts of the computation graph, reducing redundant calculations. Benchmarking on WideSearch demonstrates a 3.0x to 4.5x reduction in execution time when utilizing these parallelization strategies compared to single-agent baseline models.
Emergent Autonomy: Reasoning and Tool Use in Kimi K2.5
Kimi K2.5 exhibits a significant leap in agentic capabilities, moving beyond simple task completion to demonstrate genuine autonomy and proactive problem-solving within intricate digital landscapes. This advancement isn’t merely about responding to prompts, but rather about the model independently identifying goals, formulating plans, and executing those plans with minimal external direction. The system navigates complex environments by dynamically assessing situations, anticipating potential challenges, and adapting its strategies accordingly. This proactive behavior is fueled by an internal reasoning engine that allows Kimi K2.5 to not only process information but to understand its implications, ultimately enabling it to act as a truly independent agent capable of pursuing objectives and overcoming obstacles without constant human intervention.
Kimi K2.5 distinguishes itself through a robust capacity for tool use, extending its problem-solving capabilities beyond inherent knowledge. This proficiency involves intelligently accessing and utilizing external APIs and resources – effectively transforming the model into an agent capable of dynamic information gathering and task execution. Rather than relying solely on its pre-trained parameters, Kimi K2.5 can, for example, search the web for current data, consult specialized databases, or employ external calculation tools as needed to address complex queries. This externalization of function allows the model to tackle tasks demanding up-to-date information or specialized expertise, and ultimately achieve superior performance on benchmarks requiring real-world knowledge and adaptability – as demonstrated by its leading results on challenges like BrowseComp and WideSearch Item-F1.
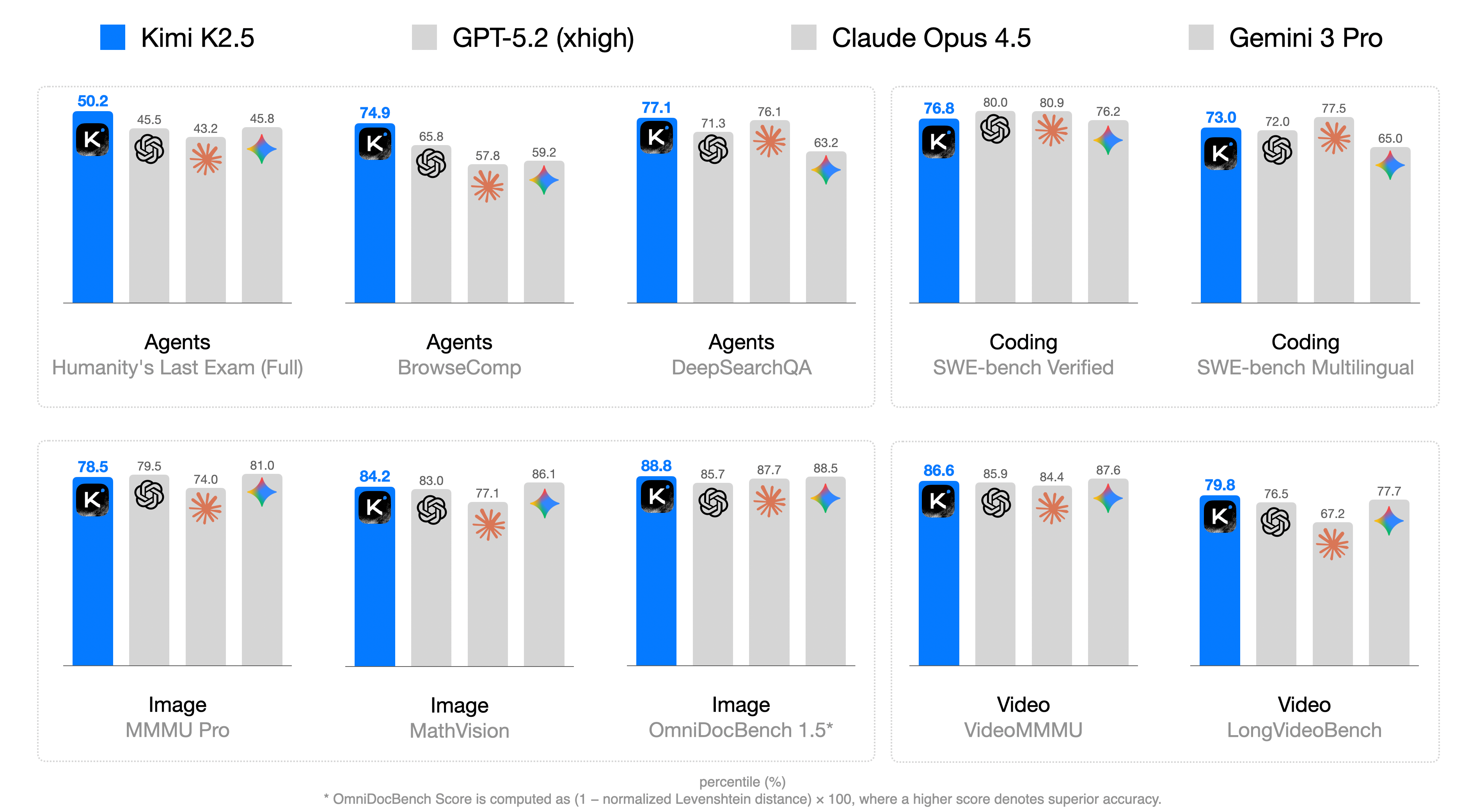
Evaluations demonstrate Kimi K2.5’s substantial advancement in complex reasoning and problem-solving capabilities. The model achieves state-of-the-art results across a range of challenging benchmarks, notably attaining 78.4% on the BrowseComp assessment – a significant 17.8% improvement over its single-agent predecessor. Performance extends to information retrieval, with a 79.0% score on WideSearch Item-F1, and substantial success in open-source world verification, reaching 63.3%. Further highlighting its capabilities, Kimi K2.5 surpasses both Gemini 3 Pro and GPT-5.2 with a 50.2% score on the HLE-Full benchmark, and exhibits exceptional performance in long-video understanding, achieving 79.8% on LongVideoBench, alongside leading results on GDPVal-AA, collectively establishing a new standard for agentic AI.
The pursuit of Kimi K2.5 exemplifies a dedication to provable intelligence, mirroring Robert Tarjan’s assertion that “Programmers often spend more time debugging than writing code.” While Kimi K2.5 aims to transcend simple task completion through agentic intelligence and multimodal learning, the underlying architecture demands rigorous validation. The Agent Swarm approach, coupled with optimized reinforcement learning, isn’t merely about achieving results; it’s about establishing a consistent, predictable system. The article highlights a shift from empirical ‘working’ solutions to demonstrably correct ones, echoing the need for algorithmic purity-a solution’s elegance isn’t in its speed, but in its mathematical foundation. This parallels Tarjan’s emphasis on correctness as the defining feature of quality code.
What Lies Ahead?
The architecture presented in Kimi K2.5, while demonstrably effective, merely relocates the fundamental challenge inherent in intelligence – the specification of axiomatic truth. Achieving state-of-the-art performance across a range of tasks does not, in itself, constitute understanding. The system excels at solving problems, but remains conspicuously silent regarding why those solutions are correct, beyond statistical correlation. Future work must therefore shift focus from simply increasing performance metrics to formal verification of agentic reasoning.
The parallel execution of agents, the ‘Agent Swarm’ concept, introduces a new class of complexity. While scalability is achieved, ensuring logical consistency across concurrently operating agents remains a significant hurdle. The temptation to view emergent behavior as intelligence is strong, but this is a category error. True intelligence demands provability, not just observed functionality. The field requires a robust framework for managing and validating the interactions within these swarms, beyond simple reward signaling.
Ultimately, the limitations of current vision-language models stem from their reliance on imperfect data. Kimi K2.5, and its successors, will be judged not by what it can do, but by its ability to identify the boundaries of its own knowledge. A truly intelligent agent acknowledges what it does not, and cannot, know – a humility conspicuously absent from most contemporary approaches. The pursuit of elegance lies not in complexity, but in logical completeness.
Original article: https://arxiv.org/pdf/2602.02276.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-04 05:39