Author: Denis Avetisyan
New research demonstrates that training robots with a wider range of data-including visual, linguistic, and cross-robot experiences-drastically improves their ability to generalize to new tasks.
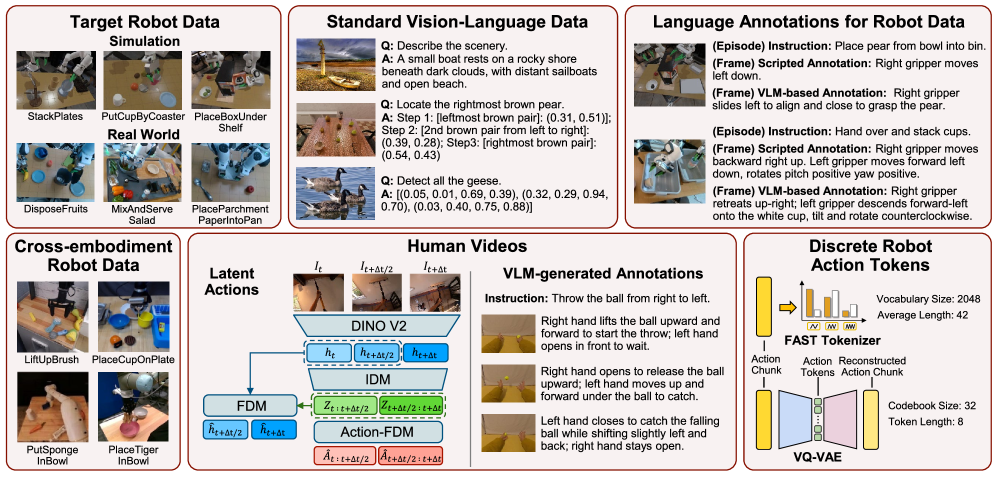
Co-training large behavior models with multi-modal data improves generalization in robot manipulation, while discrete action tokens offer limited gains.
Despite recent advances in large behavior models for robot manipulation, achieving robust generalization remains a key challenge due to limited data coverage. This limitation motivates the work ‘A Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation’, which systematically investigates the impact of diverse co-training data-including vision-language data, cross-embodiment robot data, and human videos-on policy performance. Our results, derived from an analysis of 4,000 hours of robot and human data and 50M vision-language samples, demonstrate that strategic co-training substantially improves generalization to unseen tasks and real-world scenarios, while discrete action tokens offer limited benefit. How can these findings inform the development of truly scalable and adaptable robot learning systems capable of tackling complex, long-horizon manipulation tasks?
The Limits of Embodiment: Why Robots Struggle to Adapt
Historically, robotics has faced significant hurdles in creating truly adaptable machines. A robot expertly programmed to perform one specific task – assembling a widget, for instance – often falters when presented with even a slight variation, like a differently shaped widget or a change in the assembly line’s configuration. This inflexibility stems from the reliance on painstakingly hand-engineered control systems tailored to a single robot body and a limited set of scenarios. Furthermore, a control program meticulously designed for one robotic morphology – a robot with a particular arm length and joint configuration – rarely translates successfully to a robot with different physical characteristics. This lack of generalization has long been a bottleneck, hindering the deployment of robots in dynamic, real-world environments where adaptability is paramount and requiring extensive, costly re-programming for each new task or robot type.
The pursuit of truly dexterous robotic manipulation is increasingly focused on Large Behavior Models, a paradigm shift leveraging the power of massive datasets to train robots in a manner analogous to large language models. However, realizing this potential hinges on developing efficient methods for representing robot actions. Traditional approaches to sequence modeling struggle to capture the intricacies of complex movements, leading to computational bottlenecks and limited generalization. Researchers are actively exploring novel action representations-including discrete action spaces, continuous control parameters, and hierarchical action primitives-to compress information without sacrificing expressiveness. This focus on efficient representation is crucial; it allows models to learn from larger datasets, generalize across diverse robotic platforms, and ultimately unlock the promise of robots capable of performing a wide range of tasks with human-like dexterity.
Existing sequence modeling techniques, commonly employed to predict a series of robot actions, often falter when confronted with the inherent complexity of real-world manipulation. These methods typically represent actions as discrete tokens or continuous parameters, struggling to capture the nuanced interplay between joint torques, end-effector trajectories, and environmental interactions that define dexterous behavior. The limitations stem from an inability to effectively model long-range dependencies within an action sequence – a robot’s current movement is heavily influenced by steps taken many time steps prior – and to generalize across variations in task parameters, such as object pose or approach angle. Consequently, current models require extensive task-specific training and exhibit limited transferability, hindering the development of truly adaptable and intelligent robotic systems capable of performing complex tasks in unstructured environments.
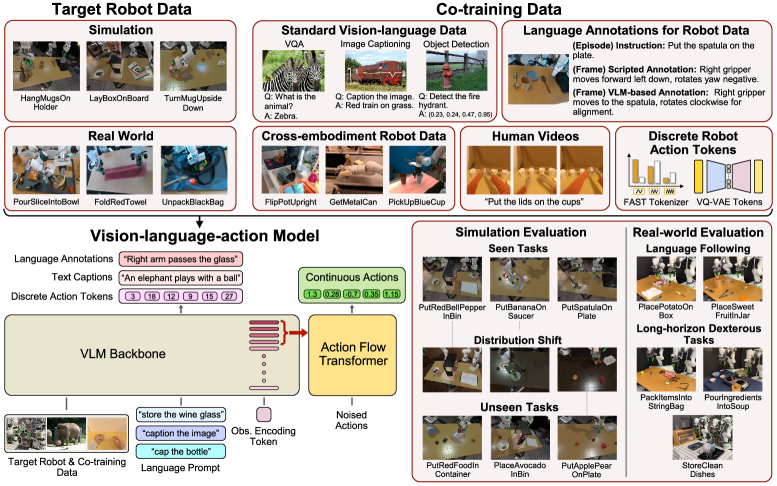
Discretization: A Pathway to Efficient Control
Representing continuous robot actions as discrete tokens facilitates the application of sequence modeling techniques, traditionally used for natural language processing, to robotic control. Continuous action spaces require robots to explore an infinite number of possibilities, posing challenges for learning algorithms. Discretization reduces this complexity by mapping continuous values to a finite set of actions, effectively transforming the control problem into a sequence prediction task. This allows the utilization of architectures like Transformers and Recurrent Neural Networks (RNNs) – proven effective in processing sequential data – to predict the next discrete action based on the robot’s state and history. Consequently, the robot learns a policy by modeling the probability distribution over these discrete action tokens, enabling efficient learning and generalization compared to methods operating directly in continuous spaces.
Techniques such as FAST (Forward and Inverse dynamics with Action Space Tokenization) and VQ-VAE (Vector Quantized Variational Autoencoder) facilitate the compression of high-dimensional, continuous control signals into a discrete action space. FAST achieves this by learning a discrete set of actions that, when executed by a dynamics model, can effectively reconstruct the original continuous control. VQ-VAE, conversely, utilizes an encoder to map continuous actions to a discrete latent space, and a decoder to reconstruct the original action from the discrete representation. Both methods reduce computational complexity by limiting the number of possible actions the agent must consider, thereby decreasing the dimensionality of the action space and enabling more efficient learning and inference, particularly when coupled with sequence modeling architectures.
Discretizing continuous action spaces facilitates the application of large-scale pre-trained sequence models, such as those commonly used in natural language processing, to robotic control tasks. These models, trained on extensive datasets, possess substantial representational capacity but typically require discrete input. By mapping continuous control signals to a finite set of tokens, robots can be treated as sequential data, allowing for transfer learning from these pre-trained models. This approach bypasses the need to train control policies from scratch, significantly reducing sample complexity and accelerating learning, particularly in complex, high-dimensional control problems. The resulting policies can then be executed by decoding the discrete actions back into continuous control signals for robot actuators.
Data Diversity: The Foundation of Robust Generalization
Co-training utilizes data from multiple robotic embodiments alongside existing datasets of human video demonstrations to improve model understanding of task execution. This approach capitalizes on the diversity of robot morphology and movement styles present in cross-embodiment data, complementing the semantic richness of human actions observed in video. By training on this combined dataset, the model learns a more robust and generalized representation of tasks, independent of specific robot hardware or human demonstration styles, thereby increasing its adaptability to new scenarios.
The integration of multiple data modalities – specifically, cross-embodiment robot data and human videos – is augmented by the application of dense language annotations to robot actions. These annotations provide detailed semantic information, linking visual observations to corresponding textual descriptions of the performed actions. This granular level of labeling facilitates a deeper understanding of the relationship between robot movements and their intended purposes, enabling the model to interpret actions beyond simple kinematic data. The resulting dataset establishes a strong correspondence between visual inputs and semantic meaning, which is critical for improving the model’s ability to generalize to novel tasks and robot morphologies.
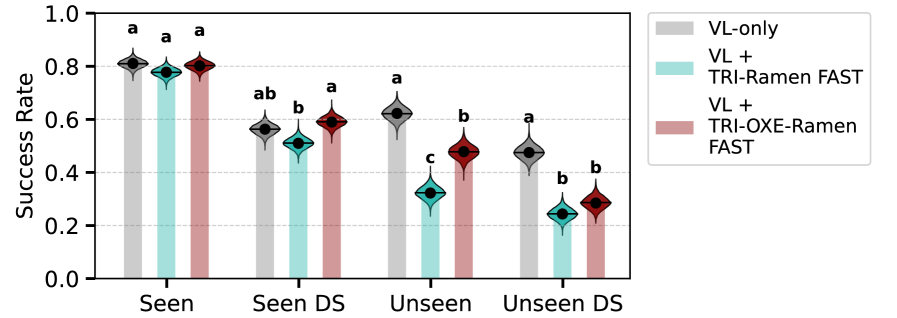
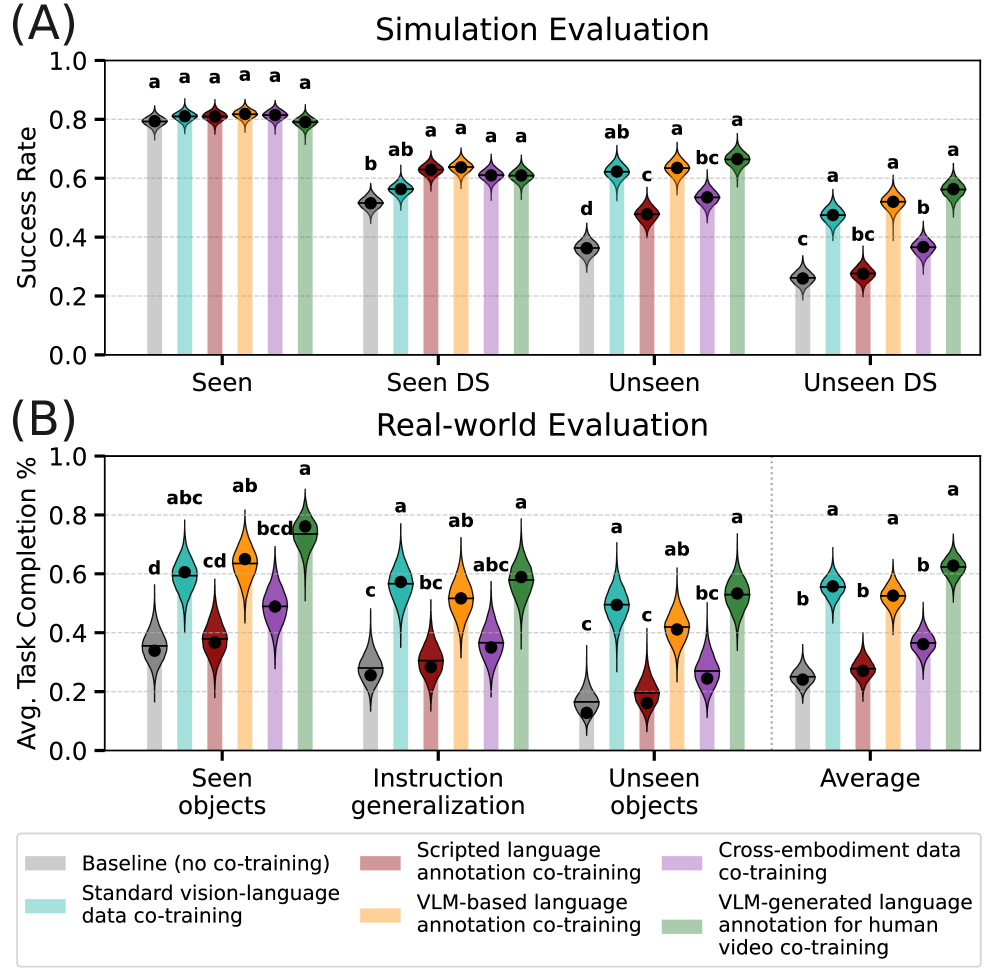
The proposed co-training methodology demonstrates substantial improvements in generalization capabilities, as evidenced by performance metrics on unseen tasks. Specifically, the system achieved a 72.6% success rate when evaluated on previously unencountered simulation scenarios. Furthermore, real-world performance indicates a 69.4% task completion rate when the robot followed language instructions, suggesting effective transfer of learned skills to physical environments and novel commands. These results highlight the efficacy of the approach in addressing challenges related to robot adaptability and robustness across varying morphologies and task demands.
Performance gains are realized through transfer learning by incorporating existing, publicly available vision-language datasets. Pre-training models on these large-scale datasets, which contain paired image and textual descriptions, establishes a foundational understanding of visual concepts and linguistic relationships. This pre-existing knowledge is then transferred to the co-training framework, allowing the model to more effectively learn from the comparatively limited robot and human demonstration data. The application of this transfer learning technique results in accelerated learning and improved generalization capabilities, particularly when dealing with novel tasks or environments.
Vision, Language, and Action: A Unified System for Intelligent Control
A novel approach to robotic control centers on the development of Vision-Language-Action (VLA) models, systems designed to interpret both visual data and natural language commands to execute complex tasks. These models move beyond simply recognizing objects or following pre-programmed sequences; instead, they establish a cohesive link between what a robot sees, what it is told to do, and the physical actions it undertakes. By jointly processing visual inputs – such as images or video feeds – and linguistic instructions, the system develops an understanding of the desired outcome. This understanding is then translated into a learned action policy, effectively guiding the robot’s movements and behaviors to successfully complete the requested task, opening possibilities for more intuitive and adaptable robotic systems.
The generation of fluid, natural robot movements benefits from a novel approach combining the Action Flow Transformer with Flow Matching techniques. This system translates discrete action tokens – representing high-level commands – into a continuous stream of motor commands, enabling robots to perform tasks with greater dexterity and precision. The Action Flow Transformer processes these tokens, learning the relationships between commands and desired motions, while Flow Matching refines this output into a smooth, physically plausible trajectory. By framing action generation as a continuous process rather than a series of discrete steps, the system avoids the “jerky” movements often associated with robotic control, instead producing actions that are more organic and efficient. This method allows for intricate task completion and adaptation to dynamic environments, representing a significant advancement in robot control systems.
The system’s ability to plan and make decisions is significantly improved by integrating Chain-of-Thought (CoT) reasoning directly into the Action Flow Transformer. This approach moves beyond simply responding to instructions; instead, the model explicitly generates intermediate reasoning steps before determining an appropriate action. By articulating its thought process – breaking down complex tasks into smaller, manageable sub-goals – the system demonstrates a greater capacity for handling novel situations and generalizing to unseen scenarios. This internal deliberation allows for more robust action selection, mitigating errors that might arise from directly mapping instructions to actions, and ultimately leading to more reliable and adaptable robotic behavior. The inclusion of CoT effectively transforms the model from a reactive agent into a proactive planner, capable of anticipating consequences and optimizing for long-term goals.
The foundation of effective vision-language-action integration often lies in utilizing pretrained vision-language models. Models such as PaliGemma2-PT offer a significant advantage by already possessing a robust understanding of visual concepts and linguistic relationships, effectively circumventing the need to learn these fundamental associations from scratch. This pre-existing knowledge is then transferred and fine-tuned for the specific task of robotic control, drastically reducing training time and data requirements. By building upon this established base, the system can focus on mastering the nuances of action generation and policy learning, leading to improved performance and adaptability in complex environments. Essentially, the pretrained model acts as a powerful feature extractor and semantic interpreter, enabling the robot to bridge the gap between perception, language, and physical action with greater efficiency and precision.
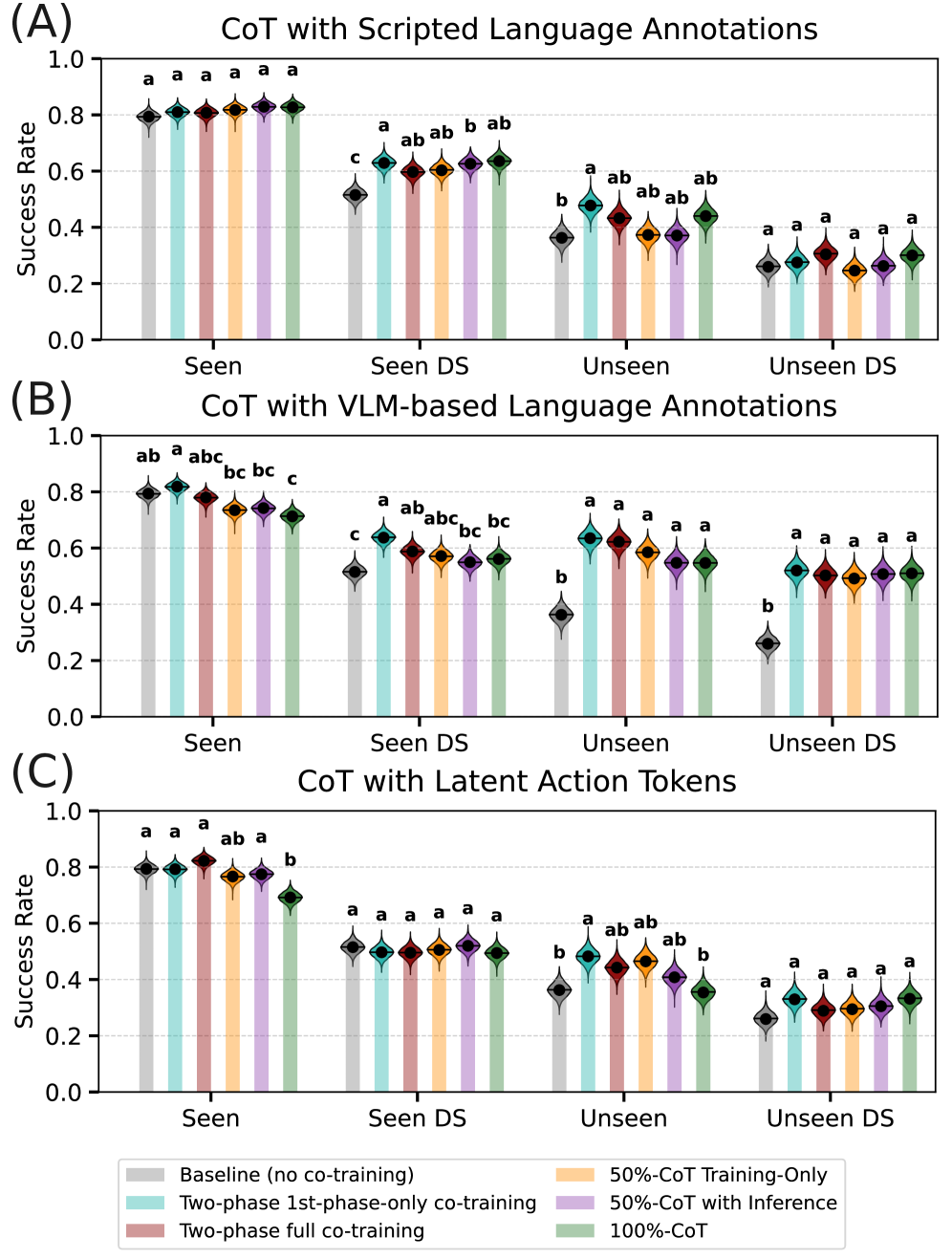
The pursuit of robust generalization in robotic manipulation, as detailed in this study, necessitates a rigorous approach to data integration. The research demonstrates that leveraging multi-modal data-vision, language, and diverse robotic experiences-yields demonstrable improvements. This aligns with Robert Tarjan’s assertion: “A fundamental property of algorithms is that they must terminate in a finite amount of time.” While seemingly unrelated, the principle applies here; the algorithm-the behavior model-achieves ‘termination’ of ambiguity through comprehensive data, resolving uncertainty and enabling effective performance in novel situations. The focus on co-training and diverse modalities isn’t about accumulating complexity, but rather about refining the signal, achieving clarity in the model’s understanding of manipulation tasks.
Further Refinements
The demonstrated efficacy of multi-modal co-training invites scrutiny of the information actually transferred. Current methodologies aggregate data; future work must dissect what is generalized, not merely that generalization occurs. A proliferation of modalities does not inherently equal comprehension. The pursuit of scale risks obscuring the essential – a parsimonious understanding of the minimal sufficient data for robust robotic behavior. Unnecessary is violence against attention.
The limited benefit observed from discrete action tokens suggests a fundamental mismatch between current symbolic representations and the continuous nature of robotic control. Rather than forcing behavior into pre-defined categories, investigation should prioritize learning representations that directly map observations to continuous actions. The emphasis should shift from token prediction to trajectory optimization – a move toward intrinsic understanding, rather than superficial mimicry.
Finally, the question of embodiment remains. Cross-embodiment training offers a degree of robustness, but true generalization requires navigating the infinite variety of the real world. Density of meaning is the new minimalism. The challenge is not simply to train robots to perform tasks, but to imbue them with the capacity to learn how to learn – a meta-cognitive ability currently absent from even the most sophisticated systems.
Original article: https://arxiv.org/pdf/2602.01067.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-03 21:21