Author: Denis Avetisyan
A new framework empowers artificial intelligence agents to conduct extended, iterative research by leveraging a file-system workspace to overcome the limitations of short-term memory.
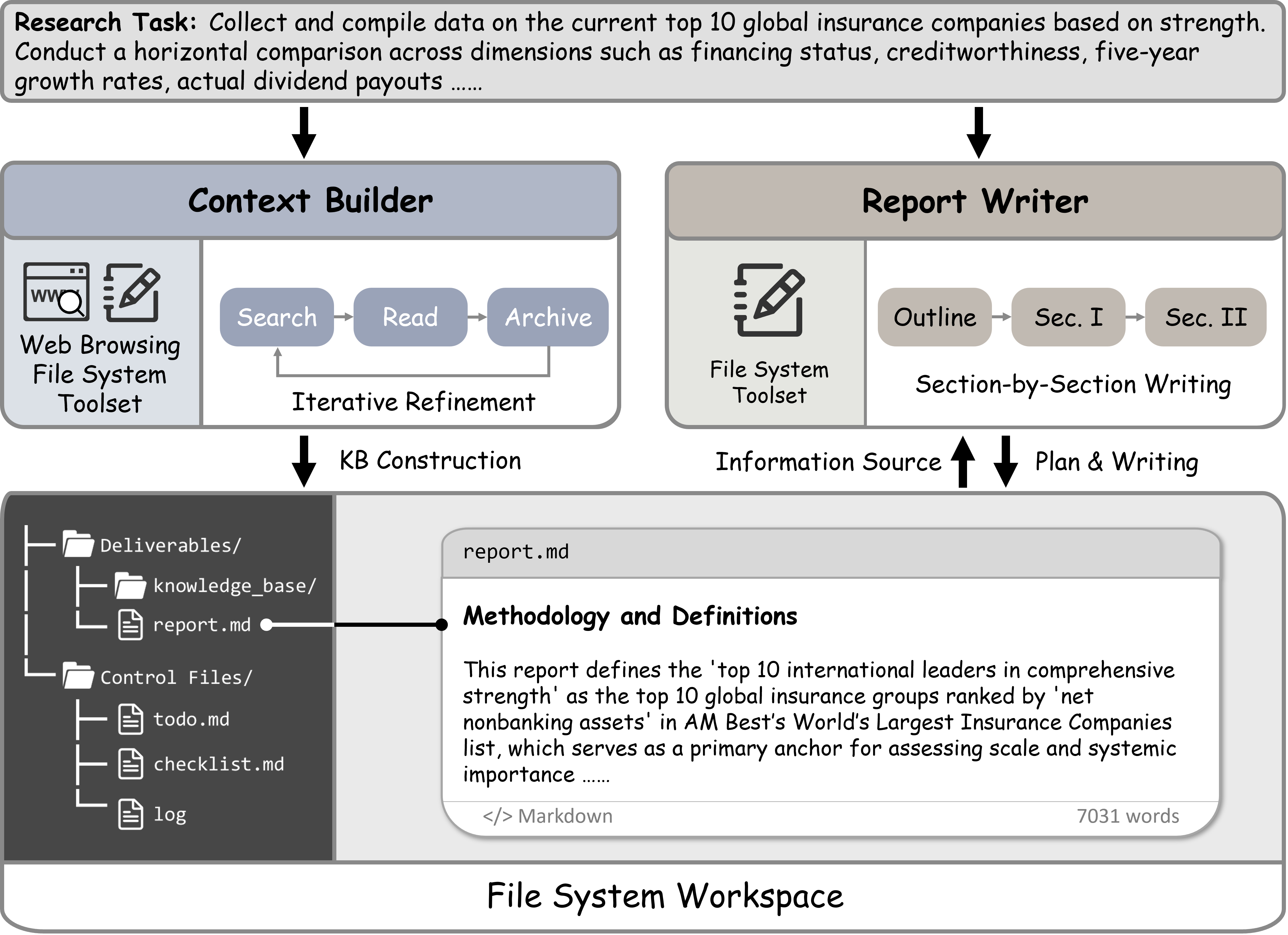
FS-Researcher utilizes a dual-agent system and a file-system-based knowledge base to enable long-horizon deep research tasks.
Long-horizon tasks like deep research present a fundamental challenge for large language models: limited context windows constrain effective evidence collection and report synthesis. To address this, we introduce FS-Researcher: Test-Time Scaling for Long-Horizon Research Tasks with File-System-Based Agents, a dual-agent framework leveraging a persistent file-system workspace to extend reasoning beyond context limitations. This approach enables iterative refinement via a Context Builder agent archiving knowledge and a Report Writer agent composing reports, demonstrably improving performance on open-ended benchmarks. Could this file-system paradigm unlock more scalable and robust long-horizon reasoning capabilities for language model agents?
The Limits of Pattern Recognition: Deep Research and the Current Generation of LLMs
Current large language models, despite their impressive abilities, struggle with the demands of deep research – a process akin to the synthesis expected during doctoral-level study. This isn’t simply about accessing information; it requires critical evaluation of sources, nuanced integration of disparate ideas, and the creation of novel connections. LLMs often excel at identifying relevant texts, but fall short when tasked with discerning subtle arguments, identifying biases, or constructing a cohesive narrative from complex, often contradictory, material. The challenge lies in moving beyond pattern recognition and information retrieval towards genuine understanding and the ability to formulate original insights – a cognitive leap that remains largely beyond the capabilities of contemporary AI agents.
Large language models, despite their impressive capabilities, are fundamentally constrained by a limited context window – the maximum amount of text they can effectively process at one time. This limitation isn’t merely a technical detail; it profoundly impacts their ability to perform deep research, which inherently requires synthesizing information from extensive and interconnected sources. While models can access vast datasets, they can only actively consider a relatively small slice of that information when generating a response or drawing conclusions. Consequently, crucial details, nuanced arguments, or long-range dependencies within a research topic may be overlooked, leading to incomplete analyses or inaccurate syntheses. Innovative techniques are being explored to circumvent this limitation, such as retrieval-augmented generation and hierarchical processing, but effectively extending context length remains a central challenge in unlocking the full potential of LLMs for complex, knowledge-intensive tasks.
Conventional methodologies, often structured as static pipelines, struggle with the nuanced demands of sophisticated research tasks. These systems, designed for linear progression, lack the flexibility to incorporate new findings or adjust strategies mid-process. Unlike a human researcher who iteratively refines hypotheses and revisits sources, a static pipeline operates on a predetermined sequence, hindering its ability to address unexpected complexities or synthesize information from evolving datasets. This inflexibility proves particularly detrimental when dealing with ambiguous or incomplete information, where adaptive reasoning and the capacity to loop back through previous stages are crucial for accurate and comprehensive results. Consequently, these approaches often fall short in scenarios demanding not just information retrieval, but genuine intellectual synthesis and refinement.
![Deep research paradigms have evolved from static pipelines with limited context [latex]
ightarrow[/latex] trajectory-extended agents managing compressed observations [latex]
ightarrow[/latex] the FS-Researcher framework, which leverages an external file system to overcome context limitations.](https://arxiv.org/html/2602.01566v1/figs/paradigm_comparison.png)
ightarrow[/latex] trajectory-extended agents managing compressed observations [latex]
ightarrow[/latex] the FS-Researcher framework, which leverages an external file system to overcome context limitations.
FS-Researcher: Architecting a System for Extended Reasoning
FS-Researcher employs a dual-agent framework to mitigate the context length limitations inherent in Large Language Models (LLMs). This architecture separates the information gathering process from the report generation process. One agent, the Context Builder, is dedicated to proactively retrieving and structuring relevant information, storing it in a persistent Knowledge Base. A second agent, the Report Writer, then utilizes this Knowledge Base as its primary source of information, enabling the creation of comprehensive reports that exceed the typical context window of LLMs. This division of labor allows for extended reasoning capabilities by decoupling information access from report synthesis, effectively expanding the scope of information considered during report creation.
The Context Builder agent proactively gathers information relevant to a given research task and structures it within a Knowledge Base. This process involves iterative information retrieval and organization, prioritizing data that addresses identified knowledge gaps. Crucially, the agent employs a File System Workspace to ensure data persistence between reasoning cycles; retrieved documents and processed information are stored as files, enabling the agent to recall and build upon previous findings without reliance on the LLM’s limited context window. This persistent storage allows for extended reasoning capabilities and the accumulation of a comprehensive knowledge repository throughout the research process.
The Report Writer agent constructs a final report by directly accessing and synthesizing information stored within the Knowledge Base created by the Context Builder agent. This process bypasses the limitations of the LLM’s original context window, allowing for the incorporation of a significantly larger dataset than would otherwise be possible. The agent employs the ReAct framework to iteratively reason about the information retrieved from the Knowledge Base and refine the report’s content, ensuring accuracy and coherence. The resulting report represents a synthesis of the gathered data, presented in a structured and informative manner, and is solely dependent on the contents of the maintained Knowledge Base for its factual basis.
Workflow and Quality Control: A System Designed for Rigor
FS-Researcher utilizes a Todo list system to direct the operational sequence of its agents. These Todos are discrete, actionable items that define specific research tasks, providing a structured workflow. Each Todo represents a defined step in the overall research process, and agents are designed to complete these items sequentially. This approach ensures a focused progression through the research, preventing agents from pursuing irrelevant lines of inquiry and maintaining a consistent, objective methodology. The system allows for the decomposition of complex research goals into manageable components, enhancing both efficiency and the quality of the resulting deliverables.
FS-Researcher utilizes a standardized Checklist to ensure deliverable quality and consistency across both agents involved in the research process. This Checklist details specific criteria for completeness, encompassing data source verification, factual accuracy, and adherence to the defined research scope. Both agents independently review their outputs against this Checklist prior to submission, providing a dual verification process. This systematic approach minimizes errors, promotes reliability in the research findings, and facilitates a consistent standard of output regardless of which agent performs a given task. The Checklist is a core component of the quality control mechanism within FS-Researcher.
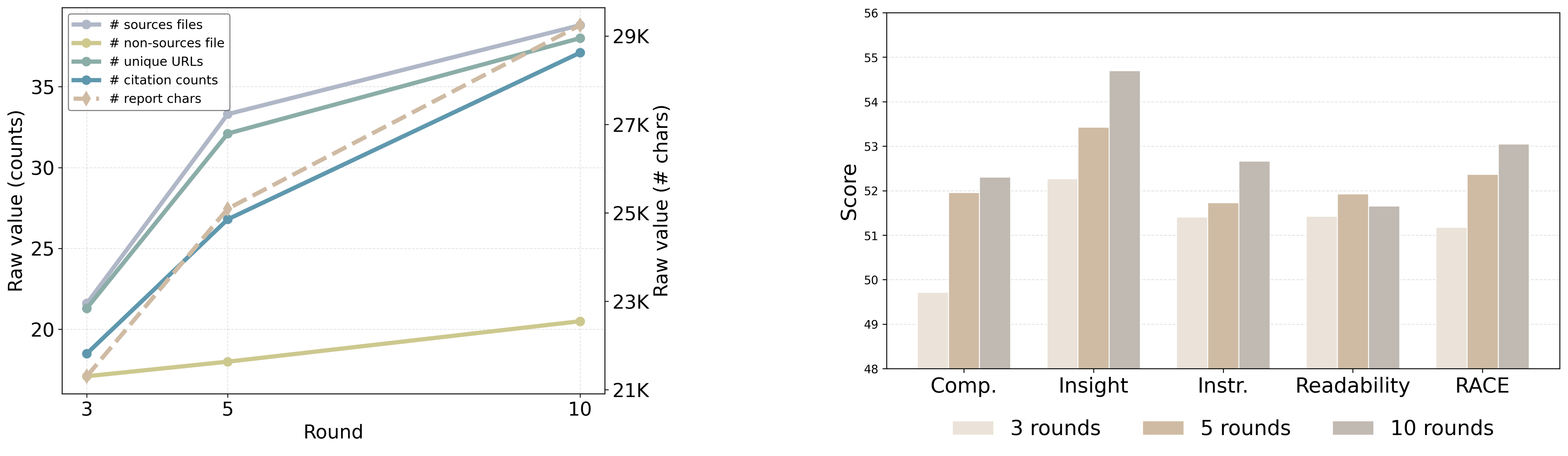
FS-Researcher incorporates iterative refinement as a core component of its workflow, enabling agents to continuously improve research outputs. This process involves repeated cycles of analysis, feedback incorporation, and revision; agents are not limited to a single pass of information processing. New data or feedback received at any stage triggers a revisit of previous work, allowing for adjustments and enhancements. This cyclical approach is designed to progressively increase the accuracy, completeness, and overall quality of the research deliverables, as agents build upon and refine their existing knowledge base throughout the task.
FS-Researcher utilizes an iterative processing model where information undergoes multiple refinement cycles rather than a single, linear assessment. This process involves agents revisiting data and deliverables to incorporate feedback, address inconsistencies, and integrate newly discovered information. Each iteration builds upon the previous one, progressively enhancing the completeness and accuracy of the research output. The system is designed to identify and correct errors or omissions that might be missed in a single-pass review, resulting in a higher quality and more reliable final product. This cyclical process is fundamental to the framework’s ability to deliver consistently improved results.
Benchmarking and Validation: Quantifying the Advancement
To objectively demonstrate its capabilities, FS-Researcher underwent a rigorous evaluation process utilizing DeepResearch Bench and DeepConsult, two widely recognized benchmarks within the field of deep research systems. These benchmarks provide standardized tests designed to assess a system’s ability to synthesize information, draw insightful conclusions, and maintain factual accuracy – crucial elements for any advanced research tool. DeepResearch Bench focuses on comprehensive report generation, while DeepConsult emphasizes the quality and persuasiveness of responses to complex queries. By subjecting FS-Researcher to these established protocols, researchers were able to quantify its performance against existing state-of-the-art systems, ensuring a fair and transparent comparison of capabilities and limitations.
Rigorous evaluation of FS-Researcher hinges on quantifiable metrics designed to dissect the quality and veracity of its generated reports. The system’s performance isn’t judged subjectively, but through scores like RACE and FACT, which provide a precise assessment of its capabilities. RACE Score specifically measures the ability to answer complex, multi-hop questions, demanding not just information retrieval, but also reasoning and synthesis. Simultaneously, FACT Score rigorously verifies the factual consistency of the generated content, minimizing the risk of hallucination or misinformation. These metrics, therefore, offer a dual guarantee: reports are not only comprehensive and insightful, but also demonstrably grounded in reliable information, establishing a new standard for deep research systems.
Rigorous evaluation confirms FS-Researcher’s capacity to generate reports distinguished by both quality and factual precision, exceeding the performance of conventional deep research systems. Utilizing the established RACE benchmark, FS-Researcher achieved a score of 53.94, demonstrably outperforming the strongest competitor, RhinoInsight, by a margin of +3.02. This improvement isn’t merely incremental; it signifies a substantial leap in automated research capabilities, suggesting FS-Researcher can synthesize information more effectively and deliver more robust, reliable conclusions than prior methods. The system’s capacity to surpass established baselines highlights its potential to reshape workflows requiring in-depth analysis and reporting.
Evaluations using the DeepConsult benchmark reveal FS-Researcher consistently outperforms competing systems, achieving an impressive 80.00% Win Rate and an Average Score of 8.33 – establishing a new high watermark for performance. This success isn’t simply about winning, but also about the quality of the research; FS-Researcher demonstrates substantial gains in key areas when compared to the previous leading system on DeepResearch Bench. Specifically, the system exhibits a noteworthy +3.74 improvement in Comprehensiveness, indicating a more thorough and complete exploration of the research landscape, coupled with a +4.4 increase in Insight, suggesting a superior ability to synthesize information and generate meaningful conclusions. These results collectively showcase FS-Researcher’s capacity to not only gather information, but to analyze and understand it at a significantly advanced level.
The presented framework, FS-Researcher, embodies a principle of structured exploration. It recognizes that complex research isn’t a singular leap, but a carefully constructed series of iterative refinements, mirroring how knowledge organically builds upon itself. This echoes G.H. Hardy’s sentiment: “Mathematics may be compared to a box of tools.” The system’s dual-agent approach, utilizing a file-system workspace as a persistent knowledge base, isn’t merely about scaling performance for long-horizon tasks; it’s about establishing a robust and adaptable scaffolding for intellectual endeavor. Each tool – each agent, each file – contributes to a greater understanding, much like a well-organized mathematician’s toolkit.
Looking Ahead
The introduction of FS-Researcher, with its insistence on a persistent, file-system based workspace, feels less like a solution and more like a necessary acknowledgement. One does not simply ‘solve’ long-horizon research; one creates a scaffolding upon which it might be addressed. The architecture itself reveals the limitations of attempting deep inquiry within purely parametric spaces. To treat context as an ephemeral buffer is akin to believing one can replace a failing kidney without considering the circulatory system. The framework’s success, therefore, isn’t about achieving a benchmark, but in highlighting the fundamental need for persistent memory and iterative refinement.
Future work, predictably, will focus on scaling. But the real challenge lies not in processing more data, but in improving the quality of the iterative loop. The agent’s ability to critically evaluate its own knowledge base – to identify biases, inconsistencies, and gaps – remains largely unexplored. It is not enough to build a larger library; one must cultivate a discerning librarian.
Ultimately, the question isn’t whether these agents can mimic research, but whether they can reveal something new about the process itself. The structure dictates behavior, and a system built on persistent memory and critical self-assessment may, just may, begin to approximate the messy, beautiful, and fundamentally iterative nature of genuine inquiry.
Original article: https://arxiv.org/pdf/2602.01566.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-03 07:50