Author: Denis Avetisyan
A new approach combines latent space modeling with real-time perception to enable robots to learn complex manipulation tasks with greater speed and stability.

This paper introduces LG-Flow Policy, a framework leveraging latent action flow matching and geometry-aware perception for robust robotic manipulation and trajectory generation from point clouds.
Achieving both real-time responsiveness and stable, long-horizon control remains a key challenge in robotic manipulation. This paper, ‘Temporally Coherent Imitation Learning via Latent Action Flow Matching for Robotic Manipulation’, introduces LG-Flow Policy, a novel framework that decouples global motion planning from low-level control by performing flow matching within a temporally regularized latent action space. This approach enables near single-step inference while substantially improving trajectory smoothness and task success compared to existing diffusion and flow-based methods. Could this decoupling of motion and control unlock more adaptable and robust robotic systems capable of complex, real-world tasks?
The Inevitable Fracture of Pre-Planned Motion
Historically, robotic control has depended on pre-programmed trajectories – meticulously planned sequences of movements dictating a robot’s actions. While offering precision in static settings, this approach proves brittle when confronted with the unpredictable nature of real-world environments. Any deviation from the expected scenario – an object slightly out of place, an unforeseen obstacle, or a change in surface texture – can disrupt the pre-defined path, leading to failure or requiring human intervention. This reliance on fixed plans severely restricts a robot’s ability to react and adapt, hindering its deployment in dynamic scenarios like warehouses, construction sites, or even domestic environments where spontaneity is the norm. The inherent inflexibility of trajectory-based control thus represents a significant bottleneck in the pursuit of truly autonomous and versatile robotic systems.
Training robots to directly interpret raw sensory data – such as camera images or tactile feedback – and translate it into fluid, coordinated movements presents a significant computational hurdle. This approach, while mirroring how humans learn, demands enormous processing power and vast datasets, often exceeding the capabilities of even high-performance computing systems. Consequently, policies learned in this manner frequently exhibit instability, manifesting as abrupt, jerky motions rather than the smooth, natural movements expected of skilled manipulation. The challenge lies in effectively mapping high-dimensional sensory input to low-dimensional motor commands while maintaining robustness and avoiding oscillations, a problem that necessitates innovative algorithms and substantial computational resources to overcome.
Conventional robotic action generation often prioritizes either the swiftness of movement or the precision with which tasks are executed, rarely achieving both simultaneously. Researchers are actively investigating novel techniques that move beyond pre-programmed trajectories and reactive control loops, seeking to create systems capable of dynamically adjusting to unforeseen circumstances without sacrificing smoothness or accuracy. This pursuit involves exploring architectures that blend the strengths of model-based and model-free reinforcement learning, alongside innovations in areas like differentiable planning and neural control. The goal is to develop robotic systems that can not only react to change, but also proactively anticipate and adapt, resulting in fluid, stable manipulation even in complex and unpredictable environments-a crucial step towards truly versatile robotic assistants.
Existing robotic control systems frequently encounter a critical bottleneck: the inverse relationship between computational speed and the refinement of generated movements. While some algorithms prioritize rapid decision-making to enable quick responses to changing conditions, they often sacrifice the smoothness and precision of the resulting actions. Conversely, methods aiming for highly accurate and fluid trajectories typically require substantial processing time, making them impractical for real-time applications where immediate reactions are crucial. This trade-off severely limits the deployment of advanced robotic systems in dynamic, unpredictable environments-such as warehouses, surgical settings, or disaster relief operations-where both swiftness and dexterity are paramount for successful task completion. Overcoming this limitation requires innovative approaches that can simultaneously deliver fast inference speeds and high-quality, stable movements, unlocking the full potential of robotic automation.
Compressing Action: The Illusion of Control
The proposed system employs a trajectory-level latent action representation to compress sequences of discrete robot actions into a lower-dimensional, continuous space. This is achieved by encoding short-horizon action segments – representing a limited duration of robot movement – into a latent vector. This vector serves as a condensed representation of the corresponding action trajectory, enabling efficient manipulation and generation of coherent movements. The compactness of this latent space is crucial for reducing computational demands during planning and control, while its continuity facilitates smooth transitions between different actions and prevents abrupt, unrealistic changes in robot behavior.
The system employs Gated Recurrent Units (GRUs), a type of Recurrent Neural Network (RNN), to model the temporal relationships inherent in sequential action data. GRUs process action segments by maintaining a hidden state that is updated at each time step, allowing the network to retain information about past actions and influence the generation of subsequent actions. This recurrent structure enables the capture of dependencies between actions within a sequence, promoting coherence and realistic motion. Specifically, GRUs utilize update and reset gates to control the flow of information, mitigating the vanishing gradient problem common in traditional RNNs and allowing for effective learning of long-term dependencies within action sequences.
The latent action space is regularized using a Variational Autoencoder (VAE) to ensure both compactness and continuity. The VAE achieves this by learning a probabilistic distribution over the latent variables, rather than simply encoding them into a fixed vector. This is accomplished through KL Divergence minimization, a loss function that penalizes deviations between the learned latent distribution and a prior distribution, typically a standard normal distribution [latex]N(0, I)[/latex]. Minimizing KL Divergence encourages the latent space to be compact – preventing the encoder from using unnecessarily large values – and continuous, enabling smooth transitions between different actions during decoding and improving generalization performance.
Operating within the learned latent action space offers substantial computational benefits during action generation. Direct control signal prediction, particularly for high-dimensional action spaces, requires significant processing resources. By contrast, generating actions through decoding from the lower-dimensional latent space drastically reduces the computational demands of both forward passes and gradient calculations. Furthermore, the VAE regularization, which enforces continuity and compactness in the latent space, mitigates instability during action generation by discouraging abrupt changes in the decoded action sequences, leading to smoother and more coherent behaviors. This is particularly important in complex control tasks where small perturbations can lead to cascading errors.
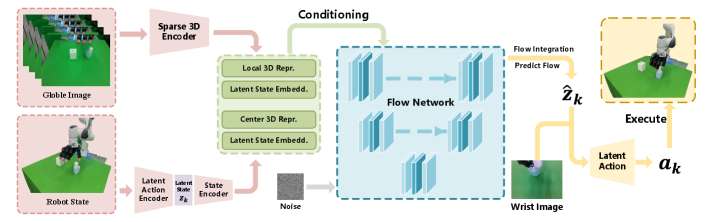
Flow Matching: Sculpting Action in Continuous Time
Flow Matching is a generative modeling technique that defines a continuous transformation between data distributions using Ordinary Differential Equations (ODE). This work extends Flow Matching to operate directly within the continuous latent action space, rather than a discrete action space. This allows for the generation of smooth, nuanced trajectories by learning a time-dependent vector field that maps a simple distribution (typically Gaussian) to the desired action distribution. The continuous representation avoids the limitations of discretization, which can introduce artifacts and reduce the fidelity of generated actions, and enables more efficient sampling and optimization during policy learning. The resulting policy directly outputs continuous action values, eliminating the need for action discretization or post-processing.
The LG-Flow policy utilizes a learned vector field to directly map states to actions, enabling rapid trajectory generation. This approach bypasses iterative optimization methods common in motion planning, resulting in inference speeds significantly faster than those achieved by techniques such as Model Predictive Control (MPC). The vector field is trained to represent the desired action distribution for a given state, allowing the policy to output actions in a single forward pass. Crucially, this direct mapping is achieved without compromising trajectory quality, as the learned field is optimized to produce smooth, feasible, and goal-directed motions through the training process. This enables real-time control in dynamic environments where computational efficiency is paramount.
The LG-Flow policy utilizes Feature-wise Linear Modulation (FiLM) to incorporate visual and geometric conditioning, enabling adaptation to dynamic environments. FiLM layers modulate the activations of the network based on the features extracted from sensory inputs – specifically, visual observations and geometric maps. This is achieved by learning scale and bias parameters that are functions of the conditioning features. These parameters are then applied to the intermediate feature representations within the policy network, effectively altering the network’s behavior based on the perceived environment. The result is a policy that can dynamically adjust its trajectory generation process in response to changes in the scene, such as the movement of obstacles or the rearrangement of objects, without requiring retraining of the core trajectory generation model.
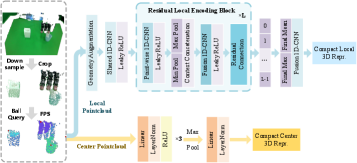
Geometry-aware point cloud conditioning enhances robotic manipulation by providing the policy with detailed environmental awareness. This is achieved through the integration of PointNet, a deep learning architecture designed to process point cloud data, and Farthest Point Sampling (FPS). FPS efficiently selects a representative subset of points from the input point cloud, reducing computational load while preserving crucial geometric information. PointNet then processes this sampled point cloud to extract relevant features, enabling the policy to understand the surrounding environment and adapt its manipulation strategy accordingly. This method allows for robust performance even with noisy or incomplete sensor data, as the policy can infer the presence and location of obstacles and target objects based on the available point cloud information.
The Inevitable Outcome: Reliable Dexterity in a Chaotic World
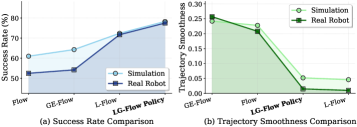
Rigorous testing across established robotic manipulation benchmarks – specifically the Meta-World and Adroit environments – reveals a substantial leap in performance. The framework consistently achieves a 77.5% success rate in real-world robotic manipulation tasks, demonstrating a marked improvement over existing methodologies. This heightened success isn’t simply about completing tasks, but doing so with increased reliability and consistency, paving the way for robots to operate more effectively in unstructured and dynamic settings. The results underscore the potential for wider adoption of advanced robotic systems in areas requiring precise and dependable manipulation capabilities, from manufacturing and logistics to healthcare and assistive technologies.
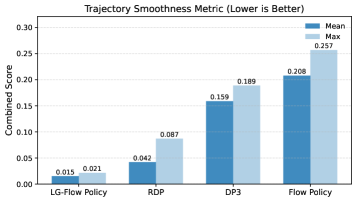
Robotic movements generated by this framework demonstrate a marked improvement in smoothness and stability. Analysis of generated trajectories reveals a significant reduction in jerk – the rate of change of acceleration – and a corresponding decrease in high-frequency spectral energy, indicating more fluid and controlled motions. Critically, real-world implementation showcased a dramatic reduction in unwanted oscillations, exceeding 95% compared to current state-of-the-art methods. This enhanced smoothness not only improves the efficiency of manipulation but also minimizes wear and tear on robotic systems, paving the way for more reliable and precise performance in delicate or repetitive tasks.
A core strength of this new framework lies in its capacity for real-time adaptation during robotic control, particularly within dynamic and unpredictable environments. Achieving an impressively low inference latency of 8.59 milliseconds allows the system to react swiftly to changing conditions, a critical feature for tasks demanding precision and responsiveness. This speed is not simply about faster computation; it enables the robot to continuously refine its movements based on real-time sensory input, mitigating the impact of external disturbances or unexpected obstacles. The result is a more robust and reliable performance, moving beyond pre-programmed sequences to achieve truly adaptive manipulation – a significant step toward robots operating effectively in complex, real-world scenarios.
The generation of stable and efficient robotic movements represents a significant step towards enabling complex manipulation tasks previously beyond the reach of automated systems. Recent simulations reveal a marked improvement in performance, with the framework achieving a 78.3% task success rate – exceeding the capabilities of current leading approaches. Crucially, this success isn’t simply about completion; the system also demonstrates a substantial 51.4% reduction in trajectory smoothness metrics. This translates to more fluid, natural movements, minimizing jerky motions and optimizing energy expenditure during operation. The combined effect of increased reliability and refined motion quality unlocks potential applications in fields requiring delicate and precise handling, such as assembly, surgery, and in-home assistance.
The pursuit of robotic manipulation, as demonstrated by LG-Flow Policy, echoes a timeless truth about complex systems. Each innovation, each promise of seamless control, inevitably introduces new vectors for failure. The framework’s reliance on latent space flow matching and geometry-aware perception, while achieving impressive results, merely refines the boundaries of that inevitable chaos. As Donald Knuth observed, “Premature optimization is the root of all evil.” The drive for speed and stability in trajectory generation – a core tenet of this work – is not about eliminating failure, but about momentarily delaying it, creating a temporary illusion of order within the inherent unpredictability of physical systems. The system isn’t ‘built’ so much as it’s coaxed into a transient state of coherence.
The Long Trajectory
This work, like all attempts at robotic dexterity, arrives at a local maximum. LG-Flow Policy manages to coax a system toward coherence, to generate plausible motions from noisy observations. But stability is merely a temporary reprieve; a fleeting alignment before the inevitable drift toward unforeseen circumstances. The true challenge isn’t generating a trajectory, but accepting the impossibility of predicting all future states. Scalability is, after all, just the word used to justify complexity.
The latent space, so carefully constructed, will inevitably become a bottleneck. Geometry-aware perception, however insightful, remains tethered to the present. The next iteration won’t be about more data, or cleverer algorithms. It will be about embracing imperfection, about building systems that gracefully degrade rather than catastrophically fail. Everything optimized will someday lose flexibility.
The pursuit of a perfect architecture is a myth to keep everyone sane. Perhaps the future lies not in controlling robotic manipulation, but in cultivating it – designing systems that learn to adapt, to improvise, to find their own way through the chaos. The goal isn’t a flawless performance, but an enduring, evolving practice.
Original article: https://arxiv.org/pdf/2601.23087.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-03 04:34