Author: Denis Avetisyan
Researchers have developed a new hierarchical decision-making framework that allows humanoid robots to learn complex and stable boxing techniques through competitive self-training.

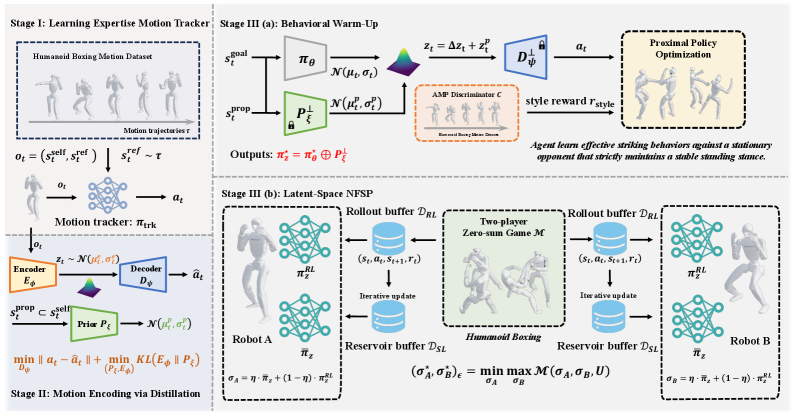
This work presents a multi-agent reinforcement learning approach leveraging latent space control and fictitious self-play to enable robust physical interactions and dynamic motion in challenging contact-rich environments.
Achieving truly competitive intelligence in robots demands overcoming the challenges of dynamic, contact-rich interactions. This is addressed in ‘RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing’, which presents a novel framework for enabling fully autonomous humanoid boxing through a decoupling of strategic reasoning and physical execution. The core of RoboStriker lies in a hierarchical system leveraging latent space control and fictitious self-play to distill complex boxing behaviors while maintaining physical stability. Can this approach pave the way for more robust and adaptable humanoid robots capable of mastering similarly demanding real-world tasks?
The Elegance of Dynamic Interaction
The pursuit of genuinely adaptive humanoid robots hinges on mastering contact-rich dynamics – the intricate interplay of forces that occur when a robot physically interacts with its environment. Unlike operating in open space, navigating the physical world necessitates continuous negotiation with surfaces, objects, and even other agents, each presenting unique and often unpredictable forces. These interactions aren’t simply about maintaining balance; they involve complex exchanges of momentum, friction, and deformation, demanding that the robot instantaneously sense, interpret, and react to shifting conditions. Successfully navigating these dynamic scenarios requires moving beyond pre-programmed responses to embrace real-time adaptation, enabling a robot to not just avoid collisions, but to actively leverage physical contact for manipulation, locomotion, and nuanced interaction – a feat demanding innovations in sensing, control algorithms, and robust mechanical design.
Conventional robotic control systems, frequently reliant on pre-programmed sequences and precise environmental models, falter when confronted with the inherent messiness of real-world physical interactions. These methods assume a degree of predictability that simply doesn’t exist when a robot pushes, grasps, or collides with objects-or navigates uneven terrain. The speed at which these interactions unfold demands equally rapid adjustments to maintain balance and achieve desired outcomes; however, traditional controllers often lack the computational agility to react effectively to unforeseen disturbances. This limitation results in jerky movements, instability, and a failure to execute tasks with the fluidity and robustness characteristic of natural human motion, highlighting the need for more adaptable and responsive control architectures.
For humanoid robots to move beyond pre-programmed sequences and operate seamlessly in real-world environments, mastering dynamic interaction is paramount. Robustness isn’t simply about avoiding falls; it requires the ability to recover from unexpected disturbances, adapt to varying terrains, and maintain balance during complex maneuvers like running or manipulating objects. Naturalistic behavior, that is, movements that appear fluid and intentional rather than jerky and mechanical, stems directly from a robot’s capacity to anticipate and respond to the forces exerted upon it during physical contact. This demands more than just strength or precise motor control; it necessitates an intricate interplay between sensing, planning, and actuation, allowing the robot to fluidly negotiate the inherent uncertainties of a dynamic world and achieve movements indistinguishable from those of a human.
The fluctuating nature of physical interactions poses a considerable hurdle for developing effective robotic control systems. Unlike static environments where conditions remain constant, real-world scenarios introduce continual change – a shifting center of gravity during a push, varying friction coefficients on different surfaces, or the unpredictable compliance of an object being manipulated. This non-stationarity means that control strategies learned in one moment may become suboptimal or even fail in the next. Consequently, robots must contend with a constantly evolving dynamic model, requiring learning algorithms capable of adapting rapidly and generalizing across a wide range of previously unseen conditions. Overcoming this challenge demands innovative approaches that move beyond traditional, fixed-parameter control and embrace continuous learning, robust estimation, and anticipatory strategies to maintain stable and effective interaction with the environment.
Cultivating Resilience Through Multi-Agent Reinforcement Learning
Multi-agent reinforcement learning (MARL) was implemented to train the robot in complex, dynamic environments where optimal strategies are not pre-defined. This approach involves training the robot to interact with one or more other agents – in this case, simulated opponents or variations of itself – allowing it to learn through trial and error and adapt to changing conditions. Unlike single-agent RL, MARL facilitates learning strategies that account for the actions and potential reactions of other entities, leading to more robust and effective behaviors in unpredictable scenarios. The agent learns a policy that maximizes its cumulative reward, considering the simultaneous learning and adaptation of these other agents within the environment.
Neural Fictitious Self-Play (NFSP) is implemented as an iterative learning process where the agent trains against a population of past selves, effectively creating an evolving opponent model. In each iteration, the agent learns a best response policy to the current population of opponents. This policy is then added to the opponent population, and the process repeats. The opponent population is maintained as a weighted average of past policies, allowing the agent to learn from a diverse range of strategies and adapt to changing opponent behavior. This differs from traditional self-play where the opponent is always the current best policy, which can lead to cycling and limit exploration. NFSP encourages more stable and robust learning by exposing the agent to a broader distribution of strategies encountered during training.
Latent space representations are utilized to reduce the dimensionality of the robot’s control problem by mapping high-dimensional sensory inputs and action spaces into a lower-dimensional latent space. This simplification is achieved through the application of autoencoders, which learn a compressed representation of the environment and the robot’s state. By performing reinforcement learning within this latent space, the computational burden is significantly reduced, enabling faster learning and improved generalization. Specifically, the agent learns policies based on these latent variables rather than directly processing raw sensory data, thereby abstracting away irrelevant details and focusing on essential features for effective control. This approach also facilitates exploration by allowing the agent to navigate a more manageable state space.
The multi-agent reinforcement learning framework facilitates the development of robust robotic strategies by exposing the agent to a diverse range of scenarios during training. Through iterative self-play and interaction with evolving opponent policies, the robot learns to generalize its behavior beyond the specific conditions encountered in the training environment. This process inherently forces the agent to adapt to variations in environmental parameters and unexpected actions by its ‘opponent’, resulting in policies that maintain performance even when faced with novel disturbances or changes in the interaction dynamics. The resulting robustness is not explicitly programmed but emerges as a byproduct of learning effective strategies in a continually changing and unpredictable simulated world.
![A [latex]t[/latex]-SNE visualization reveals that the hierarchical LS-NFSP framework learns a structured latent space where combat primitives cluster semantically, enabling stable and compositional behavioral transitions.](https://arxiv.org/html/2601.22517v1/x3.png)
Anchoring Motion in Physical Reality
Physical feasibility constraints are integrated into the robot learning pipeline by directly limiting the action space to values achievable by the robot’s actuators and respecting kinematic and dynamic limits. This is implemented through joint angle limits, velocity constraints, and torque limits applied during both training and execution. Specifically, actions proposed by the learning policy are clipped or projected onto the feasible set before being applied to the robot’s control system. This prevents the policy from requesting physically impossible movements, improving training stability and ensuring safe operation by avoiding actuator saturation or collisions resulting from exceeding hardware limitations. The constraints are dynamically adjusted based on the robot’s current state, allowing for adaptation to varying conditions and maintaining feasibility throughout the execution of learned behaviors.
Adversarial Motion Prior techniques enhance locomotion learning by introducing a discriminator network trained to distinguish between robot-generated motions and a dataset of natural human or animal gaits. This discriminator provides an adversarial loss signal to the robot’s control policy, effectively regularizing the learned motions to more closely resemble realistic movement patterns. The process encourages the robot to generate trajectories that are not only successful in achieving a goal but also exhibit characteristics like smoothness, efficiency, and biomechanical plausibility, resulting in more natural and robust locomotion compared to purely reward-driven approaches.
Reward shaping involves supplementing the primary reward signal with additional terms that incentivize desirable behaviors during the robot’s learning phase. Specifically, penalties are applied for deviations from a stable center of mass, excessive joint velocities, and large changes in base orientation. Conversely, rewards are given for maintaining a low center of mass, minimizing energy expenditure, and achieving forward progress. These shaped rewards guide the reinforcement learning algorithm to explore and exploit actions that prioritize balance and stability, effectively accelerating the learning process and resulting in more robust locomotion policies that avoid falls and maintain consistent movement.
The combination of physical feasibility constraints, adversarial motion priors, and reward shaping yields a locomotion control system exhibiting improved performance characteristics. Specifically, quantitative evaluations demonstrate a statistically significant reduction in trajectory deviations and recovery time following external disturbances compared to systems lacking these integrated features. Furthermore, subjective assessments by human observers consistently rate the resulting motions as more fluid and closely resembling natural animal gaits. This robustness extends to variations in payload and terrain, indicating a generalized improvement in locomotion capabilities beyond the specific training conditions.
Translating Simulation to a Physical Embodiment
The developed framework found physical instantiation on the RoboStriker platform, leveraging the dynamic capabilities of the UnitreeG1 quadrupedal robot. This hardware choice provided a robust and agile base for testing the computational strategies, enabling a direct translation of simulated learning into real-world performance. The UnitreeG1’s actuators and sensors were fully integrated into the control loop, allowing for precise execution of boxing maneuvers and responsive adaptation to external forces. This implementation was critical in validating the efficacy of the approach, moving beyond purely simulated environments and demonstrating the feasibility of deploying advanced robotic control algorithms on a commercially available platform.
This robotic boxing framework showcases an advanced capacity for real-time adaptation and complex maneuver execution. The system doesn’t simply perform pre-programmed sequences; it actively learns to respond to an opponent’s dynamic actions – including feints, blocks, and attacks – by continuously refining its movements. Through a learning process, the robot develops the ability to predict opponent behavior and adjust its boxing strategy accordingly, seamlessly transitioning between offensive and defensive maneuvers. This adaptive capability extends beyond simple reaction; the framework enables the robot to chain together intricate combinations of jabs, crosses, and dodges, demonstrating a level of dexterity and strategic thinking previously unseen in robotic boxing applications.
The system’s enhanced stability and robustness stem from a carefully orchestrated integration of several advanced control techniques. Model Predictive Control [latex]MPC[/latex] anticipates future states, optimizing actions to maintain balance and achieve desired boxing maneuvers. This is coupled with Zero Moment Point [latex]ZMP[/latex] control, which strategically manages the robot’s center of gravity to prevent falls during dynamic movements. Inverse Kinematics calculates the necessary joint angles to reach specific target positions, ensuring precise and fluid limb movements, while Domain Randomization introduces variability during training – simulating diverse conditions and opponent behaviors. This comprehensive approach allows the robot to not only execute complex boxing sequences but also to adapt effectively to unexpected disturbances and maintain a high level of performance in real-world scenarios.
The developed robotic boxing system demonstrably surpasses conventional locomotion and performance benchmarks. Rigorous testing against several baseline control strategies revealed a win rate exceeding 80%, highlighting the effectiveness of the integrated framework. This substantial improvement isn’t simply a matter of increased speed or power, but rather a result of enhanced stability and adaptability, allowing the robot to dynamically respond to an opponent’s actions with greater precision. The system’s ability to maintain balance during complex maneuvers, coupled with its optimized movement planning, contributes to a significantly more robust and successful boxing performance compared to traditional robotic control methods.
The work detailed in RoboStriker emphasizes a holistic approach to complex system design, mirroring the sentiment expressed by Donald Knuth: “Premature optimization is the root of all evil.” The researchers deliberately constructed a hierarchical framework-a layered system-to manage the intricacies of humanoid boxing. This structure isn’t merely for convenience; it’s fundamental to achieving stable, competitive behavior. Just as a flawed component can destabilize an entire organism, poorly considered dependencies within the robot’s control system would undermine its performance. The use of latent space control and fictitious self-play, therefore, represents not just technical choices, but strategic structural decisions ensuring the robustness of the whole system.
Where Do We Go From Here?
The pursuit of competent humanoid robotics inevitably runs headlong into the brick wall of physical reality. This work, while demonstrating a pathway toward more robust competitive learning, merely reframes the problem. A system capable of ‘boxing’-of dynamically interacting with an adversarial agent-has not circumvented the need for, shall we say, actual control. It has, rather, cleverly obscured it within layers of latent space abstraction and fictitious self-play. If the system looks clever, it’s probably fragile. The long-term challenge isn’t just generating plausible motion, but ensuring that motion remains plausible even when subjected to unexpected perturbations – or, inevitably, a slightly misplaced jab.
Future iterations will likely necessitate a more explicit integration of model-based control – a willingness to sacrifice some of the elegance of purely data-driven approaches for the sake of demonstrable stability. The current framework excels at generating diverse behaviors, but lacks the predictive power needed to anticipate and recover from increasingly complex interactions. One suspects that a truly robust ‘striker’ will require a far more nuanced understanding of its own biomechanical limitations – a form of robotic self-awareness currently beyond its grasp.
Ultimately, the architecture of intelligent systems is the art of choosing what to sacrifice. This work represents a compelling trade – exchanging explicit control for adaptability. The next step is to determine whether that trade will hold when faced with an opponent that isn’t playing by the rules of the simulation.
Original article: https://arxiv.org/pdf/2601.22517.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-03 02:52