Author: Denis Avetisyan
Researchers have developed a multi-agent simulation of a courtroom debate to improve the clarity and reliability of artificial intelligence systems when analyzing complex, tabular data.

AgenticSimLaw uses a structured debate between AI agents to enhance transparency and auditability in high-stakes tabular data reasoning, specifically for recidivism prediction.
Despite advances in large language models, ensuring transparent and controllable reasoning remains a challenge in high-stakes decision-making contexts. To address this, we introduce AgenticSimLaw: A Juvenile Courtroom Multi-Agent Debate Simulation for Explainable High-Stakes Tabular Decision Making, a novel framework employing structured multi-agent debate to enhance the auditability of tabular data analysis. Our approach, benchmarked on young adult recidivism prediction, demonstrates improved stability and generalization compared to single-agent prompting, offering fine-grained control and complete interaction transcripts. Can this courtroom-inspired methodology unlock more reliable and ethically sound AI systems for critical applications requiring human oversight?
Unveiling the Opaque Algorithm
Predictive algorithms, such as COMPAS and XGBoost, demonstrate considerable accuracy in forecasting outcomes, yet often operate as ‘black boxes’ – systems where the reasoning behind a prediction remains obscure. This lack of transparency isn’t merely a technical limitation, but a critical source of fairness concerns, particularly when applied to sensitive domains like criminal justice, loan applications, or hiring processes. While these algorithms may achieve high overall accuracy, the inability to understand why a specific prediction was made hinders the identification and mitigation of potential biases embedded within the model or training data. Consequently, individuals subject to these predictions may be unfairly categorized or denied opportunities without recourse, and broader societal inequities can be inadvertently reinforced – challenging the ethical deployment of these powerful tools.
The increasing reliance on ‘black box’ predictive models presents a significant challenge to accountability, particularly when applied to consequential decisions. These systems, while potentially accurate, often operate without revealing why a specific prediction was made, creating an evidentiary gap. This lack of transparency isn’t merely a technical limitation; it fundamentally undermines trust and the ability to challenge outcomes. When individuals are subjected to decisions – regarding loan applications, job opportunities, or even legal sentencing – without a clear rationale, it becomes difficult to ensure fairness and address potential errors or biases embedded within the algorithm. Consequently, the inability to scrutinize the reasoning behind a prediction erodes public confidence and hinders meaningful oversight of these increasingly prevalent technologies, raising critical ethical and legal concerns.
The inherent lack of transparency in many predictive systems poses a significant challenge to ensuring fairness and accountability. Without clear insight into how a prediction is reached, identifying the source of potential biases becomes exceptionally difficult. This opacity isn’t merely a matter of intellectual curiosity; it directly impedes effective oversight, as stakeholders are unable to scrutinize the underlying logic for discriminatory patterns or flawed assumptions. Consequently, biases embedded within training data or algorithmic design can persist undetected, leading to systematically unfair outcomes and eroding trust in the predictive process – particularly in critical applications like loan approvals, criminal justice, or healthcare where decisions profoundly impact lives. The inability to ‘open the box’ and examine the reasoning behind a prediction fundamentally limits the possibility of meaningful correction and responsible implementation.
Beyond the Single Oracle: Multi-Agent Systems Emerge
LLM-based Multi-Agent Systems (LaMAS) represent a departure from traditional approaches to complex task resolution by utilizing the inherent reasoning abilities of large language models (LLMs). These systems move beyond single-model solutions, distributing cognitive load across multiple LLM-powered agents. This architecture allows for the decomposition of intricate problems into smaller, more manageable sub-tasks, each addressed by a specialized agent. The agents can then collaborate, share information, and iteratively refine solutions through communication protocols. This distributed approach aims to overcome limitations in LLM reasoning, such as susceptibility to biases and errors, and improves performance on tasks requiring diverse knowledge or prolonged reasoning steps.
Chain of Thought (CoT) prompting enhances LLM reasoning by eliciting intermediate reasoning steps, improving performance on complex tasks. Tree of Thought (ToT) extends this by enabling agents to explore multiple reasoning paths, evaluating and pruning less promising options to enhance solution quality. Self-Consistency (SC) further improves reliability by sampling multiple reasoning paths with CoT and selecting the most consistent answer, mitigating the impact of stochasticity inherent in LLM outputs. These techniques, often used in combination, move beyond direct input-output mappings, enabling LLMs to perform more complex reasoning and reducing the occurrence of illogical or inaccurate responses.
Distributing reasoning across multiple agents in Large Language Model-based Multi-Agent Systems (LaMAS) enables parallel exploration of the solution space, mitigating the limitations of a single LLM’s perspective and reducing reliance on its inherent biases. This approach allows each agent to specialize in a specific aspect of the problem, formulate independent hypotheses, and contribute to a collective decision-making process. The aggregation of insights from diverse agents, often through mechanisms like voting or deliberation, results in more comprehensive analyses and more resilient outcomes compared to single-agent LLM solutions, particularly in complex or ambiguous scenarios where a singular line of reasoning may be insufficient.
AgenticSimLaw: A Framework for Scrutinizing the Logic
AgenticSimLaw utilizes a multi-agent system structured around a simulated courtroom debate to facilitate reasoning. This framework assigns distinct roles – specifically, prosecutor and defense – to individual agents, each tasked with analyzing a given scenario from their assigned perspective. The interaction is not simply a question-answering process; agents actively construct arguments and counterarguments, mirroring the adversarial nature of legal proceedings. This collaborative approach aims to leverage the strengths of multiple reasoning pathways, providing a more robust and nuanced evaluation of the scenario compared to single-agent methodologies. The defined roles and structured interaction are core components designed to encourage comprehensive exploration of relevant information and potential conclusions.
AgenticSimLaw employs a structured 7-turn interaction protocol to facilitate comprehensive debate. This protocol dictates a fixed sequence of turns: Turn 1 involves the prosecutor presenting their initial claim; Turn 2 allows the defense to respond and present a counter-claim; Turns 3 and 4 are dedicated to rebuttal and counter-rebuttal, respectively, where each side directly addresses the opponent’s prior arguments; Turn 5 is reserved for the prosecutor to present supporting evidence; Turn 6 allows the defense to present its evidence; and finally, Turn 7 consists of concluding statements from both sides summarizing their positions and the key points of contention. This rigid structure ensures systematic exploration of arguments and counterarguments, avoiding tangential discussions and promoting focused reasoning.
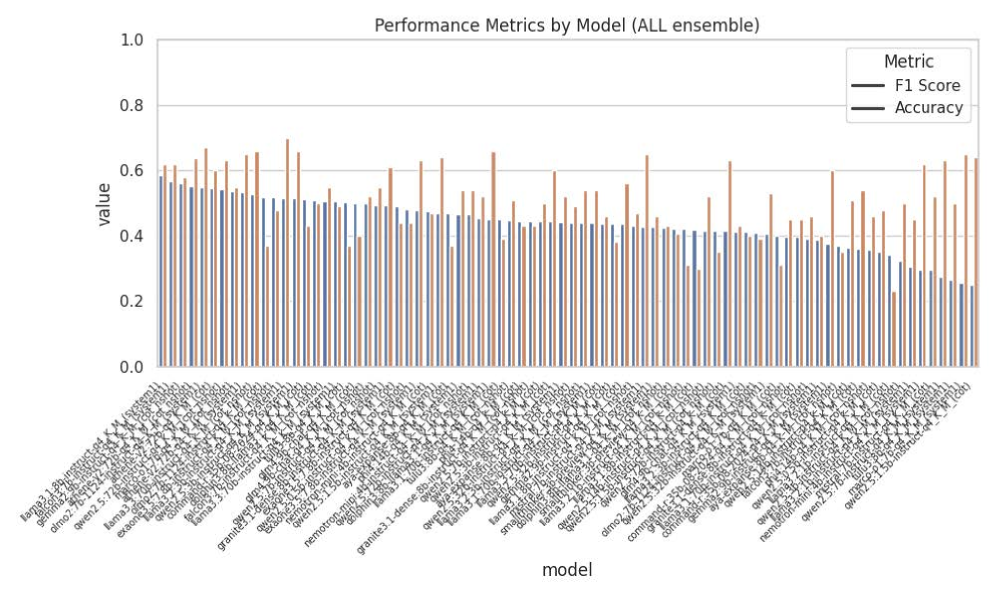
AgenticSimLaw prioritizes transparency through complete logging of all agent interactions and reasoning steps, alongside private strategy formulation where each agent develops its arguments independently before presentation. This design allows for full auditability of the decision-making process, enabling detailed examination of the evidence and logic used by each agent. Empirical results demonstrate a statistically significant improvement in performance, specifically a stronger correlation between accuracy and F1-score, when compared to single-agent prompting methods, indicating that the structured debate and detailed logging contribute to more reliable and justifiable outcomes.
Reclaiming Trust: The Power of Observable AI
AgenticSimLaw prioritizes transparency as a foundational element for building trustworthy artificial intelligence systems, directly aligning with the principles of Explainable AI (XAI). This focus moves beyond simply achieving accurate outputs to revealing how those conclusions are reached, a crucial step in fostering user acceptance and responsible deployment. By making the AI’s reasoning process accessible, AgenticSimLaw allows stakeholders to scrutinize its logic, understand its decision-making criteria, and ultimately, build confidence in its reliability. This enhanced clarity is not merely about satisfying intellectual curiosity; it’s about enabling effective oversight, identifying potential flaws, and ensuring that AI systems operate in a manner that is both predictable and aligned with human values, paving the way for broader adoption and integration into critical applications.
AgenticSimLaw incorporates robust auditability features designed to meticulously verify the reasoning processes of artificial intelligence systems. This capability moves beyond simply observing outcomes and allows for a deep dive into how an AI arrived at a particular conclusion. By enabling detailed examination of each step in the decision-making process, the system facilitates the identification of potential biases embedded within the AI’s logic. Such biases, often stemming from skewed training data or flawed algorithmic design, can lead to unfair or discriminatory outcomes. Rigorous audit trails empower developers and stakeholders to pinpoint these issues and implement targeted mitigation strategies, ensuring greater fairness, reliability, and accountability in AI-driven applications. This proactive approach to bias detection is crucial for building trust and fostering responsible AI development.
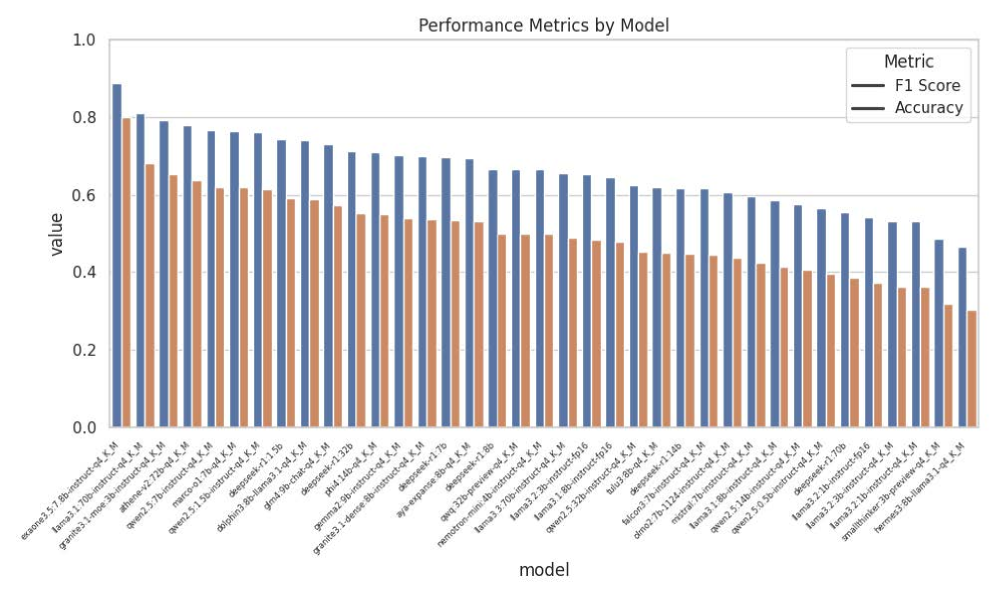
AgenticSimLaw significantly enhances the comprehension of complex AI systems by prioritizing observability, allowing stakeholders to trace the reasoning behind automated decisions. This transparency isn’t merely theoretical; the system demonstrably improves understanding of the ‘black box’ nature of AI, fostering more informed oversight and bolstering accountability. Rigorous testing indicates this approach achieves up to 0.87 accuracy and a corresponding F1 score when applied to larger, more sophisticated models, suggesting a quantifiable benefit in both performance and trustworthiness. The ability to dissect and analyze an AI’s internal logic empowers developers, regulators, and end-users alike, promoting confidence and responsible deployment of these increasingly powerful technologies.
Beyond the Horizon: Scaling and Generalizing Intelligent Systems
AgenticSimLaw’s future development hinges on its ability to process increasingly intricate scenarios and expansive datasets, necessitating innovative scaling strategies. Researchers are actively investigating techniques such as Mixture of Experts (MoE), which distributes computational load across specialized sub-models, and Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method. These approaches aim to overcome the computational bottlenecks inherent in training large language models while preserving performance. By strategically employing MoE and LoRA, the framework anticipates handling significantly more complex legal simulations and analyses, ultimately broadening its applicability and solidifying its potential as a powerful tool for legal reasoning and problem-solving.
The true power of AgenticSimLaw lies not just in its ability to navigate complex legal scenarios, but in its potential adaptability to other demanding fields requiring intricate reasoning. Researchers are actively investigating how the framework’s core principles-simulating multi-agent interactions and iteratively refining conclusions-can be successfully applied to areas like medical diagnosis, where nuanced judgment and consideration of multiple factors are paramount. This cross-domain exploration is essential, as demonstrating generalization beyond the legal realm will validate the underlying architecture and establish its utility as a broadly applicable AI reasoning engine. Success in these new domains will require careful adaptation of the simulation parameters and knowledge bases, but the anticipated rewards – a versatile AI capable of tackling diverse, complex problems – are substantial.
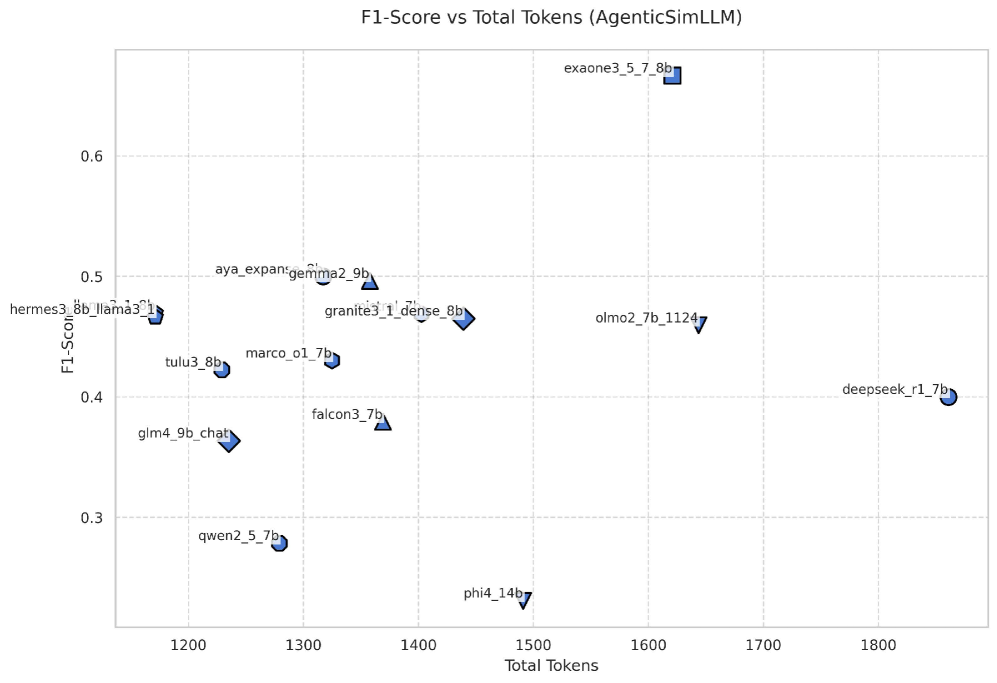
Advancing the field of AI reasoning hinges on the creation of evaluation metrics that move beyond simple accuracy scores to encompass the interpretability of an AI’s decision-making process. Current implementations of AgenticSimLaw, while demanding significantly more computational resources – approximately 9,100 tokens compared to the 600-800 tokens typical of single-turn Chain-of-Thought prompting – offer a marked improvement in the consistency of results. Specifically, these complex evaluations demonstrate lower variance in F1 scores, suggesting a more stable and reliable reasoning process. This trade-off between computational cost and increased stability highlights a crucial area for future research: developing more efficient metrics that can accurately assess not only what an AI concludes, but how it arrived at that conclusion, paving the way for more trustworthy and transparent artificial intelligence.
—
AgenticSimLaw, by structuring debate between simulated agents, embodies a fundamental principle: understanding emerges from rigorous testing. The system doesn’t simply predict recidivism; it actively demonstrates the reasoning behind its conclusions, exposing the assumptions inherent in tabular data interpretation. This echoes Tim Bern-Lee’s sentiment: “The Web is more a social creation than a technical one.” Just as the Web’s structure invites exploration and challenges established norms, AgenticSimLaw compels examination of the underlying logic driving high-stakes decisions. Every exploit starts with a question, not with intent, and this framework facilitates precisely that kind of inquisitive dismantling of complex predictive models, moving beyond opaque ‘black box’ outputs.
What’s Next?
The pursuit of explainability often feels like an exercise in post-hoc rationalization. AgenticSimLaw attempts to circumvent this by forcing articulation during decision-making, a debate framework where the model isn’t merely answering, but defending its answer. Yet, one wonders if the very structure of ‘debate’ introduces biases – are we truly uncovering the model’s reasoning, or simply fitting it into a recognizable argumentative form? The stability gains are promising, but stability isn’t truth. A perfectly consistent, yet fundamentally flawed, prediction engine remains a danger.
The focus on tabular data, while pragmatic for recidivism prediction, also begs the question of generalizability. Can this adversarial multi-agent approach scale to more complex data modalities – images, audio, unstructured text? Or is the core strength of this method intrinsically linked to the structured nature of tables, where contradictions are more readily exposed? Perhaps the real breakthrough won’t be in making models explain themselves, but in designing systems that are robust to unintelligible explanations.
Ultimately, this work hints at a broader principle: that intelligence isn’t solely about arriving at the correct answer, but about surviving the process of being questioned. If the ‘bug’ in current AI systems isn’t a flaw, but a signal – a lack of internal consistency detectable through rigorous interrogation – then the future of explainable AI may lie not in transparency, but in resilience to scrutiny.
Original article: https://arxiv.org/pdf/2601.21936.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-02 01:39