Author: Denis Avetisyan
A new benchmark probes the ability of large language models to effectively integrate retrieved knowledge into complex scientific problem-solving.
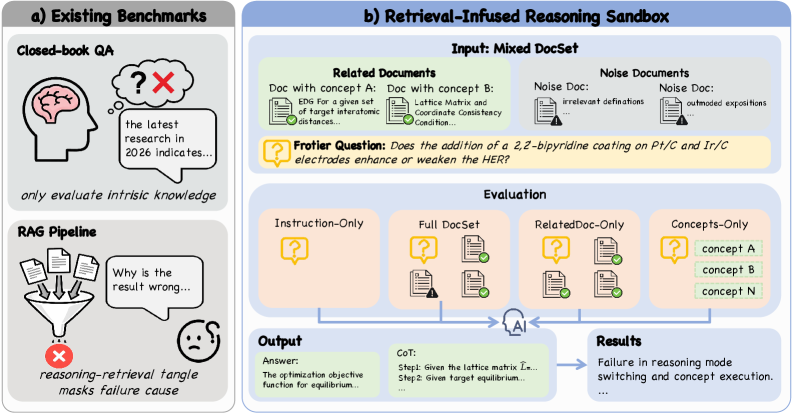
Researchers introduce DeR2, a benchmark for decoupling retrieval and reasoning, revealing limitations in current models’ capacity for procedural execution and knowledge coordination.
Despite strong performance on existing benchmarks, it remains unclear whether large language models truly reason over novel scientific information, often conflating reasoning with retrieval and memorization. To address this, we introduce DeR2, a controlled benchmark-Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities-designed to isolate document-grounded reasoning through four distinct regimes that operationalize retrieval loss versus reasoning loss. Our experiments reveal substantial variation in model capabilities, highlighting limitations in areas like mode switching and procedural execution, and demonstrating that simply naming concepts does not guarantee their correct application. Can we develop more robust and interpretable retrieval-infused reasoning systems that genuinely advance scientific problem solving?
The Limits of Recognition: Navigating Complexity in Scientific Inquiry
Scientific inquiry frequently presents challenges that surpass the capabilities of simple recall or the identification of familiar sequences. Truly complex problems necessitate a form of reasoning that synthesizes diverse information, extrapolates from established principles, and constructs novel solutions-a process far removed from merely recognizing pre-existing patterns. This demands an ability to navigate ambiguity, evaluate evidence critically, and formulate hypotheses that can be rigorously tested, often requiring the integration of knowledge from multiple disciplines and the consideration of unforeseen variables. The capacity to move beyond established protocols and embrace creative problem-solving is, therefore, a hallmark of genuine scientific advancement and a critical distinction between superficial understanding and deep insight.
Contemporary artificial intelligence frequently encounters limitations when tackling problems requiring information beyond its initial training data. While adept at identifying correlations within datasets, these systems often struggle to effectively incorporate external knowledge – facts, principles, or common sense not explicitly present in their training – into their reasoning processes. This inability to synthesize disparate information sources significantly hinders performance on novel tasks; an AI might recognize patterns in medical images, for instance, but fail to correctly diagnose a rare condition requiring understanding of obscure physiological mechanisms. The core challenge lies not merely in accessing external knowledge, but in intelligently determining its relevance, validating its accuracy, and seamlessly integrating it into the existing framework for problem-solving, a capacity that remains a significant hurdle in achieving truly adaptable and robust artificial intelligence.
The true hurdle in advancing artificial intelligence lies not in simply providing systems with vast datasets, but in equipping them with the capacity to leverage that information purposefully. Current AI often excels at identifying correlations within data, yet falters when confronted with problems requiring the application of external knowledge or nuanced understanding. A genuinely intelligent system must move beyond data retrieval and demonstrate the ability to synthesize information, draw inferences, and adapt previously learned principles to novel situations – essentially, it needs to apply knowledge, not just access it. This demands a shift towards AI architectures that prioritize reasoning, analogical thinking, and the construction of causal models, enabling a more flexible and robust approach to problem-solving that mirrors human cognitive abilities.

DeR2: A Controlled Environment for Isolating Reasoning Capabilities
The DeR2 benchmark is designed to isolate and assess the performance of retrieval-augmented reasoning systems by separating the retrieval and reasoning processes. Traditional evaluations often conflate these stages, making it difficult to determine whether performance gains are due to improved information retrieval or enhanced reasoning capabilities. DeR2 addresses this by providing a controlled environment where the retrieved documents are pre-defined and fixed, allowing researchers to systematically evaluate the reasoning component given a specific set of external knowledge. This decoupling facilitates precise analysis of how effectively a model utilizes retrieved information, independent of the retrieval mechanism itself, and enables targeted improvements to either component in isolation.
The DeR2 benchmark employs four distinct evaluation settings to isolate and measure the impact of different knowledge sources on retrieval-infused reasoning performance. The Instruction-Only setting assesses baseline reasoning ability without external knowledge. Concepts-Only provides models with relevant concepts, evaluating reasoning given pre-extracted knowledge. Related-Only offers full documents, testing the model’s ability to retrieve relevant concepts from unstructured text. Finally, the Full-Set setting combines instructions, concepts, and documents, representing a complete knowledge context. This tiered approach allows for granular analysis of model performance under varying knowledge conditions, specifically isolating the challenges associated with both knowledge retrieval and knowledge integration into the reasoning process.
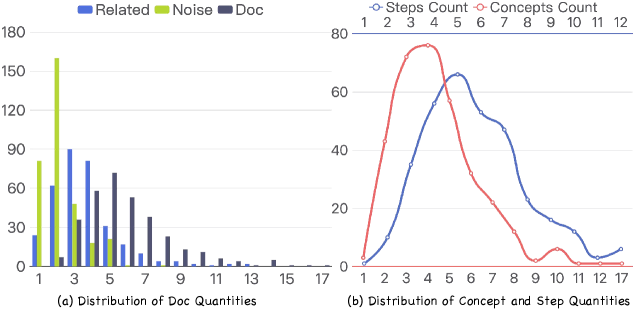
Evaluations conducted using the DeR2 benchmark demonstrate considerable performance variability across tested models, with overall accuracy ranging from approximately 49% to 75%. This 26-percentage-point spread indicates substantial differences in the ability of current systems to perform retrieval-infused reasoning tasks. The observed range suggests that while some models exhibit a moderate capacity for integrating retrieved knowledge into problem-solving, others struggle significantly, highlighting a need for improved techniques in areas such as information retrieval, knowledge extraction, and reasoning capabilities.
DeR2 utilizes Document Sets within its evaluation settings to quantify the integration of external knowledge into reasoning. Analysis of results reveals a measurable ‘Retrieval Loss’, defined as the performance difference between the Concepts-only setting – where models rely on pre-existing knowledge – and the Related-only setting, which introduces relevant documents. This gap indicates that current models struggle to accurately extract and utilize key concepts presented within the provided documents, despite their relevance to the problem. The magnitude of this Retrieval Loss serves as a direct metric of a model’s ability to effectively bridge the gap between information retrieval and subsequent reasoning processes.
The DeR2 benchmark facilitates a detailed analysis of model performance in scientific reasoning by isolating specific knowledge sources and reasoning demands. Through its four evaluation settings – Instruction-Only, Concepts-Only, Related-Only, and Full-Set – DeR2 quantifies the impact of different types of external knowledge on problem-solving accuracy. The observed ‘Retrieval Loss’ – the performance gap between accessing raw documents (Related-Only) and pre-extracted concepts (Concepts-Only) – pinpoints challenges in effectively interpreting and applying retrieved information. This granular approach allows researchers to identify specific weaknesses in current systems, such as difficulties in concept extraction or knowledge integration, and to target improvements in these areas for enhanced scientific reasoning capabilities.
Bumblebee Gravity: A Framework Introducing Anisotropic Effects
Bumblebee gravity departs from standard General Relativity by positing the existence of a dynamical vector field, denoted as [latex] \phi^\mu [/latex], which directly couples to the spacetime metric. This coupling modifies the gravitational interaction, introducing a tensor field [latex] \Phi_{\mu\nu} [/latex] derived from [latex] \phi^\mu [/latex] that contributes to the effective stress-energy tensor. Unlike traditional modifications involving scalar fields, the vector nature of [latex] \phi^\mu [/latex] introduces polarization modes not present in standard gravity and allows for anisotropic gravitational effects. The theory predicts deviations from the inverse-square law of gravity at short distances and provides a framework for exploring potential violations of the Weak Equivalence Principle dependent on the direction of the vector field.
Bumblebee gravity deviates from general relativity by including non-minimal coupling terms in the gravitational action, effectively modifying the relationship between gravity and matter fields. This modification is parameterized by a Lorentz-violating parameter, denoted as ε, which introduces a preferred direction in spacetime. The presence of this parameter allows for anisotropic gravitational effects and alters predictions regarding gravitational wave propagation and cosmological expansion rates. Specifically, certain configurations of ε can potentially account for observed discrepancies between the standard ΛCDM model and cosmological data, such as the Hubble tension and anomalies in the cosmic microwave background, by providing an alternative explanation for dark energy or modified gravity effects at cosmological scales.
Bumblebee gravity incorporates an external matter field that directly interacts with the modified gravitational field. This interaction is specifically described by the Maxwell Equations, meaning the field behaves as an electromagnetic field with associated potentials and field strengths. Consequently, the energy-momentum tensor of this external field contributes to the overall gravitational dynamics, potentially influencing cosmological parameters and offering a mechanism for observed discrepancies with standard ΛCDM models. The coupling between this field and spacetime is fundamental to the theory’s predictions regarding gravitational wave propagation and the potential for Lorentz violation.
Schubert Calculus and Descent Sets offer a robust mathematical framework for investigating the interactions inherent in Bumblebee Gravity. Specifically, Schubert Calculus, traditionally used in algebraic geometry and topology, provides tools to analyze the geometry of flag manifolds which arise when examining the vector field configurations within the theory. Descent Sets, a combinatorial construct, enable the systematic enumeration and characterization of these configurations, particularly concerning the symmetries and constraints imposed by the Lorentz-violating parameters. This allows researchers to move beyond perturbative calculations and analyze the full complexity of the coupled matter field interactions, described by the Maxwell Equations, within the modified gravitational framework, ultimately facilitating the derivation of testable predictions and comparisons with cosmological observations. The application of these tools aids in understanding the non-linearities and potential instabilities arising from the vector field coupling to spacetime, providing a means to classify solutions and assess their physical relevance.
The Future of Scientific Discovery: AI, Reasoning, and Beyond
The development of AI capable of genuine scientific discovery hinges on its ability to move beyond pattern recognition and embrace external knowledge integration, a challenge powerfully illustrated by benchmarks like DeR2 and the complexities of theoretical frameworks such as Bumblebee Gravity. These arenas demand more than simply processing information; they require systems to synthesize disparate data, evaluate relevance, and apply knowledge from outside the immediate problem space to arrive at reasoned conclusions. DeR2, specifically, tests this capacity by presenting problems demanding the retrieval and application of supporting evidence, while theories like Bumblebee Gravity-which proposes modified Newtonian dynamics-necessitate understanding and manipulating complex physical principles. Successfully navigating these challenges necessitates AI that can not only access information but also critically assess its validity and seamlessly incorporate it into complex reasoning processes, ultimately unlocking the potential for automated hypothesis generation and scientific advancement.
Recent evaluations utilizing the DeR2 benchmark have uncovered a surprising trend in advanced AI models; specifically, certain models, including Gemini-3-Pro, exhibit diminished performance when provided with a more comprehensive dataset. While achieving 64.2% accuracy when operating under instruction-only conditions, the same model’s performance dropped to 53.7% when exposed to the full dataset-a phenomenon termed ‘mode switching’ difficulty. This suggests that, contrary to expectations, simply increasing the amount of available information does not automatically enhance reasoning capabilities; instead, these models struggle to effectively integrate relevant data while filtering out extraneous details. The observed decrease indicates a critical limitation in current AI architectures – an inability to seamlessly transition between focused instruction-following and broad knowledge integration – highlighting a need for improved mechanisms that prioritize pertinent information and manage the complexities of real-world data.
The introduction of seemingly relevant, yet ultimately extraneous, documents significantly hinders the reasoning capabilities of advanced AI models, a phenomenon quantified as ‘Noise-Induced Loss’. Analysis reveals that while models perform adequately when presented with only related information, their accuracy declines when exposed to a full dataset including irrelevant materials – the difference between these two performance levels constitutes the loss. This suggests that current AI systems struggle to effectively discern crucial data from distracting noise, underscoring a critical need for sophisticated filtering mechanisms. Developing robust techniques to identify and exclude irrelevant documents isn’t merely about improving existing performance metrics; it’s fundamental to building AI capable of reliable and accurate reasoning in complex, real-world scenarios, where information overload is commonplace.
Advancements in artificial intelligence reasoning, particularly in effectively integrating external knowledge, promise a significant acceleration of scientific discovery, notably within cosmology and fundamental physics. The capacity of AI to sift through vast datasets, identify subtle patterns, and formulate novel hypotheses holds the potential to overcome limitations inherent in traditional research methods. This extends beyond simply automating existing processes; improved AI reasoning could enable the exploration of previously inaccessible theoretical landscapes, potentially resolving long-standing paradoxes or revealing entirely new physical principles. Fields grappling with complex, multi-dimensional data – such as mapping the distribution of dark matter, modeling the evolution of the early universe, or testing the limits of general relativity – stand to benefit most from these breakthroughs, ushering in an era of data-driven insight and accelerated scientific progress.
The advancement of artificial intelligence reasoning extends beyond simply automating existing scientific processes; it promises to fundamentally reshape the landscape of discovery itself. Current AI systems excel at analyzing data and identifying patterns, but future iterations, capable of sophisticated reasoning, will move past this descriptive role to become generative engines of inquiry. These tools will not only answer known questions but, critically, will formulate novel hypotheses, identify gaps in current understanding, and propose experiments to test those hypotheses – effectively acting as collaborators in the scientific process. This ability to explore uncharted territory, guided by data but not limited by pre-defined parameters, has the potential to accelerate breakthroughs in fields ranging from cosmology to fundamental physics, opening avenues of investigation previously inaccessible to human researchers and fostering a new era of data-driven, AI-assisted scientific exploration.
The introduction of DeR2 as a benchmark offers a crucial dissection of retrieval-augmented generation (RAG) systems. This controlled environment allows for pinpointing deficiencies in large language models’ ability to seamlessly transition between retrieval and reasoning-a challenge highlighted by the study’s findings regarding mode switching and procedural execution. As Tim Bern-Lee observed, “The web is more a social creation than a technical one,” and this benchmark exemplifies that principle by creating a focused ‘social’ space for evaluating these critical AI capabilities. The benchmark’s emphasis on decomposing complex scientific problems into manageable steps demonstrates a similar architectural philosophy-good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
The Road Ahead
The DeR2 benchmark, in its deliberate fracturing of retrieval and reasoning, exposes a fundamental truth: current large language models excel at appearing to reason, but struggle with the procedural demands of actual scientific problem solving. The observed deficiencies – brittle mode switching, inconsistent execution of defined procedures, and a startling lack of conceptual coordination – are not bugs to be patched, but symptoms of a deeper architectural limitation. Optimizing for superficial coherence will yield diminishing returns; the models treat knowledge as static texture rather than dynamic process.
Future work must move beyond simply scaling parameters and datasets. A fruitful path lies in explicitly modeling the cognitive scaffolding inherent in scientific inquiry – the iterative refinement of hypotheses, the careful tracking of dependencies, and the recognition of when retrieval itself is the limiting factor. The pursuit of ‘long context’ is, in a sense, misdirected. It’s not about how much information a model can ingest, but how it structures and utilizes that information. Dependencies, after all, are the true cost of freedom; a model that retrieves everything understands nothing.
Ultimately, the goal should not be to build a general-purpose reasoning engine, but a system that knows when to ask for help – and, crucially, can accurately interpret the answer. Good architecture is invisible until it breaks; DeR2 offers a controlled demolition, revealing the fault lines in the current edifice and charting a course towards more robust and reliable scientific reasoning.
Original article: https://arxiv.org/pdf/2601.21937.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-01 05:31