Author: Denis Avetisyan
Researchers are exploring methods to guide diffusion models towards generating truly original images, moving beyond predictable outputs.

This review details a technique for stimulating creative image generation by targeting low-probability regions within the latent space of diffusion models.
While generative models excel at producing realistic images, fostering genuine creative novelty remains a significant challenge. This is addressed in ‘Creative Image Generation with Diffusion Model’, which introduces a framework that explicitly steers diffusion models towards generating low-probability images within the CLIP embedding space. By quantifying and maximizing image rarity, the approach cultivates outputs demonstrably more imaginative and visually compelling than those produced by conventional methods. Could this principled approach to latent space exploration unlock a new era of innovation in visual content synthesis and redefine our understanding of creativity in AI?
Beyond Replication: The Pursuit of Genuine Creativity in Image Generation
Contemporary image generation models, while achieving remarkable feats of photorealism, frequently fall short in producing genuinely creative outputs. These systems are optimized to replicate the statistical patterns present in their training data, leading to images that, while technically proficient, often lack novelty or surprising elements. The emphasis on minimizing reconstruction error – essentially, creating images that closely resemble those seen during training – inadvertently discourages exploration beyond established visual tropes. Consequently, generated images can feel derivative, predictable, and ultimately, lacking in the imaginative spark that defines true creativity; the systems excel at imitation, but struggle with genuine innovation, highlighting a critical gap between technical achievement and artistic expression.
Current automated assessments of image generation, such as the widely used Inception Score (IS) and Fréchet Inception Distance (FID), primarily focus on statistical measures of image quality and the diversity of generated samples. While these metrics effectively gauge how closely generated images resemble real images and how varied the outputs are, they fall short of capturing the nuanced qualities of true creative exploration. A high score on IS or FID doesn’t necessarily indicate originality or surprisingness; an algorithm can produce statistically diverse images that are still derivative or predictable within the bounds of its training data. Essentially, these metrics evaluate how well something is generated, not how novel it is, leaving a critical gap in assessing genuine creativity and the capacity for generating truly unexpected content.
Current image generation models, despite their impressive capabilities, frequently exhibit a fundamental constraint: a strong adherence to the patterns and characteristics present within their training datasets. This reliance limits their capacity for true originality, often resulting in outputs that are plausible variations of existing imagery rather than genuinely novel creations. The models essentially operate by interpolating and recombining learned features, making it difficult to venture beyond the established boundaries of the training distribution. Consequently, while generated images may be visually appealing and technically proficient, they often lack the unexpectedness or conceptual leap associated with human creativity, hindering the production of truly groundbreaking or imaginative content.
Navigating the Latent Space: A Pathway to Creative Exploration
Latent Diffusion Models (LDMs) operate by transforming image data into a lower-dimensional, compressed representation known as a latent space. This compression is achieved through the use of a variational autoencoder (VAE), which encodes high-dimensional pixel data into a probabilistic distribution within the latent space and subsequently decodes it back into image form. By performing the diffusion process – iteratively adding noise and then learning to reverse it – within this compressed latent space, LDMs significantly reduce computational requirements compared to pixel-space diffusion models. This enables efficient training and generation of high-resolution images while preserving critical image details, as the latent space captures the essential features necessary for reconstruction. The use of a latent space also facilitates manipulation and exploration of image characteristics through vector arithmetic and interpolation.
The ‘Creative Loss’ function operates by calculating the negative log-likelihood of generated latent vectors under a learned probability distribution. This distribution is initially informed by the training data’s latent space occupancy, effectively mapping regions of high and low density. During image generation, the Creative Loss penalizes the model for producing latent vectors that reside in high-probability, frequently-visited areas. The magnitude of this penalty is directly proportional to the estimated probability of the latent vector, thereby incentivizing the diffusion process to sample from regions of lower probability and explore less common features in the embedding space. This approach allows for directed exploration of the latent space, pushing the generative model beyond typical outputs and towards potentially novel image compositions.
The theoretical basis for incentivizing exploration of low-probability latent space regions rests on the Wundt Curve, a psychological principle positing a non-monotonic relationship between arousal potential, creativity, and stimulus probability. This curve suggests that both extremely predictable and extremely unpredictable stimuli result in low arousal and, consequently, reduced creative output. Optimal creativity occurs at an intermediate level of surprise or novelty. Therefore, by deliberately prompting the model to generate samples from areas of the latent space associated with lower probabilities – representing deviations from typical image features – we aim to maximize arousal potential and, according to the Wundt Curve, increase the likelihood of generating genuinely creative and novel imagery. This approach functionally seeks to position generated outputs within the peak of the Wundt Curve, balancing predictability and surprise.
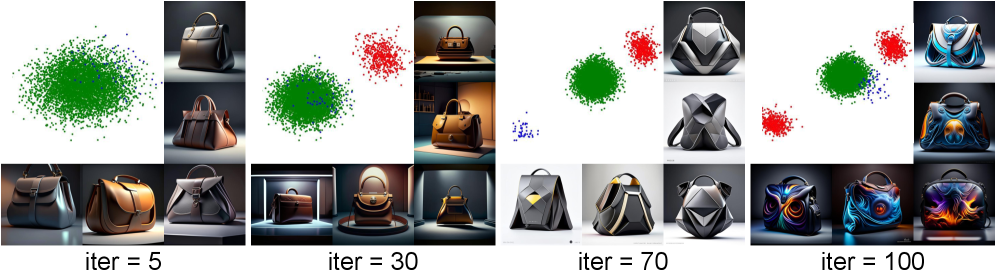
The generation of novel imagery relies on actively sampling from low-probability regions within the latent space of a diffusion model. This is achieved by biasing the generative process towards areas of the embedding space that are infrequently visited during standard operation. The rationale is that high-probability regions, representing common image features and compositions, yield predictable outputs, while less-explored areas contain configurations potentially representing unique and aesthetically interesting visual elements. By prioritizing these atypical configurations, the system aims to produce images that deviate from established norms and offer a higher degree of originality, ultimately contributing to both novelty and aesthetic appeal.
![The model generates images by sampling from a diffusion prior [latex]\epsilon_{\theta}[/latex], then creatively optimizes learned layers to shift generated embeddings (red dot) toward low-probability regions (orange arrow) guided by anchor and multimodal LLM validation, before rendering the final image.](https://arxiv.org/html/2601.22125v1/x2.png)
Sculpting the Output: Directional Control and Semantic Alignment
Directional Control operates by actively guiding the image generation process away from identified ‘Negative Clusters’ within the latent embedding space. These clusters represent regions associated with undesirable visual characteristics, such as artifacts, distortions, or generally low aesthetic quality. The mechanism achieves this steering by applying a corrective force during the diffusion process, effectively biasing the generation towards areas of the embedding space that are distant from these negatively defined regions. This results in a reduction of undesirable outputs and an improvement in the overall quality and visual appeal of the generated images.
Directional control is implemented by modifying the Latent Diffusion Model (LDM) to actively avoid the identified negative clusters during image generation. This is achieved by calculating gradients with respect to the latent variables, and then applying a steering vector that pushes the generation process away from these undesirable regions of the embedding space. Specifically, the LDM’s denoising process is altered to incorporate a penalty term proportional to the proximity of the latent representation to the negative clusters. This effectively biases the diffusion process, encouraging the model to sample from areas associated with visually appealing and desirable image characteristics, while simultaneously suppressing the generation of images residing within the negative clusters.
The Anchor Loss function facilitates semantic alignment by minimizing the distance between the generated image’s embedding and the embedding of the input text prompt within a shared latent space. This is achieved by treating the text embedding as an “anchor” and optimizing the image generation process to bring the generated image’s embedding closer to this anchor point. Specifically, the loss is calculated as the squared Euclidean distance between these two embeddings, encouraging the model to prioritize features described in the text prompt during image creation and ensuring a stronger correspondence between textual description and visual output. This direct optimization of latent space alignment improves the relevance and accuracy of generated images with respect to the provided textual input.
Dimensionality reduction is achieved through Principal Component Analysis (PCA) applied to image embeddings. This process reduces the embedding space from its original dimensionality to 50 dimensions while preserving over 95% of the original variance. The reduction in dimensionality significantly improves computational efficiency during the identification of ‘Negative Clusters’ – regions containing undesirable image characteristics. By focusing analysis on these fewer dimensions, the system can more effectively pinpoint and avoid generating images associated with these clusters, streamlining the exploration process and reducing processing time.
Refining the Vision: Diffusion Priors and Validation for Enhanced Generation
The system leverages a ‘Diffusion Prior’ as a crucial first step in image creation, effectively translating textual descriptions into a rich, meaningful representation known as a CLIP image embedding. This prior, trained to understand the relationship between text and visual concepts, doesn’t directly generate pixels but instead predicts the underlying visual features described in the prompt. This prediction then feeds into a second stage – an image decoder – which transforms the embedding into a fully realized image. By decoupling the understanding of the prompt from the actual image synthesis, the two-stage process allows for greater control and flexibility, improving the semantic accuracy and overall quality of the generated visuals. This approach moves beyond simply mapping text to pixels, instead focusing on first understanding the desired image before bringing it into existence.
The system’s diffusion prior benefits from a strategic adaptation using Low-Rank Adaptation, or LoRA, a technique designed for parameter-efficient fine-tuning. Rather than retraining the entire model-a computationally expensive undertaking-LoRA introduces a smaller set of trainable parameters, allowing the prior to be specialized to the text-to-image generation task with significantly reduced resources. This approach preserves the pre-trained knowledge within the diffusion prior while enabling targeted adjustments, resulting in a model that quickly learns to predict CLIP image embeddings with improved accuracy and fidelity. Consequently, LoRA facilitates faster experimentation and deployment without sacrificing performance, making the system highly adaptable and scalable.
The generation of high-quality images from text requires not only visual fidelity but also semantic coherence – ensuring the image genuinely reflects the input prompt’s meaning. To address this, a Multimodal Large Language Model (MLLM) Semantic Validity Checker was integrated into the system. This checker functions as a dedicated evaluator, analyzing the generated image alongside the original text prompt to determine if they are semantically aligned. It assesses whether the visual elements within the image logically correspond to the concepts and relationships described in the text. By identifying and flagging inconsistencies – such as an image depicting a ‘red car’ when the prompt specified ‘blue’ – the checker helps refine the generation process, promoting outputs that are both visually appealing and factually consistent with the provided textual instructions. This focus on semantic validity is critical for building trust and usability in text-to-image applications.
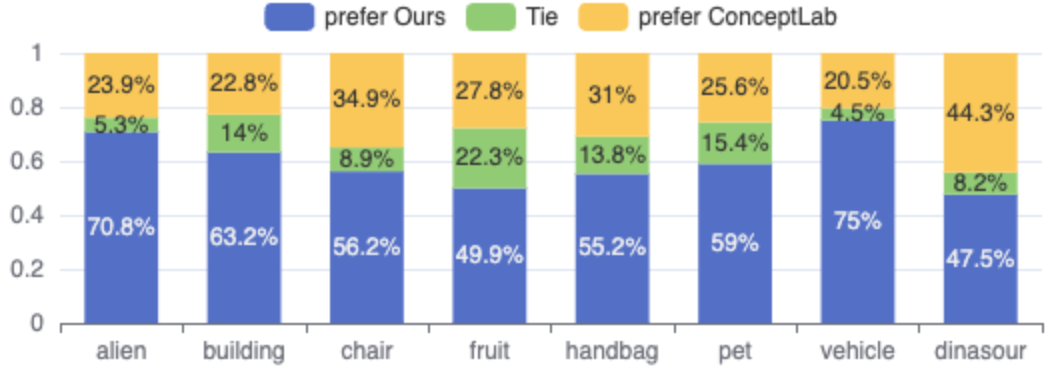
Rigorous human evaluation revealed a substantial preference for images generated using this new approach when contrasted with a baseline model. Specifically, evaluators favored the generated ‘alien’ imagery in 70.8% of comparisons, indicating a marked improvement in the depiction of fantastical and imaginative concepts. This preference extended to more grounded subjects as well, with a 75% preference rate observed for images of ‘vehicles’, suggesting enhanced realism and detail in rendering complex objects. These findings collectively demonstrate the system’s capacity to not only generate images from text prompts, but to do so with a quality and aesthetic appeal consistently preferred by human observers.

The pursuit of genuinely creative outputs, as explored within this study of diffusion models, echoes a fundamental design principle: elegance born of deep understanding. The research intentionally navigates the low-probability regions of the latent space, seeking novelty-a deliberate tuning of the system to produce unexpected, yet coherent, imagery. This mirrors the idea that good design whispers, not shouts; the generated images aren’t simply loud displays of technical capability, but nuanced expressions born from a carefully orchestrated exploration of possibility. As Yann LeCun aptly states, “Everything we do in AI is about finding the right inductive biases.” This work exemplifies that principle, revealing how targeted biases within the diffusion model can unlock regions of the latent space previously unexplored, ultimately fostering a more imaginative and aesthetically compelling form of creative AI.
Where the Imagination Leads
The pursuit of novelty, as this work demonstrates, isn’t simply a matter of stochastic wandering. Targeting low-probability regions within the latent space of diffusion models offers a more directed, if still imperfect, approach to creative generation. Yet, the very notion of ‘low probability’ demands scrutiny. Probability distributions reflect the data upon which models are trained – a reflection of the existing, not necessarily the genuinely new. A truly creative system must, in some sense, transcend its training, and that requires a rethinking of how ‘surprise’ is quantified and encouraged.
Current metrics, focused on arousal potential and subjective assessment, remain stubbornly human-centric. The aesthetic preference for complexity, for a certain balance between order and chaos, is not a universal constant. The challenge lies in designing systems that can evaluate novelty independently of human bias, perhaps by identifying structures that are both unexpected and internally coherent – elegance, in essence. Beauty scales – clutter doesn’t.
Further refinement isn’t about rebuilding, but editing. Refactoring the exploration strategy within the latent space, incorporating principles of information theory and perhaps even drawing inspiration from the biological mechanisms of creativity, holds more promise than simply scaling up model size. The goal isn’t to mimic the human imagination, but to create a different kind of imagination – one that complements, rather than replicates, our own.
Original article: https://arxiv.org/pdf/2601.22125.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-01 05:26