Author: Denis Avetisyan
Researchers have developed a diffusion-based framework that enables robots to learn and reuse manipulation skills more efficiently, paving the way for more adaptable and versatile robotic systems.
![The system learns a state-adaptive policy through a Skill Mixture-of-Experts framework, where raw observations are encoded into state features and projected onto an orthogonal basis [latex]B(s)[/latex] generated via QR retraction, enabling action reconstruction through [latex]B(s)(g \odot z)[/latex]-a process refined by reconstruction, diffusion, gate regularization, and alignment losses-and, crucially, maintains consistent expert roles across changing states via sticky-gated weights.](https://arxiv.org/html/2601.21251v1/x2.png)
This work introduces Skill Mixture-of-Experts Policy (SMP), a method leveraging sparse gating and an orthonormal basis to improve multi-task performance and reduce computational cost in robot manipulation.
Scaling diffusion-based policies for complex robot manipulation remains challenging due to the computational cost of representing diverse tasks. This paper, ‘Abstracting Robot Manipulation Skills via Mixture-of-Experts Diffusion Policies’, introduces a Skill Mixture-of-Experts Policy (SMP) that learns a compact, reusable skill basis via state-adaptive gating and an orthonormal representation. SMP achieves improved multi-task performance and reduced inference cost compared to large diffusion models through sparse expert activation. Could this approach unlock truly scalable and adaptable robot learning, enabling robots to rapidly generalize to novel environments and tasks?
The Challenge of Fragile Robotic Skill
Historically, robotic control has heavily depended on explicitly programmed skills – a process requiring engineers to meticulously define every movement and action for specific scenarios. This approach, while effective in highly structured environments, proves brittle when confronted with even slight variations. A robot programmed to pick up a specific object in a fixed location, for instance, may fail when that object is slightly rotated or moved. The limitations stem from the inability of hand-engineered skills to account for the infinite nuances of the real world, hindering a robot’s capacity to adapt to new tasks or environments without substantial re-programming. This reliance on pre-defined behaviors represents a significant barrier to achieving truly autonomous and versatile robotic systems capable of operating reliably in dynamic, unstructured settings.
The acquisition of robust manipulation skills in robotics is fundamentally challenged by the ‘curse of dimensionality’. This phenomenon arises because a robot’s possible actions – its action space – and the myriad of potential environmental states – its state space – combine to create an exponentially growing complexity. Even seemingly simple tasks require navigating this vast space, making exhaustive search or traditional programming impractical. A robot arm, for example, possesses numerous degrees of freedom, and each joint angle contributes to the overall dimensionality. Combined with variations in object pose, lighting, and unforeseen disturbances, the robot must effectively operate within a space where relevant information is sparse and the computational cost of exploring every possibility becomes prohibitive. Overcoming this requires developing algorithms capable of efficient representation, generalization, and adaptation within these high-dimensional spaces, allowing robots to learn and perform complex tasks reliably.
Current robotic systems often demonstrate brittle performance when faced with even slight variations in their operating environment or task requirements. While a robot might reliably grasp a specific object in a controlled setting, its success rate can plummet when presented with a novel object, altered lighting, or unexpected disturbances. This lack of generalization stems from the reliance on narrowly trained policies that fail to capture the underlying principles of robust manipulation. Existing machine learning approaches, though capable of achieving impressive results in specific scenarios, frequently struggle to transfer learned skills to new, unseen situations. The inherent complexity of real-world dynamics and the vastness of possible scenarios present a significant challenge, demanding more adaptable and resilient robotic control strategies that prioritize consistent performance across diverse and unpredictable conditions.
The development of truly adaptable robots hinges on overcoming a critical limitation: the efficient representation and reuse of learned skills. Current robotic policies often struggle with complexity, requiring vast amounts of data to master even simple tasks and exhibiting poor transferability to novel situations. A more effective approach necessitates policies that can distill experience into compact, generalizable representations, allowing robots to rapidly adapt to new challenges by building upon previously acquired knowledge. This isn’t merely about storing successful sequences of actions; it demands a hierarchical understanding of skills, where complex behaviors are decomposed into reusable primitives and combined flexibly to address unforeseen circumstances. Consequently, research focuses on techniques like skill embeddings and meta-learning, aiming to create policies that don’t just perform tasks, but learn how to learn them, ultimately unlocking a new level of robotic autonomy and robustness.
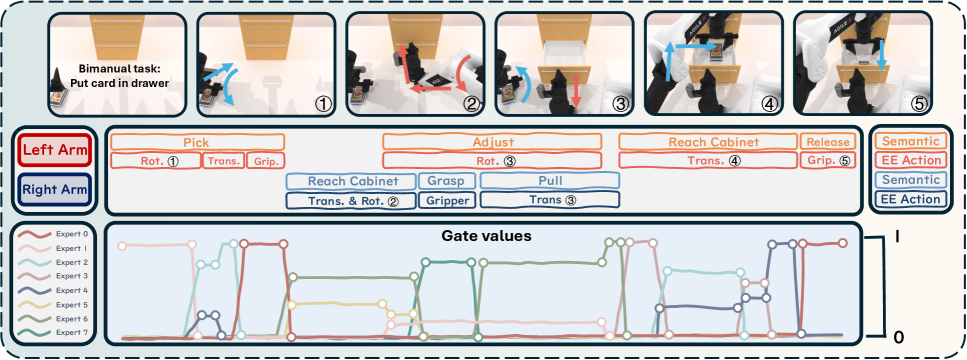
Skill Modulation: A Foundation for Adaptive Control
The Skill Mixture-of-Experts Policy (SMP) employs a diffusion-based approach to policy learning, constructing a state-adaptive orthonormal action basis. This basis allows the policy to represent complex actions as linear combinations of fundamental skills, where the weighting of these skills is determined by the current state of the environment. The orthonormal constraint ensures that the learned skills are decorrelated, improving the efficiency of the representation and preventing redundancy. By adapting the action basis to the current state, SMP achieves flexible control, enabling the robot to respond effectively to varying conditions and tasks without requiring retraining for each new scenario.
The Skill Mixture-of-Experts Policy (SMP) employs a modular architecture consisting of multiple skill experts, each trained to perform a specific manipulation primitive – such as reaching, grasping, or rotating – thereby decomposing complex tasks into simpler, manageable components. Each expert maintains a dedicated set of parameters optimized for its specialized skill. During execution, the policy routes incoming state information to a subset of these experts, activating their corresponding action distributions. The weighted combination of these activated experts’ outputs forms the final action, allowing the robot to dynamically assemble and blend skills to address a wider range of tasks than any single skill could achieve independently. This modularity facilitates both learning and generalization, as new skills can be added without retraining the entire policy, and existing skills can be recombined to solve novel problems.
Sticky routing within the Skill Mixture-of-Experts Policy (SMP) operates by adding a regularization term to the routing distribution. This term encourages the retention of previously activated skill experts across consecutive time steps. Specifically, the regularization penalizes deviations from the previous activation pattern, effectively ‘sticking’ to established skill combinations. This mechanism promotes phase-consistent behavior by reducing abrupt shifts in skill activation and fostering smoother transitions between actions, thereby enhancing the stability and predictability of the robot’s movements.
The Skill Mixture-of-Experts Policy (SMP) facilitates the abstraction of manipulation skills by learning a parameterized set of reusable action primitives. This abstraction is achieved through the policy’s ability to decompose complex tasks into combinations of these learned skills, rather than requiring the robot to relearn motions for each new situation. Consequently, the robot demonstrates improved generalization to previously unseen scenarios and increased robustness to disturbances. By representing skills as independent, yet combinable, units, the policy mitigates the need for extensive task-specific training, allowing for efficient adaptation to variations in object properties, environmental conditions, and task goals.
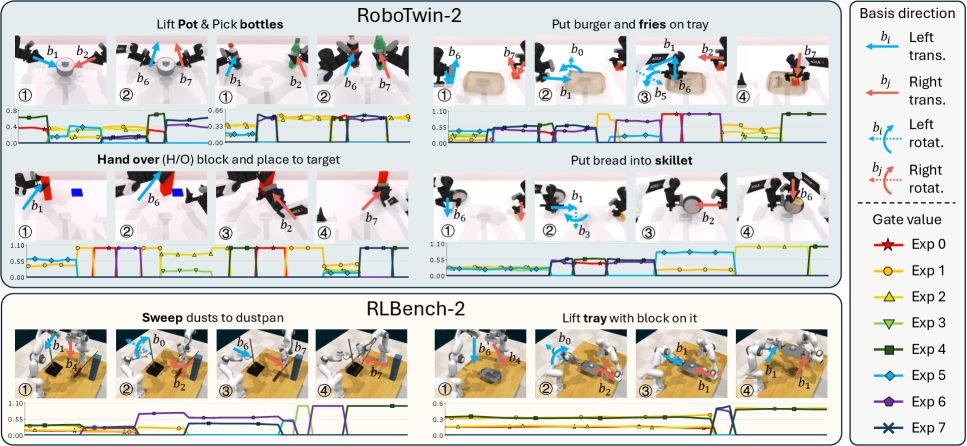
Evidence of Consistent and Adaptive Skill Selection
Skill Management Policy (SMP) utilizes expert activation as a core mechanism for determining task relevance. This process involves assessing the current state and task requirements to identify which pre-defined skills, or ‘experts’, are most appropriate for execution. Activation is not uniform; instead, SMP dynamically assigns weights to each expert based on its perceived utility in the present context. This selective activation strategy allows the system to focus computational resources on a subset of skills, improving efficiency and performance compared to methods that utilize all skills simultaneously. The selection is performed to prioritize skills deemed most relevant, effectively tailoring the system’s behavior to the specific demands of the current situation.
Adaptive expert selection within the Skill Modulation Policy (SMP) operates by dynamically determining which experts are most relevant given the current state. This process refines the initial expert activation by assessing contextual information and adjusting the composition of active experts accordingly. Rather than relying on a pre-defined, static selection, SMP employs a probabilistic gating mechanism that weights experts based on their suitability to the present situation, allowing the system to prioritize and combine skills in a context-sensitive manner. This dynamic allocation of expertise enables SMP to achieve improved performance on complex tasks by leveraging a flexible and responsive skill basis.
The Sticky Dirichlet prior within the SMP framework promotes temporal consistency in skill selection by encouraging the model to maintain previously established routing patterns. This prior operates on the gate distribution, biasing the model towards selecting the same skills across consecutive time steps. The ‘sticky’ nature is implemented by adding a constant value to the concentration parameters of the Dirichlet distribution, effectively increasing the probability of retaining existing skill activations. This mechanism reduces frequent switching between skills, leading to more stable and predictable behavior, and is particularly effective in environments requiring sustained actions or sequences.
KL divergence regularization is implemented within the Sparse Mixture of Policy (SMP) framework to constrain the learned gate distribution and promote desired behavioral characteristics. This regularization technique measures the difference between the learned distribution over skill activations and a prior distribution, penalizing significant deviations. Specifically, the KL divergence term encourages the model to maintain a distribution close to the prior, preventing the emergence of overly confident or erratic skill selections. By minimizing this divergence during training, SMP ensures the learned gating mechanism produces a more stable and predictable skill activation pattern, contributing to consistent and reliable performance across diverse tasks and states.
Evaluations conducted on the RoboTwin-2 benchmark demonstrate that the Skill Modulation Process (SMP) achieves a multi-task success rate of 0.54. This performance metric represents the percentage of tasks completed successfully across a diverse set of robotic manipulation challenges within the benchmark environment. The achieved success rate indicates a measurable improvement in task completion compared to baseline models, signifying the efficacy of the SMP architecture in handling complex, multi-faceted robotic tasks. The RoboTwin-2 benchmark provides a standardized evaluation framework, facilitating objective comparison of SMP against alternative approaches in the field of robotic skill acquisition and generalization.
System performance benchmarks indicate that SMP achieves an inference time of 107ms, comparable to existing baseline models. This performance is maintained despite employing a sparse activation strategy, wherein only approximately 80 million parameters are actively utilized during inference. This contrasts with models that activate a significantly larger parameter set, suggesting that SMP achieves computational efficiency without sacrificing speed. The selective activation of parameters contributes to reduced computational load and memory requirements during operation.
Implementation of a state-adaptive skill basis resulted in a 14 percentage point improvement in performance metrics when contrasted with a system employing a fixed skill basis. This improvement indicates that dynamically selecting skills based on the current state of the system allows for more efficient and effective task completion. The adaptive approach enables the system to prioritize and utilize the most relevant skills for each specific situation, leading to enhanced overall performance compared to a static skill allocation.
![Adaptive expert activation on RoboTwin-2 significantly improves success rates by dynamically recruiting experts, with performance saturating at around 2.3 experts on average, as determined by a coverage threshold [latex] \tau_{m} [/latex].](https://arxiv.org/html/2601.21251v1/x9.png)
Implications for the Future of General-Purpose Robotics
Skill Management Policies (SMP) represent a significant step towards more versatile robotic systems by enabling robots to learn and execute a diverse set of tasks without extensive, task-specific retraining. Traditionally, each new skill demanded a complete relearning process, proving inefficient and limiting adaptability. SMP, however, facilitates multi-task learning by allowing robots to build upon previously acquired knowledge; a robot proficient in grasping can more easily learn to manipulate objects, and this learned capability informs subsequent skill acquisition. This approach doesn’t simply combine skills, but rather allows for compositional generalization, where combinations of learned ‘expert’ modules create solutions for novel situations, drastically reducing the time and data required for adaptation and broadening the scope of tasks a single robot can effectively perform.
A significant benefit of the Sparse Mixture of Policies (SMP) framework lies in its capacity for transfer learning, allowing robotic systems to apply knowledge gained in one setting to entirely new and unforeseen environments. Rather than requiring complete retraining for each new task or locale, the robot can leverage previously learned ‘expert’ skills – honed through experience – and adapt them to the present situation. This is achieved by selectively activating the most relevant experts within the mixture, effectively repurposing existing knowledge instead of starting from scratch. The result is a substantial reduction in training time and data requirements, paving the way for robots that can rapidly deploy and function effectively in a wider range of real-world scenarios, even those significantly different from their original training conditions.
The efficiency of Sparse Mixture of Polynomials (SMP) stems from its strategic activation of only a select few “expert” subnetworks within the larger neural network architecture. Rather than engaging the entire network for every task, SMP identifies and utilizes only the subnetworks most relevant to the current input, dramatically reducing computational load. This sparse activation is particularly beneficial for deployment on resource-constrained platforms, such as embedded systems or robots with limited processing power and battery life. By minimizing the number of active parameters, SMP enables complex behaviors to be executed with significantly lower energy consumption and latency, paving the way for more agile and responsive robotic systems. The approach allows for substantial gains in performance without requiring increasingly powerful hardware, marking a critical step toward practical and scalable general-purpose robotics.
The pursuit of truly versatile robotics has long been hampered by the difficulty of creating systems that can readily generalize beyond narrowly defined tasks; however, recent developments in skill modularization and sparse mixture of policy approaches are demonstrably accelerating progress towards this ambition. By enabling robots to rapidly assimilate new skills and adapt to unforeseen circumstances without extensive retraining, these techniques facilitate a level of behavioral flexibility previously unattainable. This adaptability isn’t merely about executing a wider repertoire of actions, but about doing so reliably in real-world settings characterized by unpredictable change and sensory ambiguity – paving the way for robotic systems capable of operating effectively across diverse applications and environments, and ultimately, approaching the functional breadth of human intelligence.

The pursuit of reusable skills, as demonstrated by the Skill Mixture-of-Experts Policy, echoes a fundamental tenet of robust system design. If the system looks clever, it’s probably fragile. The SMP framework, with its state-adaptive orthonormal basis and sparse gating, strives for an elegance that avoids unnecessary complexity. It suggests that true intelligence isn’t about maximizing features, but about distilling behavior to its essential components – a principle of parsimony that minimizes inference cost. As Barbara Liskov once noted, “It’s one of the great tragedies in computer science that we haven’t been able to figure out how to make systems more reliable.” This work represents a step towards that goal, by prioritizing clarity and modularity in the construction of robot manipulation skills.
What’s Next?
The pursuit of abstracted skill spaces, as demonstrated by this work, often feels akin to building a cathedral with LEGOs. The elegance of the diffusion-based approach, and the constraint to an orthonormal basis, is commendable. However, the true test lies not in achieving sparse activation during inference, but in establishing a robust and generalizable foundation. If the system survives on duct tape-constant re-tuning of the gating network, for example-it’s probably overengineered. The current emphasis on maximizing performance on a pre-defined suite of tasks risks creating brittle expertise, incapable of adapting to the inevitable novelty of the physical world.
A critical, and largely unaddressed, question is the nature of the ‘ground truth’ used to train these skill abstractions. Current methods implicitly assume a clean separation of skills, a convenient fiction. In reality, manipulation is rarely decomposable into isolated primitives. Future work must grapple with the messy overlap, the contextual dependencies, and the inherent ambiguity of action. Modularity without context is an illusion of control.
The path forward likely lies in embracing a more holistic perspective. Rather than striving for perfect skill abstraction, the focus should shift towards developing systems capable of learning the appropriate level of abstraction, dynamically adapting their internal representation to the demands of the environment. This demands a deeper understanding of the relationship between structure and behavior, recognizing that the ‘skill’ is not a static entity, but an emergent property of the interaction between agent and world.
Original article: https://arxiv.org/pdf/2601.21251.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-01 04:01