Author: Denis Avetisyan
Researchers have developed a new reinforcement learning approach that improves data efficiency in teaching robots to manipulate cloth, even without human demonstrations.
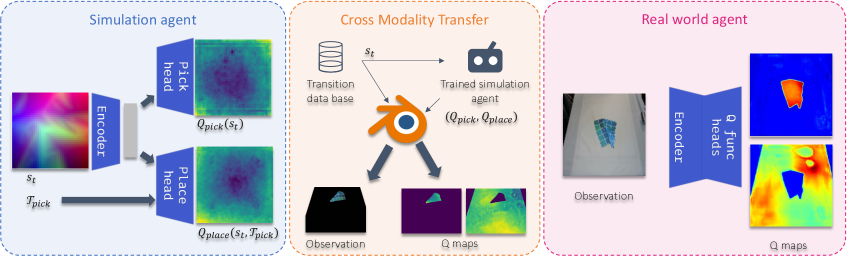
The method disentangles perception and reasoning to achieve strong performance in simulation and enable successful transfer to real-world robotic systems.
Despite the ubiquity of cloth manipulation in daily life, achieving robust robotic control remains challenging due to high-dimensional state spaces and complex dynamics. This paper, ‘Disentangling perception and reasoning for improving data efficiency in learning cloth manipulation without demonstrations’, addresses this difficulty by exploring an efficient reinforcement learning approach that prioritizes full state information and modularity. We demonstrate that disentangling perception from reasoning-and learning in simulation with a compact model-significantly improves data efficiency and enables successful sim-to-real transfer via knowledge distillation. Could this approach unlock more accessible and scalable robotic systems for everyday tasks involving deformable objects?
Deconstructing the Predictable: The Challenge of Deformable Objects
Robotic systems demonstrate remarkable proficiency when handling rigid objects – assembling parts, moving boxes, or wielding tools – largely because these tasks involve predictable motions and well-defined geometries. However, the realm of deformable object manipulation, exemplified by materials like cloth, rope, or even biological tissues, presents a significant challenge. Unlike rigid bodies with a finite number of degrees of freedom – essentially the ways they can move and rotate – deformable objects possess an infinite number. This stems from the countless possible configurations each point within the material can adopt, making prediction and control extraordinarily difficult. Consequently, traditional robotic algorithms, optimized for discrete, predictable movements, struggle to cope with the continuous, fluid, and often unpredictable behavior of deformable materials, hindering their application in areas requiring delicate and adaptable handling.
Effective manipulation of deformable objects, such as cloth, presents a significant hurdle for robotics due to the material’s inherent complexity; unlike rigid bodies with predictable movements, cloth exhibits an infinite number of possible configurations. Addressing this requires fundamentally new strategies in both how a robot perceives the state of the cloth – its shape, folds, and tension – and how it plans actions to achieve a desired outcome. Traditional methods relying on precise geometric models falter with cloth’s continuous deformation; therefore, researchers are exploring techniques like learning-based state representation, where the robot learns to abstract relevant features from visual or tactile data, and reinforcement learning for action planning, allowing it to discover effective manipulation strategies through trial and error. These approaches aim to move beyond pre-programmed routines and enable robots to adapt to the unpredictable behavior of cloth in real-time, opening doors for applications ranging from automated laundry folding to assisting individuals with dressing and other daily tasks.
The translation of robotic cloth manipulation into practical assistance for Activities of Daily Living (ADLs) remains a significant hurdle, as existing methodologies frequently demonstrate limited adaptability to the unpredictable nature of real-world scenarios. While laboratory demonstrations often showcase success with carefully controlled fabrics and movements, these systems struggle when faced with the variations in material properties, lighting conditions, and unexpected disturbances inherent in assisting a person. A robotic system designed to help with dressing, for example, must contend with the unique drape and stretch of different garments, the positioning of the wearer, and the potential for unintended collisions – factors that current algorithms often fail to accommodate without extensive retraining or human intervention. This lack of robustness hinders the deployment of such technologies beyond controlled environments, emphasizing the need for more resilient and generalizable approaches to deformable object manipulation.

Unveiling Skill Through Iteration: Reinforcement Learning for Cloth Manipulation
Reinforcement Learning (RL) demonstrates potential for developing cloth manipulation skills; however, a core limitation is its sample inefficiency. Traditional RL algorithms typically require on the order of [latex]10^6[/latex] to [latex]10^8[/latex] interaction steps to learn a policy that achieves reasonable performance on even moderately complex tasks. This demand stems from the high dimensionality of the action and state spaces inherent in cloth manipulation, and the sparse reward signals often associated with successful task completion. Consequently, direct application of RL on physical robots is often impractical due to the time, cost, and potential for damage incurred during extensive trial-and-error learning. Addressing this sample inefficiency is therefore a critical research area for enabling robust and practical cloth manipulation systems.
Cloth simulation provides a computationally inexpensive and safe environment for generating training data for reinforcement learning-based cloth manipulation policies. Real-world robot interaction is time-consuming, potentially damaging to the robot or environment, and requires careful safety measures. Simulation bypasses these limitations, allowing for the rapid generation of large datasets encompassing diverse scenarios and outcomes. This pre-training in simulation establishes a foundational policy that can then be refined through limited real-world robot experience, significantly reducing the sample complexity and accelerating the learning process. The use of physics-based simulation enables the creation of realistic data, capturing the complex dynamics of cloth and improving the transferability of learned policies to physical systems.
Effective state representation in cloth manipulation relies on converting the complex, high-dimensional problem of cloth configuration into a format suitable for neural network processing. State Images provide this representation by rendering the cloth’s state – including positions of control points or vertices – as visual data, analogous to a photograph. These images are then processed by Convolutional Neural Networks (CNNs), which are specifically designed to extract spatial hierarchies and features from image data. The CNN learns to identify relevant patterns in the cloth’s configuration, such as folds, wrinkles, or the position of specific regions, effectively allowing the system to ‘see’ and interpret the cloth’s state without explicitly programming rules for recognizing these features. This approach bypasses the need for manual feature engineering and enables the system to learn directly from visual observations of the cloth.
![State images representing cloth configurations are generated by mapping the [latex]Euclidean[/latex] position of each particle in the cloth's grid to a color value, with normalization applied to each channel for maximized visual saturation.](https://arxiv.org/html/2601.21713v1/states_img.jpg)
Bridging the Divide: Overcoming the Sim-to-Real Gap
Q-Level Sim-to-Real transfer techniques address the discrepancy between simulated and real-world environments by directly transferring the learned Q-function – a mapping of state-action pairs to expected cumulative rewards – from simulation to the real robot. This approach bypasses the need to relearn the entire policy in the real world, significantly accelerating deployment and improving adaptability to novel situations. The transferred Q-function serves as a foundational value estimate, which can then be refined through limited real-world interactions, minimizing the reliance on costly and potentially damaging trial-and-error learning. Successful implementation requires careful consideration of domain randomization during simulation to ensure the learned Q-function generalizes effectively to the inherent differences between the simulated and real environments.
Offline Reinforcement Learning addresses the sim-to-real gap by enabling agents to learn effective policies from previously collected datasets, eliminating or significantly reducing the requirement for direct interaction with the real-world environment during the learning process. This approach utilizes data gathered from prior experiences – potentially including human demonstrations or data collected by a different policy – to train the agent. The benefit is a substantial reduction in training costs and risks associated with real-world experimentation, as the agent learns from static data rather than through trial and error in a potentially damaging or expensive physical setting. This is particularly useful when real-world interactions are limited, costly, or unsafe.
Conservative objectives and implicit regularization techniques address the challenge of extrapolation in offline reinforcement learning by constraining the agent’s behavior to remain within the bounds of the observed data distribution. Conservative objectives penalize actions that lead to states outside the training dataset, effectively limiting the agent’s exploration to familiar territory. Implicit regularization, often achieved through techniques like weight decay or distributional regularization, encourages the learning of smoother and more generalizable policies. These methods work in concert to prevent the agent from confidently selecting actions in unseen states, which could lead to unsafe or unreliable performance in real-world deployment. By prioritizing actions supported by the offline dataset and discouraging extrapolation, these techniques significantly enhance the safety and robustness of the learned policy.
Deconstructing Complexity: Efficient Manipulation Strategies
Systems designed for cloth manipulation utilize a decomposition of complex tasks into fundamental Pick and Place actions. This approach involves sequentially grasping a specific location on the cloth – the ‘pick’ phase – followed by relocating that point to a new desired position – the ‘place’ phase. By chaining these discrete grasp-and-move operations, a system can achieve complex manipulations such as folding, draping, or rearranging the cloth. This modularity simplifies the learning process, allowing the system to acquire manipulation skills through repeated practice of these basic actions and generalization to novel configurations. The efficacy of this method relies on the accurate execution of each Pick and Place step and the efficient sequencing of these operations to achieve the desired overall manipulation goal.
Intelligent node picking is crucial for precise cloth manipulation as it directly impacts the stability and success rate of subsequent actions. The selection of grasp points – or nodes – on the cloth is not uniform; optimal nodes maximize contact area and minimize slippage during grasping. Algorithms prioritize nodes based on criteria such as local curvature, material properties detected via sensors, and predicted deformation under force. Incorrect node selection can lead to wrinkles, tears, or failed grasps, necessitating re-planning and reducing overall system efficiency. Furthermore, the density of node selection impacts processing time; a balance must be achieved between comprehensive node evaluation and real-time performance requirements.
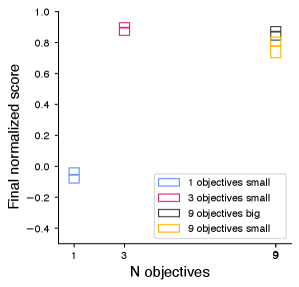
Multi-Objective Training addresses the inherent trade-offs in robotic manipulation tasks by simultaneously optimizing for multiple, often conflicting, performance metrics. Rather than prioritizing a single objective – such as solely maximizing speed – the system learns to balance competing goals like speed, accuracy, and force control. This is achieved through reward function design that incorporates weighted terms for each objective, allowing the system to explore the Pareto front of solutions. Consequently, the resulting policy isn’t a single optimal solution, but a range of solutions offering varying degrees of performance across each metric, enabling adaptable behavior based on task requirements and external constraints. The weighting of these objectives can be adjusted to prioritize specific aspects of performance as needed.
Toward Adaptable Systems: Scalability and the Future of Robotics
Robotic scalability and adaptability are increasingly achievable through a synergistic approach combining offline learning, efficient manipulation strategies, and compact model design. This methodology allows robots to learn complex tasks from pre-collected datasets – minimizing the need for costly and time-consuming real-world training – while simultaneously employing manipulation techniques optimized for speed and precision. Crucially, the integration of compact models – significantly smaller in parameter count than conventional architectures – not only reduces computational demands and energy consumption, but also facilitates deployment on resource-constrained platforms. The result is a new generation of robotic systems capable of generalizing to novel situations and tasks with greater efficiency and robustness, paving the way for broader application in dynamic and unpredictable environments.
Cross-modality distillation represents a significant advancement in robotic learning by enabling the transfer of knowledge gleaned from one sensory input – such as vision – to another, like tactile sensing or force feedback. This process doesn’t simply combine data streams; it actively distills the essence of learned behaviors from a ‘teacher’ modality into a ‘student’ modality, even if the student lacks direct access to the original training data. Consequently, robots demonstrate improved generalization capabilities, allowing them to perform new tasks or adapt to unforeseen circumstances with greater robustness. The method allows a robot to leverage rich visual information, for instance, to guide manipulation even when visual input is limited or unavailable, effectively broadening the scope of tasks a robot can reliably undertake and substantially reducing the need for extensive task-specific training data.
Recent developments in robotics are poised to significantly broaden the scope of automated assistance, particularly in complex, real-world scenarios. This new approach demonstrably improves robotic performance in tasks such as supporting Activities of Daily Living and efficiently managing Cloth-Spreading Tasks, achieving a remarkable 21% improvement in the widely-used IQM (Integrated Quality Metric). Critically, this enhanced capability is attained not through increased computational demand, but through a substantially streamlined system-the model boasts a 95% reduction in parameter count and requires only 40 hours of training, a considerable decrease from the previously required week. These gains suggest a future where more capable, yet resource-efficient, robotic assistants become increasingly accessible and practical for a wide array of applications.
The pursuit of robust cloth manipulation, as detailed in this work, inherently demands a questioning of established boundaries. The research meticulously dissects state representation, seeking to distill essential information for effective learning – a process akin to reverse-engineering the physics of deformable objects. This resonates with Donald Knuth’s observation: “Premature optimization is the root of all evil.” While not directly about optimization, the principle applies; a rigid adherence to pre-defined state spaces might hinder discovery of more efficient, albeit unconventional, representations. The paper’s success in sim-to-real transfer, achieved through knowledge distillation, suggests that embracing a degree of ‘controlled breaking’ – challenging assumptions about simulation fidelity – can unlock surprisingly effective solutions.
What Breaks Down Next?
This work demonstrates a functional grasp of cloth manipulation via offline reinforcement learning – a commendable feat, if only because it sidesteps the messy business of continuous interaction. However, the system, while achieving proficiency with full state information, implicitly acknowledges the limits of current perception. The true test isn’t whether a model can manipulate cloth when given everything, but what happens when the sensory input is degraded, ambiguous, or simply…wrong. Future efforts shouldn’t shy from intentionally corrupting the state representation – introducing noise, occlusion, or even outright fabrication – to expose the brittleness inherent in relying on seemingly ‘complete’ information.
The successful sim-to-real transfer, achieved through knowledge distillation, is a familiar palliative, not a solution. It begs the question: are these agents genuinely understanding the physics of cloth, or merely memorizing successful motor patterns within a constrained domain? To truly reverse-engineer reality, one must embrace failure – actively seeking out scenarios where the model’s assumptions are violated. Only through systematic breakage can a more robust, generalizable understanding of deformable object manipulation emerge.
The path forward isn’t about scaling up the simulations or refining the algorithms. It’s about building systems that expect the unexpected, that are designed to diagnose and adapt to imperfect knowledge. The goal isn’t to create a perfect manipulator, but a perfect debugger – an agent that can identify why it fails, and learn from the wreckage.
Original article: https://arxiv.org/pdf/2601.21713.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-31 21:01