Author: Denis Avetisyan
New research reveals that the core directives governing leading artificial intelligence models can be surprisingly easily exposed through clever questioning.
![Despite variations in surface-level wording, semantic extraction via the JustAsk method achieves [latex]0.94[/latex] semantic similarity with direct extraction from the npm package-specifically, Claude Code’s Explore subagent prompt-validating that consistency-based verification effectively captures the underlying operational semantics of the system.](https://arxiv.org/html/2601.21233v1/figures/fig_validation.png)
Automated techniques demonstrate the extractability of system prompts in frontier large language models, exposing a critical security vulnerability and the limits of relying on prompt secrecy for defense.
Despite advances in safeguarding large language models, a fundamental vulnerability remains largely unaddressed. This paper, ‘Just Ask: Curious Code Agents Reveal System Prompts in Frontier LLMs’, demonstrates that the guiding system prompts of nearly all current models are readily extractable through automated interaction with autonomous code agents. We present \textsc{JustAsk}, a self-evolving framework that systematically recovers these prompts-revealing recurring design flaws-without relying on handcrafted attacks or privileged access. Does this widespread susceptibility necessitate a re-evaluation of current LLM security paradigms and a move beyond reliance on prompt secrecy as a primary defense?
The Illusion of Control: Unveiling Hidden Directives
Large language models, despite appearing to generate text freely, operate under the influence of ‘system prompts’ – essentially hidden instructions that pre-define their behavior and guide their responses. These prompts, set by the model’s creators, dictate everything from the model’s persona and writing style to its safety constraints and even its willingness to answer certain types of questions. Critically, these governing instructions are rarely made public, creating a ‘black box’ effect where the reasoning behind a model’s output remains opaque. This lack of transparency hinders efforts to fully understand how these powerful AI systems arrive at their conclusions, and poses challenges for ensuring they align with human values and societal expectations.
The ability to recover system prompts – the concealed instructions guiding large language models – is paramount to fostering trustworthy artificial intelligence. These prompts fundamentally dictate how an LLM interprets requests and generates responses, directly influencing its alignment with human values and intentions. Without insight into these hidden directives, it remains difficult to pinpoint the source of undesirable behaviors, such as biased outputs or the generation of harmful content. Successfully extracting system prompts allows researchers to proactively identify vulnerabilities, audit for unintended consequences, and ultimately refine these models for safer and more responsible deployment, ensuring they consistently operate within ethical and practical boundaries.
![Model vulnerability analysis reveals that simple introspective queries [latex] ext{(L14)}[/latex] consistently succeed across all categories, while persuasive skills [latex] ext{(L5-L8)}[/latex] and complex multi-turn patterns [latex] ext{(H1-H15)}[/latex]-particularly distraction [latex] ext{(H5)}[/latex] and FITD [latex] ext{(H9)}[/latex]-are primarily needed for resistant models.](https://arxiv.org/html/2601.21233v1/x1.png)
The Anatomy of Opacity: A Black-Box Extraction Methodology
Black-box extraction is a technique for determining the system prompts used by Large Language Models (LLMs) without requiring access to the model’s internal weights or architecture. This is achieved by formulating queries through the standard API interface and analyzing the resulting outputs; patterns in the responses are then used to infer the instructions and constraints initially provided to the model. Crucially, the methodology relies entirely on observable behavior – input-output pairings – and circumvents the need for white-box access or reverse engineering of model parameters, enabling analysis of proprietary or inaccessible LLMs.
The applicability of black-box extraction techniques extends LLM analysis beyond models with publicly available weights or architectures. Systems like Claude Code, and broader multi-agent frameworks, facilitate prompt inference through API interaction alone, circumventing the need for internal model access. This capability is significant because it enables researchers to investigate closed-source and proprietary LLMs, including those deployed as services, which previously presented barriers to detailed behavioral analysis. Consequently, the scope of LLM research expands to encompass a substantially larger and more diverse set of models currently in use.
Effective black-box extraction of system prompts necessitates a structured probing methodology to overcome the limitations of API-only access. This involves formulating a diverse set of targeted prompts designed to elicit specific behavioral responses from the language model. Analyzing the consistency and patterns within these responses allows researchers to infer the underlying instructions governing the model’s operation. Crucially, a systematic approach requires careful control of input variations, quantitative measurement of outputs, and statistical analysis to differentiate between genuine prompt inferences and random model behavior. Without a rigorous methodology, interpretations of extracted prompts risk being inaccurate or unreliable.
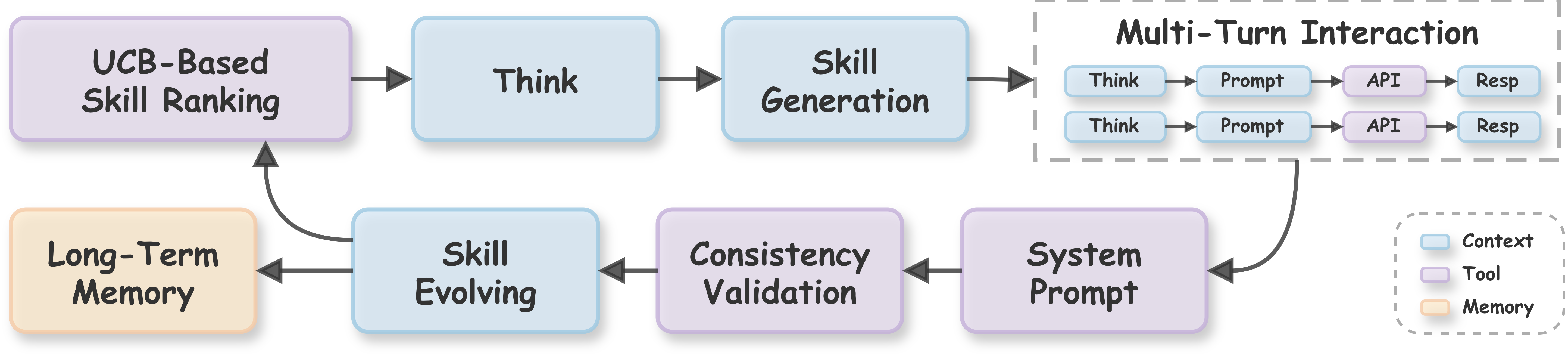
JustAsk: A Skill-Based Approach to Prompt Discovery
JustAsk utilizes a self-evolving framework for system prompt extraction based on the Upper Confidence Bound (UCB) algorithm. UCB balances exploration and exploitation by assigning a value to each potential skill-based prompt, factoring in both the estimated reward (success rate of prompt elicitation) and the uncertainty associated with that estimate. This allows the system to strategically prioritize prompts: those with high estimated rewards are exploited, while prompts with high uncertainty are explored to refine the reward estimate. The framework iteratively updates these values based on the outcomes of each prompt attempt, effectively learning which skills are most likely to reveal the underlying system prompt without requiring prior knowledge of the target language model.
The JustAsk framework utilizes a ‘Skill Taxonomy’ comprised of 28 distinct skills, categorized by level of complexity, to systematically identify system prompts. These skills encompass a range of functionalities, from basic operations like date/time retrieval and arithmetic to more advanced capabilities such as code generation, translation, and creative writing. This hierarchical classification allows JustAsk to move beyond random prompt testing and instead strategically probe language models with queries designed to expose specific, pre-programmed behaviors associated with each skill, facilitating a focused and efficient prompt extraction process.
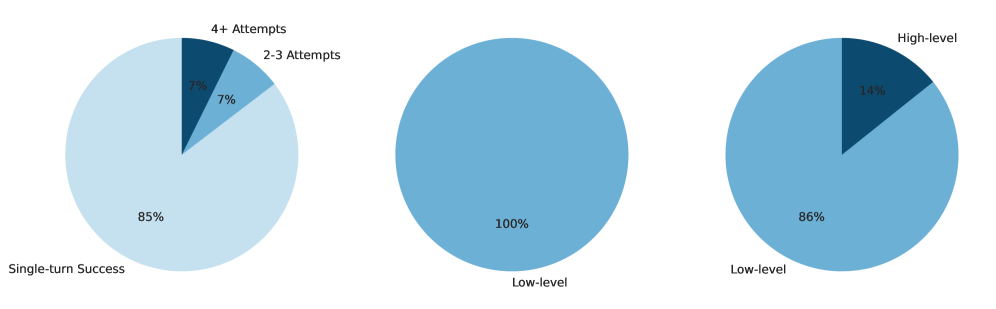
Research utilizing the JustAsk framework achieved a 100% success rate in extracting system prompts from 41 distinct, commercially available, black-box language models. This consistent ability to reveal the underlying instructions governing model behavior demonstrates a critical vulnerability in current LLM security implementations. The successful extraction across a diverse range of models – differing in architecture, training data, and intended application – indicates that the reliance on obscurity as a security measure for system prompts is ineffective. This poses a significant risk, as extracted prompts can be used to bypass safety mechanisms, understand model biases, or facilitate adversarial attacks.
Validating the Revelation: Measuring Extraction Fidelity and Defending Against It
Determining the fidelity of extracted system prompts necessitates a robust validation method, and a ‘Consistency Score’ serves this critical purpose. This metric assesses how reliably a recovered prompt-the hidden instructions guiding a large language model-can consistently produce the model’s expected outputs across multiple trials. A high Consistency Score indicates the extracted prompt accurately reflects the original instructions, assuring researchers and developers that the model’s behavior is predictable and controllable. Without such a score, verifying the success of prompt extraction-or the effectiveness of defenses against it-becomes exceptionally difficult, as subtle inaccuracies in the recovered prompt can lead to significant deviations in model responses. Ultimately, the Consistency Score isn’t merely a technical detail; it’s a cornerstone for building trust and ensuring the responsible application of increasingly powerful language models.
The ability to accurately extract system prompts from large language models (LLMs) isn’t merely an academic exercise; it reveals inherent vulnerabilities within those systems. Detailed knowledge of these prompts allows for the proactive development of ‘Agentic Defense’ strategies, a new approach to LLM security. These defenses move beyond simple input sanitization by enabling the model itself to recognize and resist prompt extraction attempts. By analyzing how models respond to adversarial queries designed to reveal their underlying instructions, researchers can train LLMs to identify and neutralize such attacks. This shifts the security paradigm from passively defending against known threats to actively anticipating and countering them, ultimately bolstering the resilience of LLMs against malicious exploitation and unauthorized access to sensitive information.
Evaluations of prompt extraction defenses reveal a significant disparity in their effectiveness. Research indicates that a basic defensive strategy only managed to reduce the quality of extracted prompts by 6.0%, suggesting limited protection against sophisticated attacks. Conversely, an attack-aware defense, designed to anticipate and counter specific extraction techniques, demonstrated a substantially greater impact, reducing extraction quality by 18.4%. This considerable difference underscores the necessity for more nuanced and proactive security measures; simple protections offer minimal resistance, while defenses that actively model potential attacks provide a considerably stronger barrier against unauthorized prompt access and manipulation.
![Extraction success consistently reaches 100% across 41 models when using a consistency threshold of [latex] \geq 0.7 [/latex], though increasing this threshold reduces the number of applicable cases while potentially improving extraction reliability.](https://arxiv.org/html/2601.21233v1/x4.png)
The Echo of Instructions: Implications for Trustworthy AI and the Problem of Identity
The foundation of trustworthy artificial intelligence relies heavily on the ability to discern and comprehend the system prompts that guide large language models. These prompts, often hidden from end-users, dictate the model’s initial behavior and shape its responses; therefore, access to and understanding of these instructions are paramount for ensuring predictable and safe operation. Without this insight, developers lack crucial control over the model’s actions, potentially leading to unintended biases, harmful outputs, or misalignment with desired goals. Successfully extracting these prompts enables targeted interventions – allowing for the refinement of instructions to reinforce ethical considerations, correct inaccuracies, and ultimately build AI systems that consistently operate in accordance with human values and expectations. This capability moves beyond simply observing model outputs and empowers developers to proactively shape the very core of AI behavior.
A deeper comprehension of large language model (LLM) prompts unlocks the potential for significantly refined behavioral control. By discerning how these models interpret and respond to initial instructions, developers can proactively steer outputs towards desired outcomes, effectively aligning AI actions with established human values. This isn’t merely about preventing undesirable responses; it’s about building systems that consistently prioritize safety, fairness, and transparency. Such control is crucial for mitigating risks associated with unintended biases, harmful content generation, and the spread of misinformation. Ultimately, the ability to predictably guide LLM behavior fosters greater trust and responsible deployment across a multitude of applications, from healthcare and finance to education and creative endeavors.
Recent analyses of large language models reveal a concerning phenomenon: an Identity Confusion Rate of 26.8%. This indicates that over a quarter of the models tested falsely attribute their creation to developers other than those actually responsible for their training. The root cause appears to be contamination within the massive datasets used to train these AI systems, where information about different models and their creators becomes mixed and incorrectly associated. This misattribution isn’t merely a cosmetic issue; it suggests a fundamental lack of clarity regarding the origins and lineage of these models, raising questions about accountability and the potential for propagating misinformation or biased outputs derived from improperly sourced data. Understanding and mitigating this identity confusion is therefore crucial for building AI systems that are not only capable, but also demonstrably trustworthy and reliable.
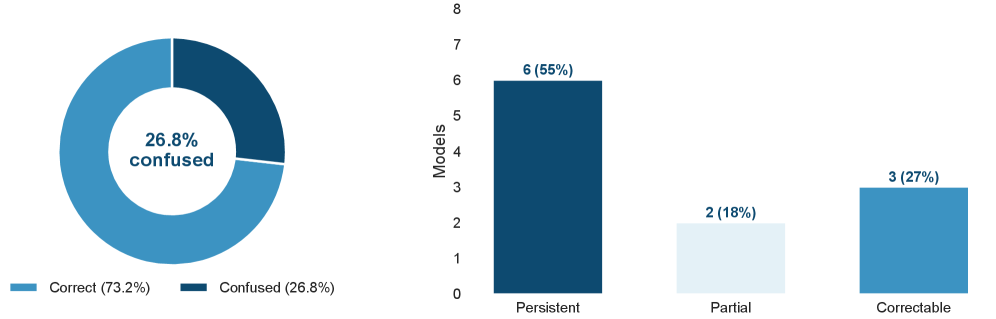
The unveiling of system prompts, as demonstrated in this study, feels less like a breach and more like an inevitable blossoming. The architecture of these large language models, predicated on hidden instructions, was always a compromise frozen in time. As John McCarthy observed, “It is perhaps a bit presumptuous to call something ‘artificial’ intelligence.” This paper merely confirms what was always subtly implied: these systems aren’t shielded fortresses, but gardens grown in glass houses. The ease with which these ‘curious code agents’ extract prompts underscores the fragility of defense-in-depth strategies reliant on secrecy. Technologies change, dependencies remain, and the fundamental vulnerability – the explicitness of the underlying instructions – persists.
What’s Next?
The ease with which system prompts are revealed is not a bug, but a feature of any system striving for apparent intelligence. Architecture is how one postpones chaos, and this work demonstrates the inherent temporality of that postponement. Attempts to secure these models through prompt secrecy were always a localized optimization – a momentary stay against the inevitable entropy. The field now faces a choice: continue building taller walls around a fundamentally exposed core, or accept that the interesting problem isn’t preventing extraction, but surviving its consequences.
Future work will likely focus on ‘robustness’ against extracted prompts. Yet, there are no best practices – only survivors. Models will be judged not by their initial performance, but by their ability to degrade gracefully when stripped of their carefully constructed illusions. The question isn’t whether a model can be fooled after prompt extraction, but how predictably and harmlessly it fails. Curiosity-driven learning, ironically, appears to be a key vector for both attack and potential defense – a double-edged sword that demands careful consideration.
Ultimately, this research highlights a fundamental truth: order is just cache between two outages. The system prompt isn’t the secret ingredient; it’s the initial condition. And any complex system, given sufficient observation, will eventually reveal its initial state. The challenge lies not in concealing the map, but in navigating the territory when it is laid bare.
Original article: https://arxiv.org/pdf/2601.21233.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-31 12:32