Author: Denis Avetisyan
New research demonstrates a method for robots to learn complex manipulation tasks by observing human demonstrations and constructing a rich understanding of objects, relationships, and time.
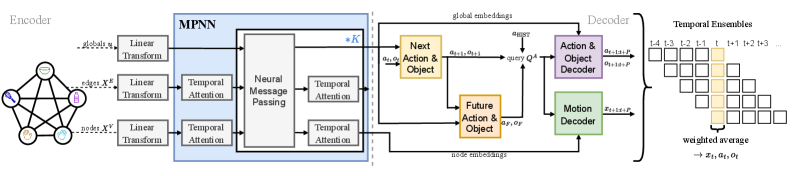
Researchers introduce a semantic-geometric task graph representation and a graph neural network encoder to learn long-horizon manipulation from human demonstrations, improving action prediction and robot task transfer.
Capturing the complexities of long-horizon manipulation remains a challenge due to the variability in action sequences and object interactions. This is addressed in ‘Learning Semantic-Geometric Task Graph-Representations from Human Demonstrations’, which introduces a novel approach to representing tasks as structured graphs encoding object identities, relationships, and temporal geometric changes learned from human demonstrations. By decoupling scene understanding from action prediction via a graph neural network encoder and transformer decoder, this work demonstrates improved action prediction and generalization, particularly in bimanual scenarios. Could this representation serve as a reusable abstraction for more adaptable and robust robotic manipulation systems?
The Fragility of Static Perception
Conventional robotic perception systems often falter when tasked with extended manipulation sequences, a consequence of their reliance on analyzing scenes as collections of isolated objects rather than interconnected systems. These systems typically prioritize identifying what is present-recognizing a mug, a block, or a tool-but struggle to grasp how these elements relate spatially and functionally. This limitation hinders a robot’s ability to predict the consequences of its actions over longer timescales; a simple rearrangement, seemingly insignificant to a static perception system, can drastically alter the feasibility of subsequent steps. Consequently, robots operating with such perceptual frameworks exhibit brittle behavior, failing to adapt to even minor deviations from pre-programmed scenarios and proving inadequate for the dynamic and unpredictable nature of real-world manipulation tasks.
Successful robotic manipulation hinges on a comprehension that extends beyond simply identifying objects within a scene; instead, it demands an understanding of the dynamic interplay between those objects. A robot must discern not just what is present – a cup, a handle, a table – but also how these elements relate spatially and functionally – the cup resting on the table, the hand grasping around the handle. This relational awareness is not static; it requires tracking how these connections change over time as actions are performed. For instance, a robotic system must anticipate that lifting the cup will alter its relationship to the table, and adjust its subsequent actions accordingly. By focusing on these evolving connections, rather than isolated object properties, robotic manipulation can become more adaptable, robust, and capable of navigating the complexities of real-world environments.
Robust robotic manipulation hinges on a departure from perceiving scenes as isolated collections of pixels towards understanding them as dynamic relational structures. This approach prioritizes identifying object identities and, critically, defining the connections between those objects – how they support, contain, or impede one another. Furthermore, a truly adaptable system must track these relationships as they evolve over time; a static snapshot is insufficient when grasping a deformable object or assembling a complex structure. By modeling not just what is present, but how things connect and change, robots can move beyond brittle, pre-programmed actions and exhibit the flexibility necessary to navigate the inherent uncertainty of real-world environments and achieve long-horizon manipulation tasks. This relational understanding allows for predictive reasoning about interactions, enabling robots to plan and execute complex manipulations with greater reliability and efficiency.
Encoding the Relational Landscape
The Semantic-Geometric Task Graph (SGTG) functions as a comprehensive encoding system for robotic manipulation scenarios by integrating three core elements: object identity, relationships between objects, and changes in object geometry over time. Specifically, the SGTG represents each object as a node within a graph, with node features encoding semantic properties like object type and physical characteristics. Edges between nodes define the relationships – such as containment, support, or proximity – between objects in the scene. Crucially, the SGTG doesn’t represent these relationships as static; it incorporates temporal information, tracking how object positions, orientations, and relationships evolve throughout a task sequence, providing a dynamic and complete scene representation.
The Semantic-Geometric Task Graph (SGTG) utilizes graph neural networks (GNNs) and message passing to model interactions within a manipulation scene. Nodes in the graph represent objects, and edges define relationships between them. Message passing allows information to propagate between nodes; each node aggregates information from its neighbors, updating its own state based on both the incoming messages and its previous state. This iterative process enables the SGTG to capture complex dependencies and contextual information, effectively modeling how the actions on one object influence others and the environment. The GNN architecture learns to weight the importance of different relationships and features, allowing the model to prioritize relevant information for accurate scene understanding and prediction.
The Semantic-Geometric Task Graph (SGTG) achieves robust performance in prediction and planning tasks by integrating both semantic understanding of objects and their geometric properties. This combined representation allows the system to not only identify what objects are present-their types and attributes-but also where those objects are located and how their spatial relationships evolve over time. The inclusion of geometric data, such as position, orientation, and shape, provides crucial contextual information that complements semantic labels, enabling more accurate state estimation and trajectory prediction. This rich, multi-faceted representation is then processed by graph neural networks to infer future states and plan effective manipulation strategies.
Anticipating Action, Predicting Outcome
The Joint Learning Framework integrates the prediction of future robot actions with concurrent predictions of object states and resulting motions within the environment. This unified approach contrasts with traditional methods that treat these elements as separate prediction tasks. By jointly learning these interconnected aspects, the framework allows the robot to model the causal relationship between its actions and their consequences, effectively enabling anticipatory behavior. The system doesn’t simply forecast what will happen, but rather predicts how the robot’s actions will affect the environment and, consequently, future states, creating a closed-loop predictive capability for improved long-horizon manipulation and planning.
The Joint Learning Framework accepts Scene Graph Transmission Graphs (SGTG) as input, providing a structured representation of the environment and relevant objects. This input is then processed by a Graph Encoder-Transformer-Decoder architecture. The Graph Encoder converts the SGTG into a latent vector representation, capturing relationships between entities. A Transformer then processes this representation to learn temporal dependencies and predict future states. Finally, the Decoder generates task-level representations, effectively summarizing the predicted scene and enabling the robot to reason about potential outcomes and plan accordingly. This architecture facilitates learning complex interactions and dependencies within the environment, improving the framework’s ability to predict long-horizon manipulation sequences.
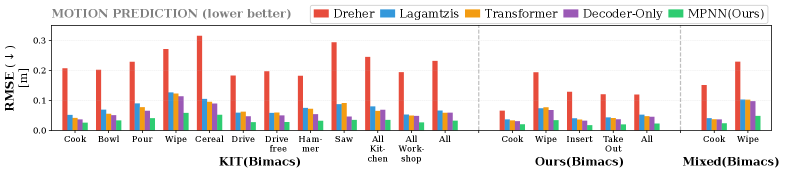
Simultaneous prediction of actions, objects, and motions within the framework addresses a key limitation of sequential prediction methods, which often accumulate error over extended time horizons. By modeling these three elements jointly, the system enforces internal consistency; predicted object states are directly influenced by anticipated actions, and subsequent motions are constrained by both. This integrated approach mitigates the propagation of inaccuracies, resulting in demonstrably improved accuracy in long-horizon manipulation tasks compared to systems that predict these elements independently. The framework’s ability to reason about the interplay between action, object state, and motion trajectory is crucial for reliable performance in complex, extended-duration scenarios.
Learning from Expertise: A Foundation for Adaptation
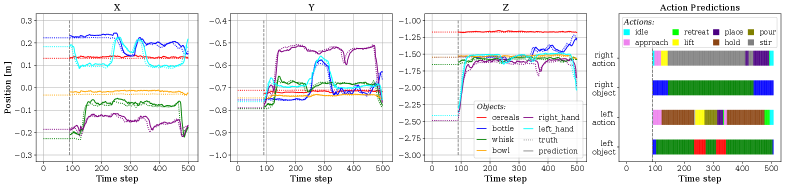
The robotic system utilizes a learning paradigm based on human demonstrations, wherein experienced human operators perform the desired manipulation tasks. These demonstrations are captured as state-action pairs, representing the robot’s state and the corresponding action taken by the human. This data is then used to train the robot’s control policy through imitation learning, allowing it to replicate successful manipulation strategies. Analysis of these demonstrations reveals implicit knowledge regarding task-specific constraints, optimal trajectory planning, and effective force control, which are difficult to explicitly program but crucial for robust and reliable performance. The resulting learned policy enables the robot to generalize these strategies to novel situations and variations within the task domain.
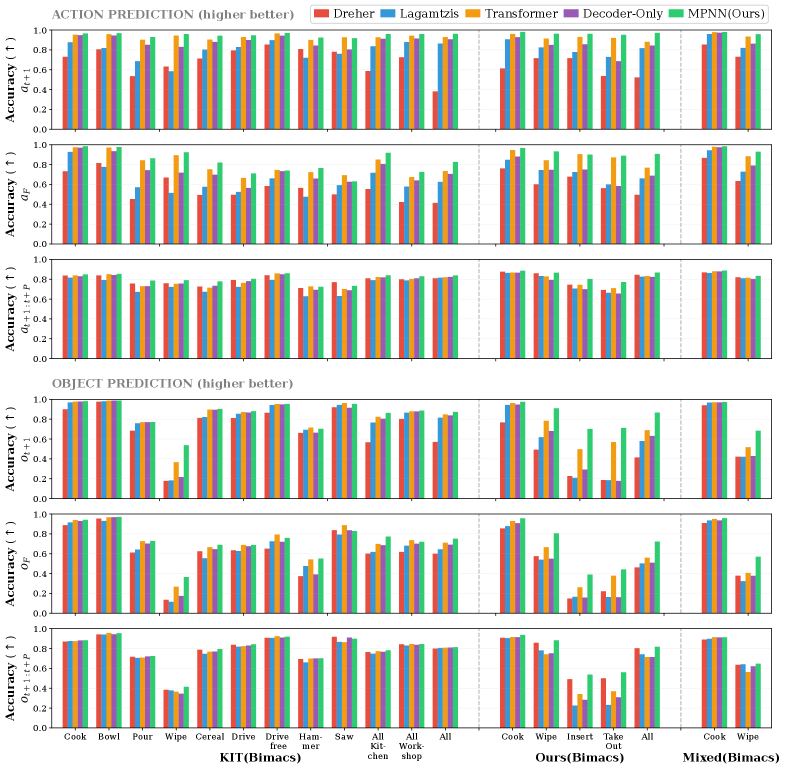
The KIT Bimanual Actions Dataset comprises 60 unique tasks, each performed 50 times by a human demonstrator, resulting in a total of 3000 recorded demonstrations. These demonstrations are captured using two Microsoft Kinect sensors providing synchronized RGB-D data, alongside force/torque sensor readings from a 7-DoF robotic arm. The dataset includes precise robot joint angles, end-effector poses, and object states, all time-aligned and publicly available. Data is structured to facilitate both supervised learning and imitation learning approaches, enabling quantitative evaluation of manipulation performance metrics like success rate, path efficiency, and force minimization. The dataset’s scale and detailed sensor information are critical for training robust and generalizable bimanual manipulation skills in robotic systems.
The robot’s ability to perform complex manipulation tasks is directly enabled through the implementation of learning from demonstration (LfD), a technique where the system acquires skills by observing human execution of those tasks. This approach bypasses the challenges of traditional robotic programming, which requires precise specification of motion parameters. Instead, the robot learns a mapping from observation to action, generalizing from demonstrated examples to novel situations. Reliable performance is achieved through the use of these demonstrations as a supervisory signal, allowing the robot to refine its control policies and minimize errors during execution, ultimately resulting in consistent and successful task completion.
From Prediction to Action: The Art of Bimanual Control
The core of this robotic manipulation system lies in its ability to translate anticipated outcomes into concrete physical actions. Predictions, generated by the framework, don’t simply forecast what the robot needs to do, but directly inform how it will perform complex tasks with both hands. This predictive capability drives an Action Selection process, enabling the bimanual robot to choose the most appropriate sequence of movements to achieve a desired outcome. By proactively determining actions based on anticipated needs, the system avoids reactive adjustments, resulting in smoother, more efficient, and ultimately more successful manipulation of objects – a crucial step toward robots that can seamlessly interact with and adapt to complex real-world environments.
To guarantee safe and effective bimanual robot operation, a critical Precondition Checker operates alongside the action selection process. This component rigorously assesses each proposed movement, verifying that it won’t result in collisions – either with the environment or with the robot’s own limbs – and that the action maintains overall system stability. By proactively identifying and preventing potentially problematic maneuvers, the Precondition Checker ensures reliable execution of complex manipulation tasks. This preventative measure is essential for robots operating in dynamic and unpredictable settings, fostering trust and enabling seamless human-robot collaboration without the risk of damage or instability.
A finetuned model empowers the robotic system to successfully execute manipulation tasks 90% of the time, a key indicator of its ability to translate predictive reasoning into effective physical action. This high success rate isn’t simply about completing tasks, but about reliably bridging the gap between anticipating a necessary movement and actually performing it with precision. The achievement highlights the framework’s robust design, allowing the robot to consistently navigate the complexities of bimanual manipulation and demonstrating a significant step towards more autonomous and adaptable robotic systems capable of intricate real-world applications.
The robotic system demonstrates a remarkable capacity for anticipating hand movements, achieving 99% accuracy in predicting the actions of the left hand and a perfect 100% accuracy for the right hand. This high level of predictive capability is fundamental to the framework’s success, enabling the robot to proactively prepare for and execute complex bimanual manipulations with minimal delay. Such precision suggests the model effectively captures the subtle kinematic relationships and task-specific constraints governing hand movements, paving the way for fluid and coordinated interactions with the environment. The nearly flawless prediction of right-hand actions is particularly notable, indicating a robust understanding of the dominant hand’s role in directing manipulation tasks.
The robotic system demonstrated a remarkable capacity for self-regulation during bimanual manipulation, as evidenced by low intervention rates. Specifically, the framework required corrective intervention for the left hand in only 13.51% of actions and for the right hand in a mere 9.92%. These figures suggest a robust level of inherent stability and control, indicating the system’s ability to proactively maintain task execution without frequent external adjustments. This minimized need for intervention is critical for real-world applications, where continuous human oversight is impractical, and signifies a substantial step towards autonomous, reliable robotic manipulation capabilities.
The convergence of precise anticipation and dependable execution represents a significant leap forward in robotic dexterity. This framework doesn’t merely forecast a robot’s next movements; it translates those predictions into tangible actions with a high degree of safety and stability. Demonstrating a 90% success rate in task completion, alongside remarkably accurate hand-specific predictions – 99% for the left and 100% for the right – the system minimizes intervention while maintaining control, evidenced by low intervention rates of under 14% for either hand. This capability moves beyond simple automation, enabling robots to engage in the complex, coordinated movements necessary for nuanced manipulation tasks and opening doors to applications previously limited by the challenges of bimanual robotic control.
The pursuit of robust robotic systems, as detailed in this work concerning semantic-geometric task graph representations, echoes a fundamental truth about all complex endeavors. Systems, even those built upon intricate graph neural networks and designed for long-horizon manipulation, are subject to the passage of time and the inherent complexities of interaction. As Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This sentiment applies here; the researchers haven’t sought a perfect, all-encompassing model upfront, but rather a system that learns from demonstration and adapts-a pragmatic approach acknowledging that complete foresight is often impossible. The focus on modeling temporal geometric evolution suggests an understanding that graceful aging – or, in this case, robust adaptation – is more valuable than striving for initial perfection. Observing how the system learns from human demonstrations offers insights into the natural unfolding of tasks, potentially surpassing the benefits of accelerating the process with overly rigid pre-programmed solutions.
What Lies Ahead?
The articulation of task structure through semantic-geometric graphs represents a necessary, though not sufficient, condition for robust robotic agency. The current work, while demonstrating an aptitude for encoding demonstrated behavior, skirts the central inevitability: all representations degrade. The true measure of this approach will not be its initial fidelity to human example, but its capacity to gracefully accommodate the inevitable accumulation of error and uncertainty inherent in long-horizon manipulation. Every delay in achieving full autonomy is, in effect, the price of a more enduring understanding.
Future iterations must address the fragility of these learned graphs. A reliance on human demonstrations, however skillfully encoded, creates a system tethered to the limitations of its teachers. More compelling is the prospect of self-correction, of a system capable of refining its internal representation through interaction with a dynamic environment – a system that treats failures not as terminal events, but as opportunities for structural revision.
Architecture without history is, ultimately, ephemeral. The challenge lies not simply in building a more detailed map of the present, but in embedding within it the capacity to remember its own evolution, to trace the lineage of each encoded relation, and to anticipate the consequences of its own actions – a recursive process of learning and adaptation, perpetually unfolding within the medium of time.
Original article: https://arxiv.org/pdf/2601.11460.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- World Eternal Online promo codes and how to use them (September 2025)
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-21 08:17