Author: Denis Avetisyan
A new knowledge distillation framework combines the strengths of different neural network architectures to create more data-efficient and robust visuomotor policies for robotic control.
X-Distill leverages the generalization of Vision Transformers and the data efficiency of Convolutional Neural Networks for improved robot learning in data-scarce environments.
Achieving robust visuomotor control often presents a trade-off between leveraging the powerful generalization of large vision models and the data efficiency required in real-world robotic settings. To address this, we introduce X\text{-}Distill, a novel cross-architecture knowledge distillation framework detailed in ‘X-Distill: Cross-Architecture Vision Distillation for Visuomotor Learning’, which transfers knowledge from a pre-trained Vision Transformer to a compact convolutional network. This approach yields a distilled encoder that consistently outperforms both from-scratch and fine-tuned architectures on diverse manipulation tasks, surpassing even methods utilizing 3D observations or larger vision-language models. Does this simple distillation strategy unlock a pathway toward truly data-efficient and broadly applicable robotic learning systems?
The Limits of Sight: Why Robots Struggle to See the Whole Picture
Convolutional Neural Networks (CNNs) demonstrate remarkable proficiency in identifying localized features within data, a capability stemming from their core design principles – an inherent understanding of spatial proximity and a strong inductive bias towards recognizing patterns that occur nearby. However, this very strength becomes a limitation when analyzing data requiring comprehension of relationships across vast distances. CNNs process information through localized receptive fields, meaning each neuron only considers a small region of the input; while deeper layers can integrate information from larger areas, capturing genuinely long-range dependencies remains computationally expensive and often ineffective. Consequently, tasks demanding a holistic understanding of the entire input – such as identifying subtle global relationships or contextualizing objects within a complex scene – frequently expose the shortcomings of traditional CNN architectures, highlighting the need for models capable of more effectively reasoning about distant elements.
Vision Transformers, while demonstrating a superior capacity for global reasoning within image analysis, face substantial computational hurdles that limit their practical application. The core of this limitation lies in the self-attention mechanism, which, while powerful, exhibits quadratic complexity with respect to image resolution-meaning computational demands increase dramatically as image size grows. This makes scaling ViTs to high-resolution images, or adapting them to scenarios with limited computational resources, exceedingly difficult. Furthermore, training these models typically requires vast datasets to overcome this complexity, hindering their effectiveness in data-scarce environments and demanding significant energy expenditure. Consequently, researchers are actively exploring methods to reduce this computational burden, seeking to retain the benefits of global context understanding without incurring prohibitive costs.
Current limitations in visual recognition systems stem from a fundamental trade-off between computational efficiency and the ability to understand complex imagery. Convolutional Neural Networks, while adept at identifying local features, often falter when discerning relationships across an entire image, hindering performance on tasks demanding broader contextual understanding. Conversely, Vision Transformers demonstrate superior global reasoning but require substantial computational resources, limiting their scalability and adaptability. Recent research therefore focuses on hybrid architectures designed to capitalize on the strengths of both approaches; the goal is to retain the efficiency of CNNs in processing local information while integrating the capacity of ViTs to model long-range dependencies, ultimately achieving a more robust and generalized visual understanding.
Distilling Vision: A Hybrid Approach to Efficient Perception
X-Distill employs a knowledge distillation methodology wherein a pre-trained Vision Transformer, specifically DINOv2, functions as the teacher model. This teacher network imparts its learned representations to a smaller, more efficient CNN, in this case, a ResNet-18, designated as the student. The process involves training the student network to mimic the output and intermediate feature maps of the larger, more complex teacher network, effectively transferring knowledge without requiring the student to learn directly from the original training data. This teacher-student paradigm allows the ResNet-18 to achieve performance levels typically associated with larger models, despite its significantly reduced parameter count.
The X-Distill framework employs Mean Squared Error (MSE) loss as the primary mechanism for knowledge transfer from the teacher network (DINOv2) to the student network (ResNet-18). Specifically, MSE loss calculates the average squared difference between the feature maps produced by both networks for a given input image. Minimizing this difference compels the student network to generate feature representations that closely match those of the pre-trained teacher. This alignment process effectively transfers the teacher’s learned understanding of visual features and their relationships, allowing the smaller student network to achieve comparable performance without requiring training from scratch on a large dataset. The MSE = \frac{1}{n} \sum_{i=1}^{n} (Teacher_i - Student_i)^2 is computed across the feature maps, guiding the student’s weights during backpropagation.
Training the X-Distill student network-a ResNet-18 with 11 million parameters-on the ImageNet dataset yields state-of-the-art performance despite its significantly reduced size compared to other models. Specifically, X-Distill achieves a higher accuracy than ConvNeXt, which contains 89 million parameters, demonstrating efficient knowledge transfer from the DINOv2 teacher network. This parameter efficiency allows for deployment in resource-constrained environments without substantial performance degradation, representing an improvement in model scalability for vision tasks.
Traditional convolutional neural networks (CNNs) excel at capturing local features but can struggle with long-range dependencies, while Vision Transformers (ViTs) effectively model global relationships but often require substantial computational resources and large datasets for training. The X-Distill framework addresses these limitations by combining the strengths of both architectures; it utilizes a pre-trained ViT as a teacher network to impart knowledge regarding global context and feature representation to a smaller, more efficient CNN student network. This hybrid approach mitigates the computational cost associated with ViTs and the limited receptive field of CNNs, resulting in a model that achieves competitive performance on vision tasks with significantly fewer parameters than either architecture operating in isolation.
From Simulation to Steel: Validating X-Distill in Robotic Control
X-Distill was integrated into a Diffusion Policy framework to facilitate visuomotor control for robotic manipulation. This integration allows the robotic system to learn a policy directly from visual inputs to control its actions. The Diffusion Policy provides a probabilistic approach to policy learning, enabling efficient adaptation to new tasks and environments. By leveraging X-Distill’s feature learning capabilities within this framework, the resulting system achieved improved performance in robotic manipulation by directly associating visual observations with appropriate motor commands, eliminating the need for explicitly defined state representations.
Evaluation of the X-Distill integrated Diffusion Policy demonstrated superior performance in both simulated and real-world robotic manipulation tasks. Across 3434 simulated trials, the policy achieved the highest success rate when benchmarked against ResNet-scratch, DINOv2, and π0 (VLA) models. This performance translated to real-world application, with the policy also achieving the highest success rate across 55 physical tasks, consistently outperforming the comparative models in task completion. Quantitative results confirm a statistically significant improvement in success rates using X-Distill, indicating its effectiveness in visuomotor control.
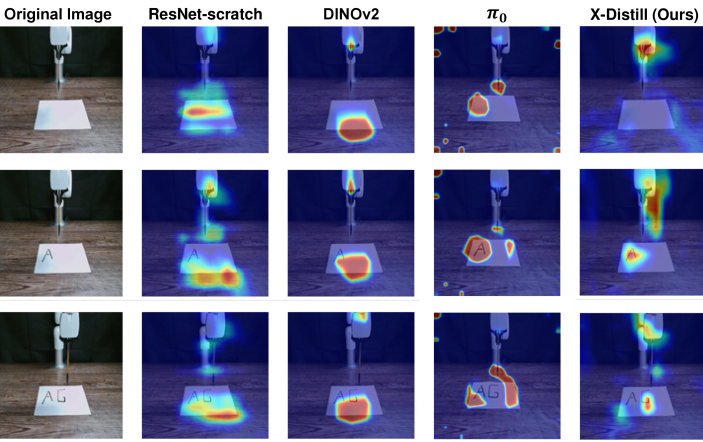
Analysis utilizing Saliency Maps and Grad-CAM techniques confirmed the X-Distill policy’s attentional focus on task-relevant visual features during robotic manipulation. Saliency Maps highlighted regions of the input image that most strongly influenced the policy’s actions, consistently identifying the robotic gripper and target objects. Grad-CAM visualizations further corroborated these findings, demonstrating high activation values within the areas corresponding to key objects and their spatial relationships. These results provide empirical evidence that the learned visual representations effectively capture the necessary information for visuomotor control, indicating successful feature learning and contributing to the policy’s overall performance.
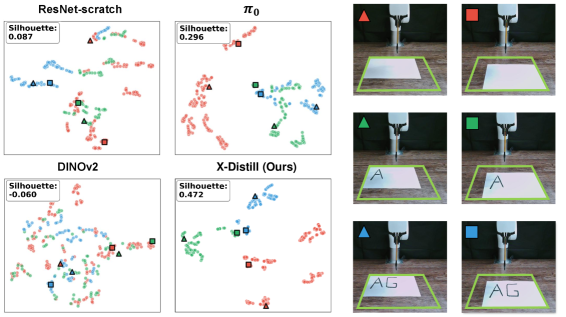
Dimensionality reduction using t-distributed stochastic neighbor embedding (t-SNE) was applied to the learned feature vectors to assess the structure of the latent space. Analysis of the resulting two-dimensional embeddings revealed distinct clusters corresponding to different task variations, indicating a well-structured feature space. This structure supports generalization because similar states across different tasks are mapped to nearby points in the reduced-dimensional space, allowing the policy to transfer knowledge between tasks and effectively handle unseen scenarios. The observed clustering suggests the learned features capture essential task-relevant information in a compressed and organized manner.
Beyond Perception: Towards Adaptable and Efficient Robotic Systems
X-Distill presents a novel approach to robotic control by synergistically combining Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). CNNs excel at capturing local features with computational efficiency, while ViTs demonstrate superior performance in understanding global context – a crucial element for complex manipulation. This method distills the knowledge from a larger, more capable CNN-ViT hybrid model into a significantly smaller network, retaining much of the original performance while drastically reducing computational demands. The resulting system enables robots to perform intricate tasks – such as grasping and assembling objects – with both precision and speed, even on platforms with limited processing power. This advancement paves the way for more adaptable and versatile robotic systems capable of operating in dynamic and unstructured environments.
The deployment of sophisticated robotic systems often encounters limitations imposed by computational resources, particularly when operating in real-world environments. Recent advancements in machine learning have yielded powerful, albeit large, models capable of complex tasks, but these are frequently impractical for robots with restricted processing power or battery life. Knowledge distillation presents a compelling solution by transferring the expertise of these expansive models-often trained on massive datasets-into smaller, more efficient networks. This process doesn’t simply shrink the original model; it carefully guides the learning of the smaller network to mimic the behavior and decision-making processes of its larger counterpart, preserving performance while drastically reducing computational demands. Consequently, previously inaccessible levels of robotic intelligence-such as nuanced object recognition or adaptive grasping-become attainable even on platforms with limited onboard resources, paving the way for more versatile and widespread robotic applications.
The principles underpinning X-Distill extend considerably beyond the realm of robotic control, representing a broadly applicable solution for efficient knowledge transfer within computer vision. This methodology-distilling the expertise of large, complex models into smaller, more manageable architectures-addresses a fundamental challenge across numerous visual processing tasks. Applications range from image classification and object detection on edge devices to real-time video analysis and resource-limited platforms. By prioritizing computational efficiency without substantial performance loss, this framework enables the deployment of sophisticated vision systems in contexts where traditional deep learning models are impractical due to their size and energy demands. Ultimately, the potential for streamlined knowledge transfer promises to accelerate advancements and broaden the accessibility of advanced computer vision technologies across diverse fields.
Ongoing research aims to rigorously test the boundaries of this distillation technique, pushing beyond current limitations in both the complexity of robotic tasks and the breadth of applicable scenarios. Investigations will center on identifying the critical factors that govern successful knowledge transfer, such as the optimal size and architecture of the student model, the diversity of the training data, and the effectiveness of various distillation strategies. Scaling this approach to encompass increasingly intricate manipulations-like fine-grained assembly or dynamic environment navigation-requires addressing challenges related to data acquisition, computational resources, and the robustness of the distilled models. Ultimately, the goal is to establish a reliable and generalizable framework for deploying sophisticated robotic intelligence on a wider range of platforms and in more demanding real-world conditions.
The pursuit of visuomotor policies, as demonstrated by X-Distill, isn’t about achieving perfect replication of reality, but rather about crafting a persuasive illusion. It’s a delicate spell, coaxing a robot to interact with the world through a carefully constructed understanding – a distillation of knowledge from both CNNs and Vision Transformers. As Yann LeCun once stated, “Everything we do in machine learning is about learning representations.” X-Distill doesn’t seek absolute truth; it domesticates chaos by learning effective representations, prioritizing data efficiency in environments where pristine datasets are a fantasy. The framework accepts that data is always whispering uncertainties, and its success hinges on persuading the system to act as if those whispers are clear directives.
What’s Next?
X-Distill offers a pragmatic compromise – a policy that borrows the best tricks from both convolutional and transformer camps. But let’s not mistake expediency for understanding. The architecture itself doesn’t solve the fundamental problem: robots still learn from a world that refuses to hold still for careful observation. The true challenge isn’t squeezing more performance from existing models, but accepting that any policy is merely a temporary truce with chaos.
Future work will undoubtedly explore scaling these distillation methods to even more complex tasks and architectures. However, a more fruitful direction might involve explicitly modeling uncertainty. The current paradigm implicitly assumes a static world; a policy that anticipates its own ignorance – that knows when its predictions are likely to fail – would be a genuine step forward. It’s a long shot, of course; acknowledging limitations rarely leads to funding.
Ultimately, the success of visuomotor learning won’t be measured in benchmark scores, but in a robot’s ability to gracefully recover from the inevitable. A policy that anticipates its own failure is, ironically, more robust than one that believes its own predictions. Perhaps the real distillation isn’t knowledge, but humility.
Original article: https://arxiv.org/pdf/2601.11269.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- World Eternal Online promo codes and how to use them (September 2025)
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-21 00:13