Author: Denis Avetisyan
Effectively grouping high-dimensional data requires a careful balance between simplifying abstractions and preserving meaningful representations, a challenge this review comprehensively addresses.
This paper surveys classical, subspace, and deep learning approaches to clustering high-dimensional data, focusing on the trade-offs between abstraction and representation learning.
Effective clustering of high-dimensional data remains a challenge, requiring a delicate balance between simplifying details and preserving meaningful distinctions. The ‘Clustering High-dimensional Data: Balancing Abstraction and Representation Tutorial at AAAI 2026’ surveys classical and modern approaches to this problem, highlighting the inherent trade-off between abstraction – generalizing away noise – and representation – capturing the essential features that define groups. This tutorial demonstrates how methods ranging from K-means to deep clustering navigate this space, with increasingly expressive representations demanding stronger regularization to ensure genuine clustering rather than simply feature learning. Given the human brain’s remarkable ability to achieve this balance effortlessly, can future algorithms adaptively learn the optimal level of abstraction and representation to unlock even more powerful and interpretable clustering solutions?
The Curse of Dimensionality: Why Clusters Disappear
The escalating complexity of high-dimensional data poses a fundamental obstacle for clustering algorithms, a phenomenon known as the ‘Curse of Dimensionality’. As the number of features or dimensions increases, the data becomes increasingly sparse, meaning data points are further apart from one another. This increased separation diminishes the effectiveness of distance-based algorithms like K-Means, which rely on measuring the proximity of data points to assign them to clusters. Consequently, the concept of ‘distance’ itself becomes less meaningful and less discriminatory in high dimensions, making it difficult to identify genuinely cohesive groups. The algorithm struggles to differentiate between meaningful patterns and random noise, leading to the creation of diffuse, poorly defined clusters or an inability to discern any clusters at all. Essentially, the data space expands so rapidly that the density of data points decreases, hindering the algorithm’s capacity to accurately group similar instances together.
Initial clustering attempts in high-dimensional data spaces frequently encounter difficulties due to data sparsity. As the number of dimensions increases, data points become increasingly isolated, diminishing the effectiveness of distance-based algorithms like K-Means. This phenomenon results in poorly defined clusters and unreliable outcomes; a baseline Normalized Mutual Information (NMI) score of just 0.28 demonstrates the limited ability of K-Means to discern meaningful patterns in such environments. The low NMI indicates that the clusters identified by the algorithm bear little resemblance to the true underlying data structure, highlighting the necessity for more sophisticated techniques capable of handling the challenges posed by high dimensionality and sparse data distributions.
Assessing the effectiveness of clustering in high-dimensional spaces necessitates the use of quantitative metrics, and Normalized Mutual Information (NMI) serves as a crucial indicator of cluster quality. NMI evaluates the shared information between the predicted clusters and the true class labels, offering a standardized score between zero and one – higher values denote greater similarity. Initial investigations utilizing NMI revealed a baseline performance of only 0.28 with the K-Means algorithm, underscoring the difficulty these early methods face when confronted with the sparsity inherent in high-dimensional data. This comparatively low score doesn’t simply indicate a technical failing; it emphasizes the critical need for more sophisticated clustering techniques and robust evaluation methodologies capable of discerning meaningful patterns amidst the ‘curse of dimensionality’, as simpler approaches often fail to capture the underlying structure of the data.

Cutting Through the Noise: Dimensionality Reduction as a First Step
Dimensionality reduction techniques, including Principal Component Analysis (PCA), mitigate the issues arising from high-dimensional datasets by creating a lower-dimensional representation of the data while retaining essential variance. High dimensionality can lead to the “curse of dimensionality,” increasing computational cost, storage requirements, and the risk of overfitting in machine learning models. These techniques operate by transforming the original feature space into a new space with fewer dimensions, typically through linear projections or non-linear mappings. The selection of appropriate techniques and the number of dimensions to retain depend on the specific dataset and the downstream task, often determined through variance explained thresholds or cross-validation procedures. By reducing dimensionality, these methods improve model efficiency, reduce noise, and facilitate data visualization.
Subspace clustering addresses the limitations of traditional clustering algorithms when applied to high-dimensional data by recognizing that meaningful clusters may only exist within specific subsets, or subspaces, of the total feature space. This approach is predicated on the observation that not all features are relevant for distinguishing clusters; irrelevant or noisy features can obscure the underlying structure. Algorithms designed for subspace clustering identify these relevant subspaces and perform clustering operations within them, rather than on the entire high-dimensional feature space. This targeted approach improves cluster quality and reduces computational complexity by focusing analysis on the most informative dimensions of the data, enabling the discovery of clusters that would otherwise be obscured by the ‘curse of dimensionality’.
Application of K-Means clustering to the reduced-dimensionality latent space generated by an autoencoder resulted in a Normalized Mutual Information (NMI) score of 0.56. This outcome indicates a measurable, though moderate, performance gain compared to the initial clustering baseline. The NMI score provides a quantitative assessment of the similarity between the clusters derived from the reduced data and the ground truth labels, suggesting that while dimensionality reduction facilitates clustering, the improvement is not substantial and further optimization may be necessary to achieve higher accuracy.
Abstraction, in the context of data analysis, builds upon dimensionality reduction by not simply reducing the number of features, but by actively selecting those features – or combinations of features – that contribute most significantly to the underlying structure and meaning within the data. This process involves identifying and prioritizing information based on its relevance to the specific analytical goal, effectively filtering out noise or redundant data. Unlike purely mathematical transformations like Principal Component Analysis which aim to maximize variance explained, abstraction often incorporates domain knowledge or task-specific criteria to determine feature importance, resulting in a more interpretable and focused representation of the data. This selective focus allows for improved model performance, reduced computational cost, and enhanced understanding of the data’s essential characteristics.
Deep Learning to the Rescue: Learning Representations for Better Clusters
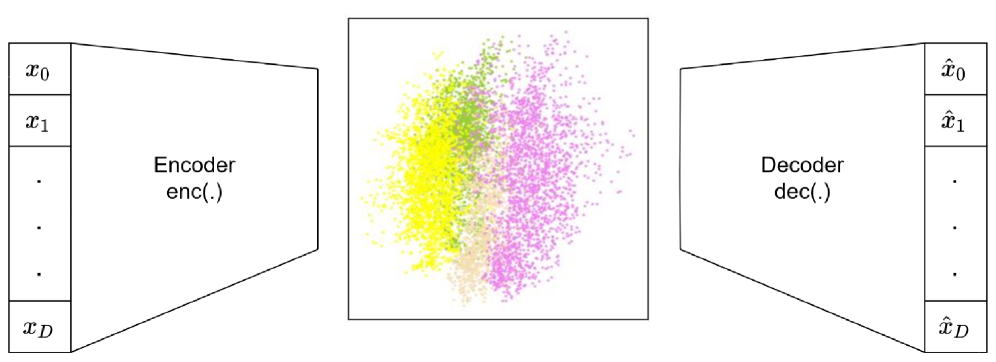
Deep Clustering utilizes deep neural networks, notably Autoencoders, to transform raw data into a more informative representation suitable for clustering algorithms. This process, known as representation learning, aims to capture the essential features of the data while reducing dimensionality and removing noise. Autoencoders achieve this by learning a compressed, latent-space representation of the input data, forcing the network to identify and retain the most salient characteristics. By clustering within this learned representation space, algorithms can often achieve superior performance compared to traditional methods that operate directly on the original, high-dimensional data. The effectiveness of this approach stems from the network’s ability to learn non-linear features and complex relationships within the data that may be missed by linear dimensionality reduction techniques.
Contrastive Representation Learning enhances data representations by explicitly training models to differentiate between data points. This is achieved by minimizing the distance between similar instances and maximizing the distance between dissimilar ones within the learned embedding space. A prominent example of this approach is the Contrastive Clustering (CC) method, which employs a contrastive loss function during training. This loss encourages the network to produce embeddings where data points belonging to the same cluster are close together, while those from different clusters are pushed further apart, resulting in more discriminative features for subsequent clustering analysis.
Evaluations of deep clustering methods demonstrate quantifiable improvements in performance metrics. Specifically, the Deep Embedded Clustering (DEC) algorithm achieved a Normalized Mutual Information (NMI) score of 0.58, while its improved variant, Information-Maximizing Deep Embedded Clustering (IDEC), reached an NMI of 0.60. These NMI values, obtained through benchmark datasets, indicate that deep learning-based approaches are progressively enhancing clustering accuracy compared to traditional methods, as evidenced by the increasing scores achieved with iterative refinements like the transition from DEC to IDEC.
Deep learning-derived representations facilitate performance gains in clustering by transforming raw data into a feature space where distance metrics more accurately reflect inherent data relationships. Traditional clustering algorithms, such as k-means or DBSCAN, operate on these learned representations rather than the original data, leading to improved separation between clusters and more precise identification of cluster boundaries. This approach mitigates the challenges posed by high-dimensional data and non-linear relationships, where traditional distance calculations can be less effective. Consequently, algorithms utilizing these representations consistently demonstrate higher accuracy, as measured by metrics like Normalized Mutual Information (NMI), compared to methods operating directly on the original feature space.
Beyond the Basics: Advanced Deep Clustering Techniques Emerge
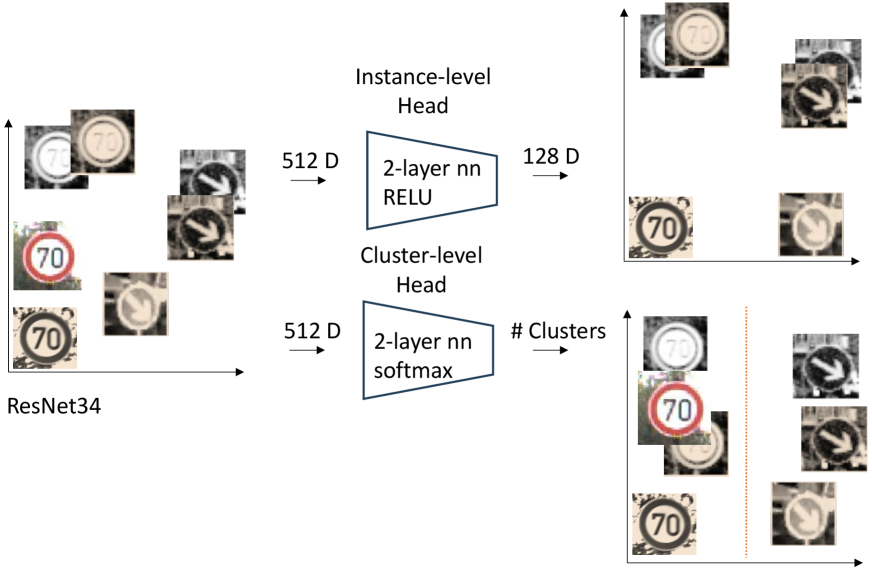
Centroid-based deep clustering techniques, including Deep Embedded Clustering (DEC) and Improved Deep Embedded Clustering (IDEC), function by optimizing an objective function that minimizes the distance between data points and their assigned cluster centroids within an embedding space. These methods typically employ an autoencoder to learn a lower-dimensional representation of the data, followed by a clustering layer that assigns instances to clusters. The objective function incorporates terms that both encourage cluster compactness – bringing instances closer to their centroid – and inter-cluster separation, maximizing the distance between centroids. This optimization process directly shapes the embedding space to facilitate clearer distinctions between clusters, resulting in improved clustering performance compared to traditional methods that operate directly on the original feature space.
Hierarchical Deep Clustering methods, such as DeepECT, construct a dendrogram – a tree-like representation of the data’s hierarchical relationships – enabling analysis at varying levels of detail. This approach contrasts with flat clustering methods by iteratively merging or splitting clusters, creating a multi-level structure that allows for exploration of cluster granularity. The resulting tree balances the need for abstract, high-level groupings with detailed, fine-grained representations of the data, offering a flexible framework for identifying clusters appropriate to a given analytical task. This hierarchical structure facilitates both broad overview and detailed examination of data relationships.
The DeepECT method achieved a Normalized Mutual Information (NMI) score of 0.80 when evaluated on the German Traffic Sign Benchmark dataset. This NMI value represents a significant improvement over previously published results on this dataset, establishing DeepECT as a state-of-the-art approach for traffic sign recognition and classification within the context of deep clustering. The German Traffic Sign Benchmark is a standardized dataset used for evaluating the performance of algorithms designed to recognize and categorize various traffic signs, and an NMI of 0.80 indicates a high degree of agreement between the cluster assignments produced by DeepECT and the ground truth labels.
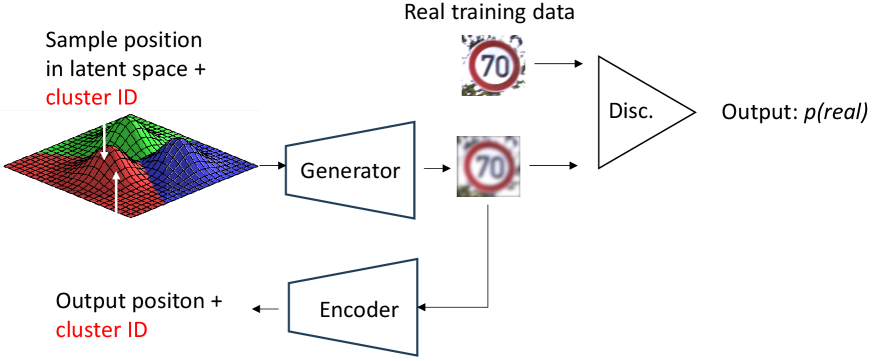
Generative approaches to deep clustering, prominently featuring ClusterGAN and VaDE, leverage Generative Adversarial Networks (GANs) to simultaneously learn data representations and cluster assignments. These methods typically employ a generator network to create synthetic data points, and a discriminator network to distinguish between real and generated data. The clustering objective is integrated into the GAN training process, often through the discriminator, encouraging the generator to produce data that conforms to cluster structures. This framework is particularly beneficial for complex datasets where traditional methods struggle due to non-convex cluster boundaries or high dimensionality, as the GAN’s generative capability allows for learning more robust and disentangled representations suitable for accurate clustering.

The Future of Clustering: Intelligent Analysis and Beyond
Modern clustering algorithms are experiencing a renaissance fueled by the synergistic combination of three powerful techniques. Dimensionality reduction, such as Principal Component Analysis, first simplifies complex datasets by reducing the number of variables while preserving essential information. This streamlined data then benefits from representation learning, where algorithms automatically discover useful features, effectively transforming raw data into a more meaningful format. Finally, advanced deep clustering techniques, leveraging the power of neural networks, exploit these learned representations to identify inherent groupings within the data with greater accuracy and efficiency than traditional methods. This progression allows for the discovery of subtle patterns and relationships, enabling more precise categorization and insightful analysis across a broad spectrum of applications, from identifying fraudulent transactions to personalizing customer experiences.
The recent surge in clustering algorithm performance is directly translating into tangible progress across diverse fields. In image recognition, these advancements allow for more nuanced and accurate categorization of visual data, moving beyond simple object identification to understanding complex scenes and relationships. Anomaly detection benefits from the ability to identify subtle deviations from established patterns, proving crucial in fraud prevention, network security, and predictive maintenance. Simultaneously, customer segmentation is becoming increasingly sophisticated, enabling businesses to move beyond basic demographics and create highly targeted marketing campaigns based on granular behavioral patterns and preferences. This expanding capability to derive meaningful insights from complex datasets promises to reshape how organizations approach problem-solving and decision-making in the years to come.
The trajectory of deep clustering research is firmly set on enhancing both the reliability and capacity of current methodologies. Future innovations will likely prioritize algorithms capable of handling increasingly complex, high-dimensional datasets without succumbing to instability or computational bottlenecks. A key area of exploration involves incorporating domain-specific expertise directly into the clustering framework – moving beyond purely data-driven approaches. This integration could take the form of specialized loss functions, informed initialization strategies, or the use of prior knowledge to guide feature learning, ultimately leading to more meaningful and actionable cluster assignments. Such advancements promise to unlock the full potential of deep clustering across diverse fields, from personalized medicine to advanced materials discovery.
The pursuit of elegant solutions for high-dimensional clustering invariably reveals the limitations of any purely theoretical framework. This tutorial, meticulously charting the evolution from classical methods to deep learning approaches, demonstrates how each advancement introduces new compromises. It’s a familiar pattern; abstraction, while simplifying complexity, inevitably loses fidelity to the underlying representation. As John von Neumann observed, “There is no such thing as a completely accurate model; models are necessarily approximations.” The paper’s survey of subspace and deep clustering techniques isn’t about finding the ‘best’ method, but about understanding where each model’s abstractions fail-and how those failures manifest in production. Everything optimized will one day be optimized back, and this work is a pragmatic acknowledgment of that cycle.
What’s Next?
The relentless pursuit of elegant clustering solutions for high-dimensional data invariably circles back to a rather unpleasant truth: production data rarely respects theoretical boundaries. These methods, increasingly reliant on learned representations and autoencoders, seem poised to trade explicit dimensionality reduction for opaque, black-box transformations. They’ll call it AI and raise funding, naturally. But someone, inevitably, will be debugging a failed cluster because the embedding space subtly shifted after a model update. It always does.
The tension between abstraction and representation isn’t merely a technical challenge; it’s an admission that ‘meaningful’ structure is often subjective, or worse, a convenient fiction. The field will likely see a surge in ‘explainable clustering’ techniques, desperately attempting to retrofit interpretability onto systems that were never designed for it. Expect more papers on ‘robustness to adversarial perturbations’ – which is just a fancy way of saying ‘we need to prevent real-world noise from breaking our pretty math.’
One can’t help but recall that most of these complex pipelines began as a simple bash script and a handful of distance metrics. The drive toward ever-more-sophisticated methods risks obscuring the fundamental goal: to find patterns. Perhaps the next breakthrough won’t be a novel algorithm, but a better understanding of when ‘good enough’ is, in fact, good enough. Tech debt is just emotional debt with commits, after all.
Original article: https://arxiv.org/pdf/2601.11160.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- World Eternal Online promo codes and how to use them (September 2025)
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-20 22:32