Author: Denis Avetisyan
Researchers have developed a new approach to controlling quadrupedal robots, enabling stable and fast locomotion even with substantial weight.

An analytical actuator model improves sim-to-real transfer for reinforcement learning-based locomotion control in heavy hydraulic robots exceeding 300kg.
Achieving robust sim-to-real transfer remains a significant challenge for large-scale hydraulic robots due to their slow dynamics and complex fluid behavior. This work, ‘Learning Quadrupedal Locomotion for a Heavy Hydraulic Robot Using an Actuator Model’, addresses this limitation by introducing an analytical actuator model that accurately predicts joint torques-in under 1 microsecond-allowing for rapid iteration within reinforcement learning environments. We demonstrate that this model outperforms neural network alternatives, particularly in data-limited scenarios, and successfully enables stable, 1m/s locomotion on a 300kg+ hydraulic quadruped-a first for this scale of robot. Could this approach unlock more agile and adaptable hydraulic systems for a wider range of robotic applications?
The Challenge of Dynamic Locomotion: A Matter of Precision
Conventional control strategies frequently falter when applied to quadrupedal locomotion, especially as the terrain becomes more challenging. These methods, often designed for static or predictable environments, struggle to account for the inherent complexities of coordinating multiple limbs across uneven surfaces. The dynamic interplay between leg movements, ground reaction forces, and the robot’s center of mass creates a high-dimensional control problem that exceeds the capabilities of many traditional approaches. Consequently, robots relying on these systems often exhibit instability, jerky movements, or an inability to adapt to unexpected obstacles, hindering their effectiveness in real-world scenarios requiring robust and agile navigation.
Effective quadrupedal locomotion isn’t simply about telling legs where to move, but acknowledging how they move and the forces resisting those movements. Actuators – the motors driving leg joints – don’t respond linearly; applying a small command doesn’t necessarily result in a proportional change in position, introducing delays and complexities. Simultaneously, robots operating in the real world encounter unpredictable disturbances – uneven ground, slippery surfaces, or even accidental nudges – that instantly disrupt planned motions. Consequently, sophisticated control algorithms must model these nonlinearities and incorporate robust estimation of external forces to anticipate and counteract disturbances, allowing the robot to maintain balance and adapt its gait in real-time. This necessitates moving beyond simplified models and embracing dynamic systems identification techniques to accurately capture the intricate interplay between the robot’s internal dynamics and the external environment.
Current strategies for controlling quadrupedal robots frequently employ simplified models of the robot’s mechanics and the surrounding environment, a practice that, while computationally efficient, ultimately restricts real-world performance. These models often linearize complex dynamics or assume ideal conditions – such as perfectly flat ground and predictable contact forces – which deviate significantly from the irregularities encountered in natural settings. Consequently, robots relying on these approximations struggle with disturbances, exhibit reduced agility, and demonstrate limited robustness when faced with uneven terrain or unexpected impacts. The simplification trades accuracy for speed, creating a performance bottleneck that hinders the deployment of these robots in dynamic and unpredictable environments, and necessitating the development of more sophisticated control algorithms capable of accommodating nonlinearities and uncertainties.

Reinforcement Learning: A Principled Approach to Agile Control
Traditional locomotion control relies on creating a dynamic model of the robot and its environment, a process that is often time-consuming and susceptible to inaccuracies due to model simplification or unmodeled dynamics. Instead, this work utilizes Reinforcement Learning (RL) to train a locomotion controller directly from raw sensor data, such as joint angles, velocities, and ground contact forces. This approach circumvents the need for explicit dynamic modeling; the controller learns to map sensor inputs to appropriate motor commands through interaction with the environment and a defined reward function. By directly learning from data, the controller can implicitly capture complex dynamic behaviors without requiring a pre-defined mathematical representation of the system.
The RL-based locomotion controller utilizes a trial-and-error process to discover gait patterns that maximize forward progression and stability. This is achieved through iterative interactions with the simulated or physical environment, where the controller receives reward signals based on its performance. The system’s ability to adapt to changing conditions and disturbances stems from its continuous learning; as external factors such as terrain or payload shift, the controller modifies its actions to maintain optimal locomotion. This adaptation is not pre-programmed but emerges from the agent’s exploration of the state and action space, allowing it to generalize to previously unseen scenarios and recover from unexpected perturbations.
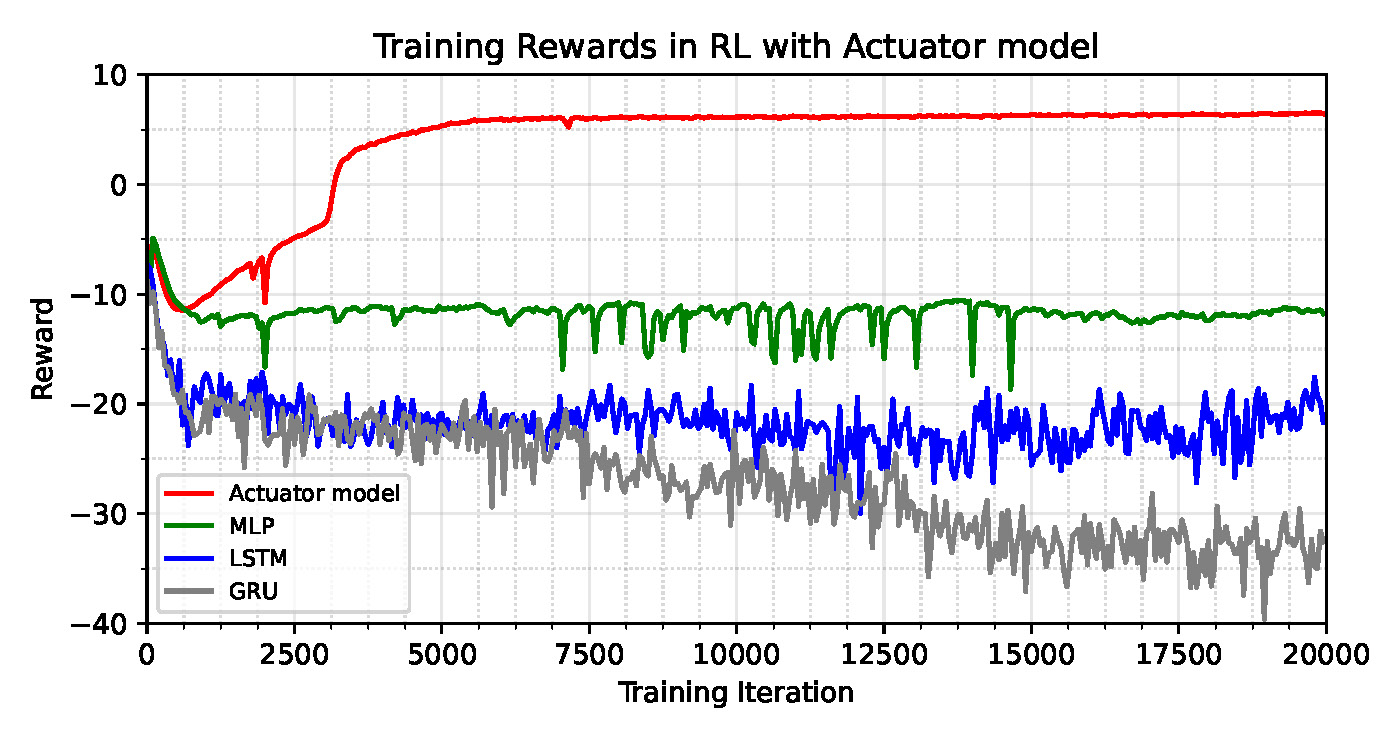
The performance of the locomotion controller is directly dependent on its ability to accurately model the behavior of the hydraulic actuators. Our reinforcement learning-based training process demonstrated a substantial reduction in training time for this actuator modeling, achieving full performance within 10 hours. This represents a significant improvement over baseline models, which typically require 36 to 48 hours to reach the same level of accuracy in understanding and predicting hydraulic actuator response. This accelerated training is critical for rapid prototyping and deployment of agile control systems.
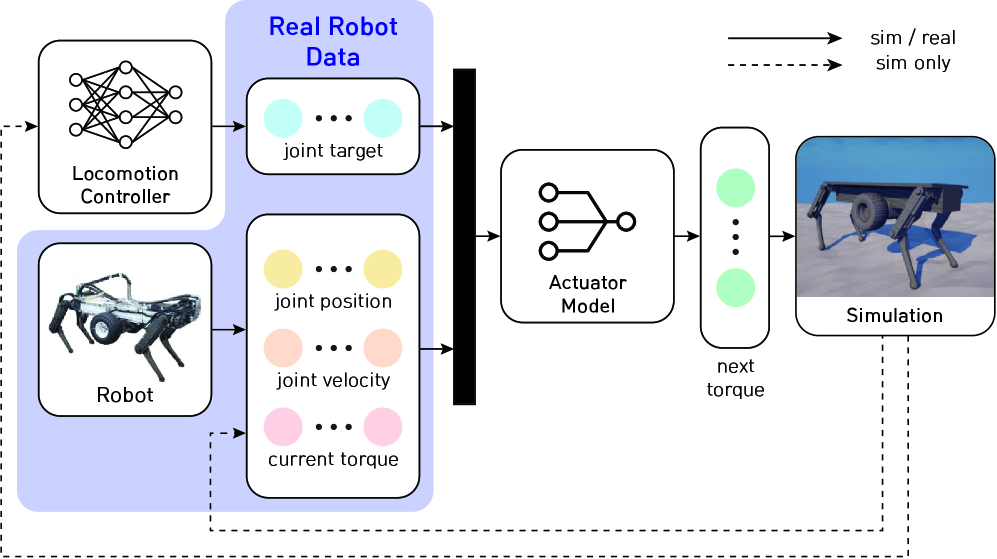
Bridging the Reality Gap: Actuator Modeling with Fidelity
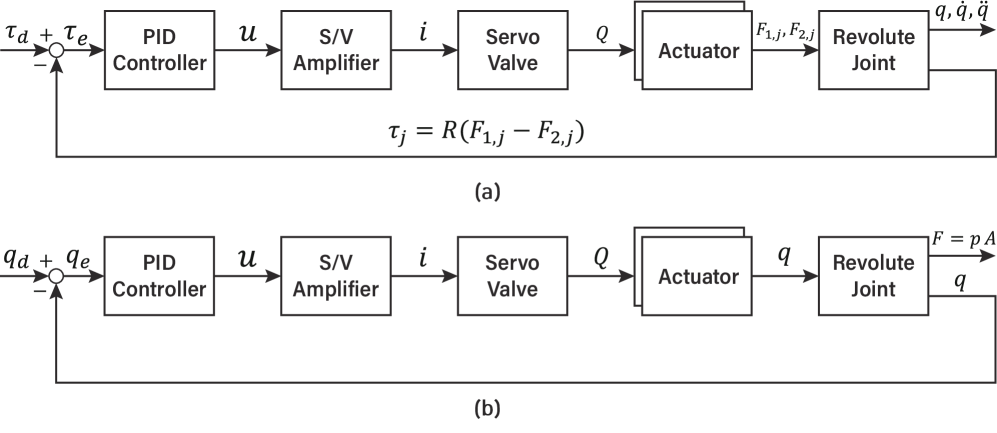
Accurate hydraulic actuator modeling is fundamental to both robot control performance and the efficacy of simulation-to-reality (Sim-to-Real) transfer. Discrepancies between the simulated actuator behavior and its physical counterpart introduce errors in the control policy learned in simulation when deployed on the real robot. These errors manifest as inaccuracies in position, velocity, and force control, ultimately limiting the robot’s ability to perform tasks reliably. Consequently, minimizing the fidelity gap between the simulation and the real-world actuator is a primary requirement for successful Sim-to-Real workflows, necessitating models that capture the non-linearities, time delays, and other dynamic characteristics inherent in hydraulic systems.
Two distinct approaches were utilized to model actuator behavior: an Analytical Actuator Model and a Neural Network Actuator Model. The Analytical Actuator Model, based on first principles and physical parameters, provides a computationally efficient representation of actuator dynamics, though its accuracy is limited by simplifying assumptions. Conversely, the Neural Network Actuator Model, specifically a feedforward network, learns a mapping from actuator inputs to outputs directly from data, allowing it to capture complex, non-linear behaviors not readily represented in the analytical model. This data-driven approach necessitates a substantial training dataset but offers the potential for higher fidelity representation of the actuator’s response.
A hybrid modeling approach was implemented, utilizing an analytical actuator model for initial policy training followed by refinement with a data-driven neural network model. This combined strategy demonstrably improved simulation fidelity and subsequent policy transfer to the physical robot. Quantitative evaluation revealed that our actuator model significantly outperformed multilayer perceptron (MLP), long short-term memory (LSTM), and gated recurrent unit (GRU) baselines in torque prediction accuracy, as measured by both Root Mean Squared Error (RMS) and Maximum Absolute Percentage Error (MAP).
Enhancing Performance: State Estimation and Curricular Progression
A robust control system for a dynamic robot relies heavily on accurate state awareness, and this is achieved through the implementation of an observer, or state estimator. This component continuously processes sensor data – including joint angles, velocities, and forces – to infer the robot’s complete state, even those aspects not directly measured. By providing real-time feedback on position, velocity, and orientation, the observer enables the control system to react swiftly and precisely to disturbances or changes in the environment. This constant refinement of state knowledge is crucial for maintaining stability and responsiveness, particularly in complex movements where even small errors can compound over time. The observer effectively bridges the gap between imperfect sensor readings and the ideal state required for accurate control, ultimately enhancing the robot’s ability to execute desired motions with fidelity and robustness.
Precise control of a robot’s movements hinges on accurate actuator management, and this is achieved through the implementation of both Torque and Position Proportional-Integral-Derivative (PID) control systems. Position PID control ensures the robot’s limbs reach desired spatial coordinates with minimal error by continuously adjusting motor positions based on the difference between the target and actual positions. Complementing this, Torque PID control regulates the forces exerted by each actuator, preventing oscillations and enabling the robot to maintain stable contact with the environment. By working in tandem, these PID controllers deliver responsive and accurate force regulation, crucial for dynamic locomotion and interaction with complex terrains; this dual-control strategy allows for both precise positioning and the application of controlled forces, ultimately contributing to the robot’s ability to perform intricate movements and maintain balance even under challenging conditions.
The development of robust locomotion in heavy, complex robots benefits significantly from a technique called Curriculum Learning. This approach mirrors how humans learn – starting with simple tasks and gradually increasing difficulty. Initially, the reinforcement learning agent is trained on easily achievable motions and terrains. As proficiency grows, the simulation introduces more challenging scenarios – uneven ground, steeper inclines, and faster speeds. This progressive training allows the agent to build upon previously learned skills, preventing it from being overwhelmed by complex tasks early in the learning process. Ultimately, this methodology enabled stable locomotion at 1 meter per second for a robot exceeding 300 kilograms, demonstrating its effectiveness in mastering intricate gaits and navigating demanding environments.
The pursuit of robust locomotion, as demonstrated in this work with heavy hydraulic robots, echoes a sentiment articulated by Ada Lovelace: “The Analytical Engine has no pretensions whatever to originate anything.” This isn’t a limitation, but a fundamental truth; the robot, like the Engine, operates according to defined rules – in this case, an analytical actuator model. The success of sim-to-real transfer hinges on the fidelity of this model, ensuring the virtual world accurately reflects the physical constraints. Just as Lovelace recognized the Engine’s capacity for complex calculations based on given instructions, this research demonstrates how a precise understanding of hydraulic dynamics allows a quadruped to achieve stable, 1m/s locomotion, proving the power of rigorous, mathematically grounded approaches to robotic control.
Future Directions
The demonstrated improvement in sim-to-real transfer, while a pragmatic advance, merely addresses a symptom. The fundamental discordance remains: current reinforcement learning paradigms often prioritize empirical success over analytical rigor. The actuator model, however carefully constructed, is still an approximation of a profoundly complex physical system. Future work must move beyond simply matching observed behavior and instead focus on provably stable control algorithms – solutions derived from first principles, not iterative refinement.
A truly elegant solution will not require extensive domain randomization or system identification. Instead, it will leverage the inherent predictability of physical laws. The emphasis should shift from data-hungry learning to knowledge-infused control. The current reliance on trial-and-error, while yielding functional results, obscures the underlying mathematical truths governing dynamic locomotion. A reduction in reliance on purely empirical methods is paramount.
Moreover, the scalability of this approach requires further investigation. Extending these techniques to robots of differing mass, actuator configurations, and operating environments will undoubtedly reveal limitations. The ultimate test lies not in achieving locomotion at 1m/s, but in demonstrating robustness and adaptability across a broad spectrum of conditions – a feat demanding a deeper understanding of the underlying mathematical structure of the problem.
Original article: https://arxiv.org/pdf/2601.11143.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- World Eternal Online promo codes and how to use them (September 2025)
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- M7 Pass Event Guide: All you need to know
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-20 18:52