Author: Denis Avetisyan
Researchers have developed a novel framework that leverages skill-level information to dramatically improve a robot’s ability to generalize manipulation tasks and transfer learned skills from simulation to the real world.
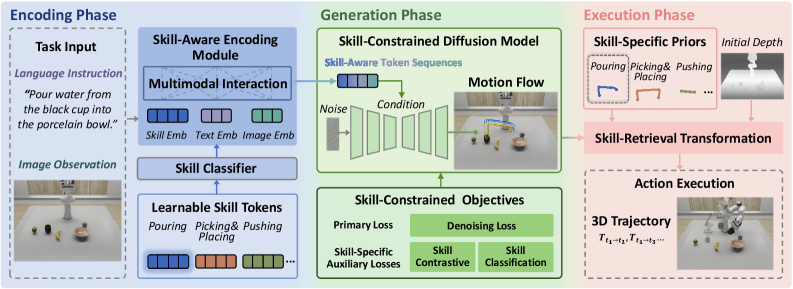
Skill-Aware Diffusion models enhance robotic manipulation by explicitly incorporating skill representations into the diffusion process, improving both generalization and sim-to-real transfer.
Achieving robust generalization in robotic manipulation remains a key challenge, often hindered by approaches that treat tasks in isolation. This paper introduces Skill-Aware Diffusion for Generalizable Robotic Manipulation, a novel framework leveraging diffusion models and explicitly incorporating skill-level information to address this limitation. By learning skill-specific representations and conditioning a diffusion model on these skills, SADiff generates object-centric motion flow and refines it with learned trajectory priors. Could this skill-aware approach unlock more adaptable and broadly capable robotic systems for real-world deployment?
The Challenge of Generalization: A Systemic Bottleneck
Conventional imitation learning, while conceptually straightforward, frequently demands a substantial volume of meticulously curated, task-specific data for successful robot training. This reliance presents a considerable obstacle to practical deployment, as acquiring such datasets is often time-consuming, expensive, and impractical in many real-world scenarios. The need for exhaustive examples limits the robot’s ability to adapt to novel situations or even slight variations in its environment; a robot trained to grasp a red block, for instance, may struggle with a blue one. This data dependency hinders the development of truly adaptable robotic systems capable of operating reliably outside of controlled laboratory settings and restricts their application in dynamic, unpredictable environments where data collection is difficult or impossible.
The pursuit of truly autonomous robots is fundamentally hampered by the difficulty of skill transfer – the ability to apply learned behaviors to novel situations and environments. Current robotic systems often excel within carefully controlled settings, but falter when confronted with even slight deviations from their training data. This limitation arises because robots typically learn specific instantiations of a task, rather than underlying principles; a robot trained to grasp a red block on a blue surface may struggle with a blue block on a red surface. Consequently, achieving robust robotic autonomy demands breakthroughs in techniques that enable robots to generalize beyond their initial experiences, adapting previously acquired skills to a wide range of unforeseen circumstances and tasks without requiring extensive retraining or human intervention. This bottleneck restricts deployment in real-world scenarios characterized by dynamism and unpredictability, and represents a core challenge in the field of robotic learning.
A persistent challenge in robotic learning lies in the limited ability of current methodologies to generalize beyond the specific conditions under which they were trained. Robots frequently struggle when confronted with even slight deviations from familiar scenarios – a change in lighting, the introduction of a new object, or a minor alteration in task parameters can necessitate complete retraining. This brittleness stems from an over-reliance on memorizing specific instances rather than developing a robust understanding of underlying principles. Consequently, deploying robots in real-world environments – characterized by inherent variability and unpredictability – remains a significant hurdle, demanding constant human intervention and limiting the potential for truly autonomous operation. The need to repeatedly retrain robots for minor adjustments represents a substantial limitation in both efficiency and scalability, hindering widespread adoption across diverse applications.
The inability of robots to readily adapt to changing circumstances significantly curtails their practical application beyond highly structured environments. A robot proficient in one specific setting – a factory assembly line, for instance – often falters when confronted with even slight deviations, such as altered lighting, unexpected obstacles, or novel object arrangements. This fragility stems from a reliance on precisely the conditions under which it was trained, and the difficulty in extrapolating learned behaviors to the complexities of the real world. Consequently, widespread deployment in unpredictable locales – from bustling city streets and disaster zones to domestic homes and agricultural fields – remains a considerable challenge, demanding substantial advances in robust, adaptable robotic systems capable of functioning reliably amidst constant change.
Enhancing Perception: Building a Robust Visual Foundation
Visual Representations Enhancement for robotic systems utilizes large-scale pre-training on extensive image datasets to develop more effective visual encoders. This pre-training process initializes the encoder with learned features transferable to robotic tasks, reducing the need for task-specific data. Auxiliary objectives, incorporated during training, further refine the encoder’s ability to extract meaningful information from visual input. These objectives can include tasks like predicting image rotations, colorizing grayscale images, or solving jigsaw puzzles, forcing the encoder to learn robust and generalizable visual features beyond simple object recognition. The resulting visual encoders demonstrate improved performance in downstream robotic applications due to their enhanced ability to handle variations in lighting, viewpoint, and object appearance.
Time-Contrastive Learning (TCL) addresses limitations in traditional contrastive learning by focusing on temporal relationships within visual data. Unlike methods that treat individual frames as independent samples, TCL explicitly models the consistency and change occurring across sequential frames. This is achieved by constructing positive pairs from different points in time within the same scene and negative pairs from unrelated scenes or distant time steps. By learning to discriminate between these temporally-related and unrelated visual states, robotic systems can develop a more sensitive understanding of subtle cues – such as object deformation, motion patterns, or lighting changes – which are critical for accurate perception and effective action planning in dynamic environments. The resulting visual encoders demonstrate improved robustness to noise and variations in viewpoint, enabling robots to generalize better to unseen scenarios.
Interaction prediction enhances robotic visual understanding by moving beyond static scene interpretation to model the dynamic relationships between objects and their potential future states. This is achieved by training systems to anticipate how physical interactions – such as pushing, grasping, or colliding – will alter the environment. By learning to predict these interactions, robots can infer unobserved properties of objects, such as friction or weight, and proactively plan actions based on anticipated outcomes. Models utilize historical data of object interactions to establish predictive capabilities, allowing for more accurate state estimation and improved performance in complex, dynamic scenarios. This predictive capability is crucial for tasks requiring foresight, such as manipulation, navigation, and human-robot collaboration.
Enhanced visual understanding, achieved through techniques like large-scale pre-training and time-contrastive learning, directly impacts a robot’s perceptual capabilities. By extracting richer information from visual input – including nuanced patterns and predicted interaction states – robots move beyond simple object recognition to develop a more complete environmental model. This allows for improved performance in tasks requiring contextual awareness and anticipatory behavior, enabling more effective navigation, manipulation, and interaction with dynamic surroundings. The increased fidelity of visual perception reduces reliance on pre-programmed responses and facilitates adaptation to previously unseen scenarios.

Generating Skillful Motion: Diffusion Models as a Pathway to Adaptability
Diffusion models generate motion by reversing a diffusion process that gradually adds noise to training data until it becomes pure noise. This forward process creates a Markov chain, allowing for analytical computation of the reverse process – the generation of motion. Starting with random noise, the model iteratively denoises this data, predicting and removing a small amount of noise at each step. This iterative refinement, guided by a learned neural network, gradually transforms the noise into a realistic and coherent motion sequence. The quality of the generated motion is dependent on the model’s ability to accurately estimate and subtract the noise at each denoising step, effectively learning the underlying data distribution of observed motions.
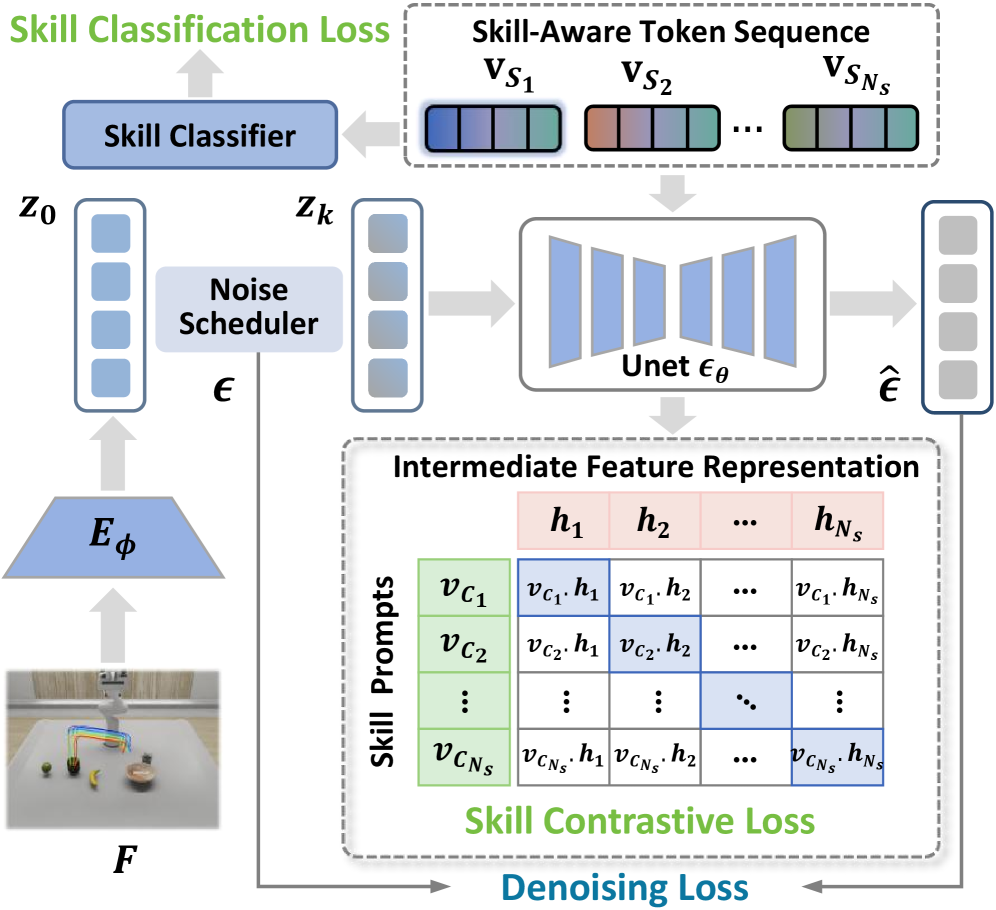
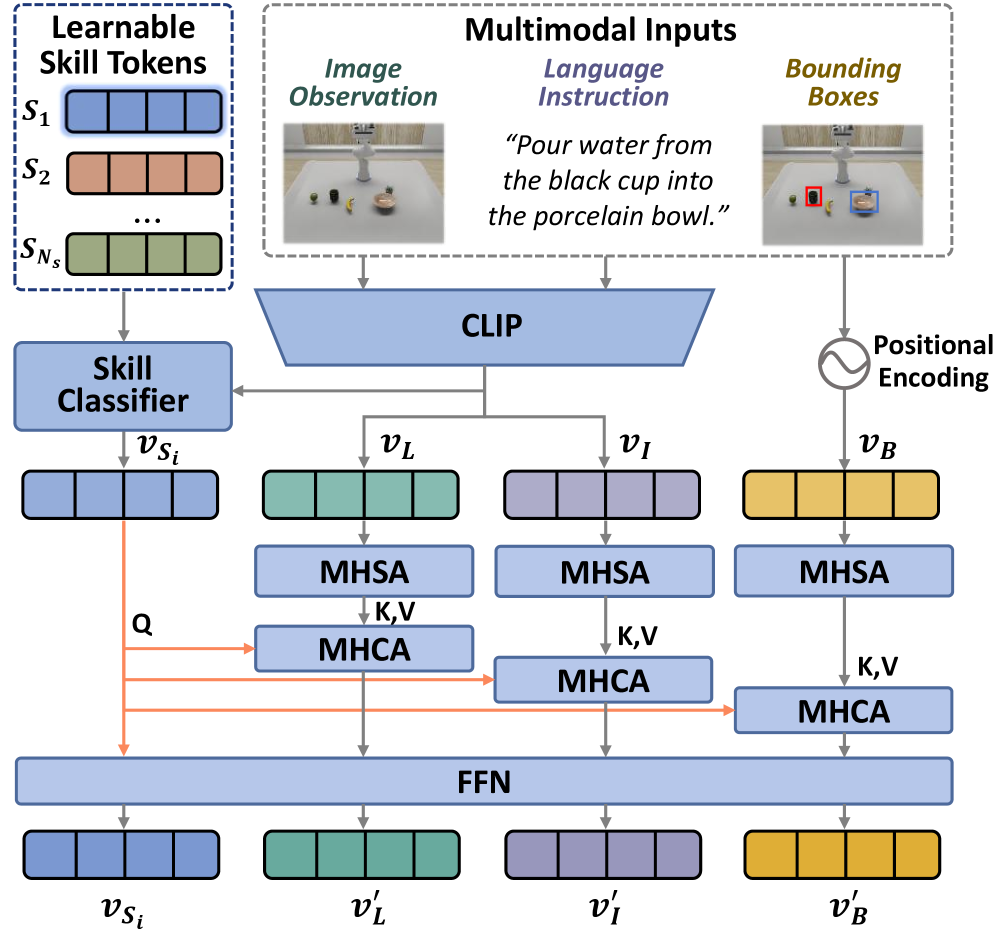
The Skill-Constrained Diffusion Model enhances motion generation by incorporating skill-aware token sequences as conditional inputs during the iterative denoising process. These token sequences, representing semantic skill embeddings, function as a guiding signal, directing the diffusion model to produce motions relevant to a specific task. By conditioning the generation on these discrete skill representations, the model moves beyond purely stochastic motion synthesis and instead prioritizes outputs that align with desired behaviors. This conditioning is implemented by feeding the skill tokens into the U-Net architecture alongside the noisy motion data, influencing the predicted noise and ultimately shaping the generated trajectory.
Skill Classification Loss and Skill Contrastive Loss function as key regularization terms within the diffusion model training process. Skill Classification Loss enforces accurate categorization of generated motion sequences into predefined skill classes, minimizing the cross-entropy between predicted and ground-truth skill labels. Simultaneously, Skill Contrastive Loss maximizes the similarity between the semantic embedding of a generated motion and the embedding of its corresponding skill token, while minimizing similarity to embeddings of other, unrelated skills. These losses operate on the latent representation produced by a skill encoder, effectively guiding the diffusion process to produce motions that are both semantically meaningful and demonstrably aligned with specific skill representations, improving the quality and relevance of generated trajectories.
The implementation of skill-constrained diffusion models enables robotic motion generation across a spectrum of tasks and environments due to the conditioning of the diffusion process on learned skill representations. By associating motions with semantic skill tokens, the model can synthesize trajectories that are not only realistic but also relevant to a specified objective. This adaptability is achieved by training the model on a dataset of diverse motions, allowing it to generalize to novel scenarios and variations in environmental conditions. The resulting system produces motions that are demonstrably skillful, exhibiting appropriate kinematic properties and achieving the desired task outcomes, even when faced with previously unseen circumstances.
Validation and Dataset Contribution: Establishing a Robust Benchmark
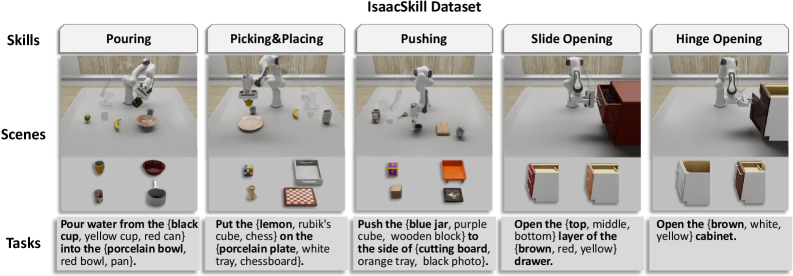
The IsaacSkill dataset is a high-fidelity simulation environment designed for the evaluation of robotic manipulation skills. It utilizes the Franka Emika Panda robot arm, a widely adopted platform in robotics research, and incorporates RGB-D camera data to provide realistic visual input. This combination allows for the development and testing of algorithms focused on skill acquisition and generalization, providing a standardized benchmark for comparing different approaches to robotic manipulation. The dataset’s fidelity, stemming from accurate physics simulation and sensor modeling, facilitates the training of policies in simulation and their subsequent transfer to real-world robotic systems.
TAPIR Tracker is a key component in generating the IsaacSkill dataset, providing precise 6D pose estimation of objects throughout each robotic manipulation sequence. This tracking system utilizes a combination of deep learning-based object detection and Kalman filtering to maintain consistent object identification and trajectory reconstruction, even under conditions of partial occlusion or rapid motion. The resulting data includes time-stamped positional and rotational information for each object, which is critical for calculating key performance indicators like trajectory accuracy, manipulation speed, and success rate. Data from TAPIR Tracker enables detailed motion analysis and serves as ground truth for training and evaluating robotic learning algorithms within the IsaacSkill environment.
Qwen-VL, a vision-language model, plays a critical role in enabling the robotic framework to interpret both visual input and natural language instructions. Specifically, Qwen-VL is utilized for identifying and locating objects within the robot’s workspace based on textual cues provided in the task instruction. This localization capability is fundamental to complex task execution, as it allows the robot to accurately target and manipulate the specified objects. The model processes RGB-D camera data to perceive the environment and correlates this visual information with the semantic meaning of the instruction, effectively bridging the gap between high-level goals and low-level robotic actions.
Real-world zero-shot sim-to-real transfer experiments demonstrate the proposed framework achieves a 76.0% success rate in task completion. This performance represents a significant improvement over existing methods, exceeding the success rate of Im2Flow2Act by 21.6 percentage points and Track2Act by 25.6 percentage points under identical testing conditions. These results indicate the framework’s enhanced ability to generalize learned policies from simulation to previously unseen real-world environments without requiring any further adaptation or fine-tuning in the target domain.
The proposed framework demonstrates high performance in simulated robotic manipulation tasks, achieving a 92.8% success rate when tested on data within the original distribution. Notably, the framework also exhibits strong generalization capabilities, attaining an 89.6% success rate in background generalization scenarios – where the environment differs from the training data – and 82.4% in cross-category generalization, involving novel object categories. These results represent the highest reported success rates for both background and cross-category generalization when compared to existing methods, indicating improved robustness and adaptability to unseen conditions in simulation.
Skill-Aware Encoding: Paving the Way for Versatile Robotic Agents
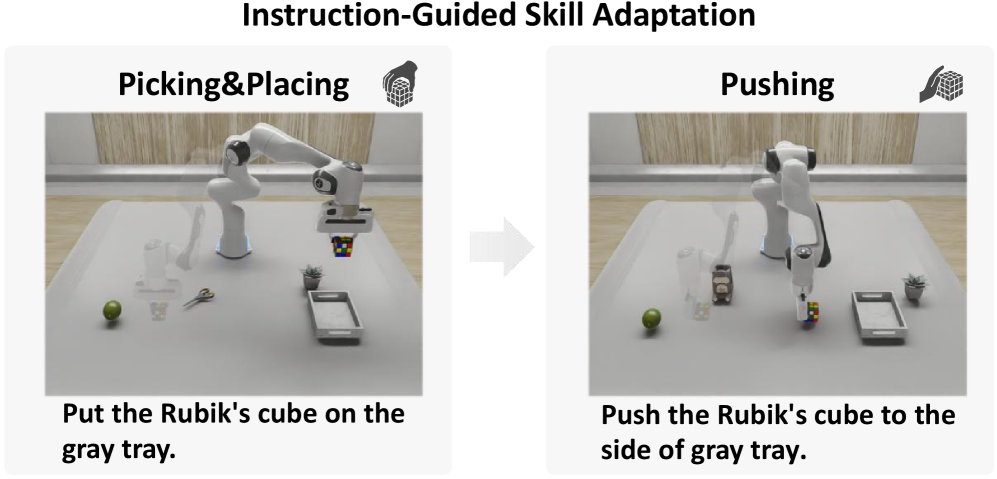
The system employs a Skill-Aware Encoding Module designed to distill task-relevant information from diverse sensory inputs. This module leverages learnable skill tokens – essentially, trainable parameters that represent specific skills – to capture nuances within multimodal data, such as visual observations and proprioceptive feedback. During interaction with an environment, these tokens are dynamically adjusted to encode skill-specific knowledge, allowing the robotic agent to effectively interpret its surroundings in the context of the task at hand. This process enables the system to differentiate between, for example, grasping a delicate object versus a robust one, even with similar visual input, by activating distinct skill tokens and subsequently modulating its actions.
The system’s capacity for rapid task switching and environmental adaptation stems from a unique representation of skills as discrete, adjustable parameters. Instead of rigidly programming responses for each scenario, the robotic agent learns to encode skills – such as grasping, pushing, or navigating – as independent variables within its operational framework. This allows the agent to dynamically combine and modify these skill parameters based on the demands of a new task or the characteristics of an unfamiliar environment. Consequently, the agent avoids the need for extensive retraining when faced with novel situations; it can effectively ‘mix and match’ existing skills to achieve desired outcomes, demonstrating a level of flexibility previously unattainable in robotic systems and offering a pathway toward genuinely versatile and autonomous operation.
The architecture deliberately prioritizes modularity, enabling components representing specific skills to be readily reused across diverse robotic tasks and environments. This isn’t simply about code sharing; the system learns to represent skills as independent parameters, allowing for flexible combination and adaptation. Consequently, a robotic agent equipped with this approach doesn’t need to relearn fundamental abilities – such as grasping or navigating – when presented with a new challenge. Instead, it can leverage existing skill modules, combine them in novel ways, and quickly generalize to unseen scenarios, ultimately fostering the development of truly versatile and adaptable robotic systems capable of operating effectively in complex and dynamic real-world settings.
The progression of skill-aware robotic encoding necessitates exploration beyond current benchmarks, with upcoming studies designed to address the challenges of significantly more complex tasks requiring intricate coordination and long-term planning. Researchers are actively investigating methods to integrate this approach into physical robotic platforms, moving beyond simulation to confront the unpredictable nuances of real-world environments – including variations in lighting, surface textures, and unexpected obstacles. This integration demands robust perception systems and adaptable control algorithms to ensure reliable performance and safe operation, ultimately aiming to create robotic agents capable of seamless task switching and generalized skill application across diverse scenarios and unforeseen circumstances.
The research detailed in this paper underscores a fundamental principle of systemic design – that structure dictates behavior. SADiff’s approach to robotic manipulation, by explicitly modeling skill-level information, acknowledges the interconnectedness of components within a complex system. This resonates with Donald Davies’ observation, “A system’s architecture is its destiny.” The framework doesn’t simply address manipulation as isolated actions; it emphasizes the flow of motion and skill transfer, creating a cohesive and generalizable system. Just as a flawed architectural blueprint compromises an entire structure, neglecting skill-level awareness hinders effective robotic performance and sim-to-real transfer. SADiff’s contribution lies in meticulously crafting that blueprint for robotic action.
Beyond the Reach of the Hand
The pursuit of generalizable robotic manipulation often fixates on the fidelity of motion-the precise trajectory of end-effectors. Yet, this work suggests a deeper constraint: the coherence of intent. SADiff’s emphasis on skill-level information isn’t merely a technical refinement, but a recognition that behavior emerges from underlying structure. A system cannot convincingly ‘grasp’ without first ‘understanding’ the purpose of the grasp. Scaling this, however, demands more than larger datasets or more powerful models. It requires a shift toward representing not just how things are done, but why.
The challenge now lies in composing these ‘skill primitives’ into more complex behaviors. Current approaches tend to treat skills as discrete units, but true adaptability necessitates a fluid, compositional system-one where skills blend and morph in response to unforeseen circumstances. The ecosystem of robotic action must be robust to perturbation, not through brute-force resilience, but through elegant, hierarchical design.
Sim-to-real transfer, predictably, remains a persistent bottleneck. While SADiff offers a promising bridge, the fundamental disconnect between simulated and embodied experience cannot be fully resolved by algorithmic ingenuity alone. The true test will be whether this framework can facilitate a robot’s capacity to learn-not just to mimic-in the messy, unpredictable reality it inhabits.
Original article: https://arxiv.org/pdf/2601.11266.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- M7 Pass Event Guide: All you need to know
2026-01-20 08:56