Author: Denis Avetisyan
Researchers have developed novel reward models to help artificial intelligence better assess the quality of scientific writing, moving beyond simple metrics to evaluate reasoning and adaptability.

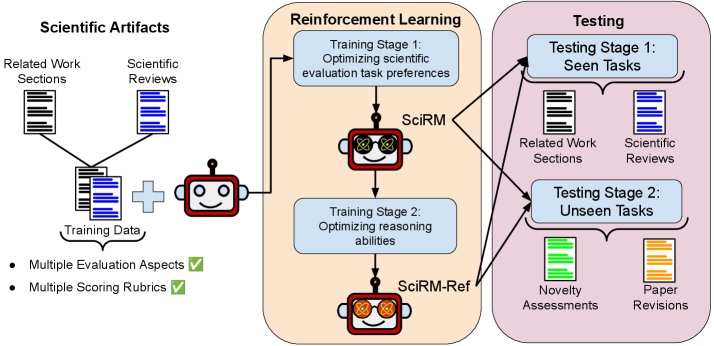
SciRM and SciRM-Ref utilize a two-stage reinforcement learning process to improve the evaluation of scientific text generated by large language models.
Evaluating scientific writing presents a unique challenge due to its domain-specific knowledge and multifaceted criteria, yet current large language model-based judges often fall short in accurately assessing complex reasoning. This limitation motivates the work ‘Reward Modeling for Scientific Writing Evaluation’, which introduces a cost-efficient, open-source reward modeling framework-SciRM-designed to enhance LLMs’ ability to evaluate scientific texts. Through a novel two-stage reinforcement learning process, SciRM improves reasoning and generalization across diverse evaluation tasks without requiring task-specific retraining. Could this approach unlock more reliable and scalable automated assessment of scientific communication, ultimately accelerating the pace of discovery?
The Challenge of Scientific Validation
The longstanding practice of peer review, while foundational to scientific validation, inherently grapples with subjectivity; differing reviewer biases and interpretations can lead to inconsistent evaluations of the same work. Beyond this qualitative challenge lies a significant issue of scalability – the sheer volume of scientific literature produced annually far outstrips the capacity of the expert community to provide thorough, timely assessments for every manuscript. This bottleneck not only delays the dissemination of potentially groundbreaking research but also creates a situation where the quality of evaluation can vary dramatically depending on the field, the journal, and even the availability of qualified reviewers. Consequently, the current system, reliant on manual expertise, struggles to keep pace with the exponential growth of scientific knowledge and faces inherent limitations in ensuring consistently rigorous and efficient evaluation of scientific writing.
Current large language models, while proficient at identifying surface-level errors in scientific writing, demonstrate significant limitations when tasked with evaluating the validity of complex reasoning or nuanced domain-specific knowledge. These models often struggle to discern subtle flaws in experimental design, interpret the significance of statistical analyses, or recognize the implications of findings within a specialized field. Consequently, assessments generated by LLMs can be unreliable, potentially overlooking critical weaknesses in research or, conversely, misidentifying legitimate approaches as flawed. This inability to perform truly critical evaluation poses a challenge to the use of LLMs as objective judges of scientific work, hindering their potential to improve the rigor and efficiency of scientific communication.
The absence of robust evaluation methods within scientific writing poses a significant impediment to the advancement of knowledge. When flawed research escapes critical assessment, it can propagate inaccuracies, misdirect future investigations, and ultimately slow the pace of discovery. This is particularly concerning given the increasing volume of published research; a reliance on subjective peer review, or the limitations of current artificial intelligence, creates bottlenecks that delay the identification and correction of errors. Consequently, potentially transformative insights may remain obscured, and resources can be wasted pursuing unproductive avenues, hindering progress across all scientific disciplines. The long-term effects of this evaluation gap extend beyond individual studies, potentially eroding public trust in scientific findings and impeding evidence-based decision-making.
Introducing SciRM: A Framework for Rigorous Assessment
SciRM is a reward modeling technique developed to assess scientific writing based on explicitly defined parameters. The model is trained using datasets comprised of scientific text evaluated against predetermined Evaluation Criteria, which specify desired qualities such as clarity, accuracy, and logical structure. This training process enables SciRM to learn a reward function that correlates with human assessments of scientific writing quality. The resulting model can then be used to automatically score and provide feedback on new scientific content, offering a quantifiable measure of adherence to specified standards and characteristics. The system’s efficacy is directly linked to the comprehensiveness and relevance of the initial training data and the precision of the defined criteria.
SciRM’s training is performed in two distinct stages to optimize performance. The initial stage focuses on preference learning, where the model is trained on paired comparisons of scientific texts to identify and prioritize desired qualities as determined by human feedback. This stage establishes a foundational understanding of effective scientific writing. Subsequently, the model undergoes a robust reasoning phase, employing techniques to evaluate the logical coherence, factual accuracy, and methodological soundness of the text. This second stage enhances the model’s ability to provide assessments beyond surface-level features, ensuring it can reliably identify and reward scientifically rigorous content.
SciRM employs algorithms such as Guided Reinforcement Policy Optimization (GRPO) to iteratively refine the reward signals generated during evaluation. GRPO facilitates this refinement by allowing the model to learn from its own assessments, adjusting the weighting of different evaluation criteria based on observed outcomes. This process enhances the model’s ability to provide assessments that are not only consistent with the defined Scoring Rubric, but also demonstrably aligned with desired qualities in scientific writing. By optimizing the reward function through GRPO, SciRM minimizes spurious correlations and focuses on features genuinely indicative of strong scientific communication, thereby improving the meaningfulness and reliability of its evaluations.
SciRM’s adaptability is achieved through modular input of domain-specific requirements, specifically Evaluation Criteria and a corresponding Scoring Rubric. These inputs define the qualities assessed in scientific writing – such as clarity, novelty, methodology rigor, and statistical validity – and assign weighted values to each. The Scoring Rubric details the performance levels for each criterion, providing a granular scale for evaluation. This allows SciRM to be customized for various scientific disciplines and assessment goals without requiring retraining of the core model; instead, the evaluation parameters are adjusted to reflect the particular standards of a given field or publication venue.
Refining SciRM: LoRA and the Power of SciRM-Ref
LoRA (Low-Rank Adaptation) is implemented to optimize SciRM by reducing the number of trainable parameters during fine-tuning. This is achieved by freezing the pre-trained model weights and introducing trainable low-rank matrices that approximate weight updates. By focusing adaptation on these smaller matrices, LoRA significantly lowers computational costs and memory requirements compared to full fine-tuning, enabling efficient adaptation to specific scientific reasoning tasks without substantial resource demands. Experimental results demonstrate that LoRA maintains, and in some cases improves upon, the performance of full fine-tuning while drastically reducing the number of parameters requiring gradient updates.
The Unsloth framework automates the optimization of Low-Rank Adaptation (LoRA) parameters during fine-tuning of SciRM. This automation includes techniques such as automatic rank selection and the implementation of pruning strategies to identify and remove less impactful LoRA weights. By automating these processes, Unsloth reduces the need for manual hyperparameter tuning, significantly decreasing the computational resources and time required to achieve optimal performance with LoRA. This streamlined process enables faster experimentation and more efficient development of SciRM models.
SciRM-Ref represents an advancement over the initial SciRM model through the implementation of a two-stage training process. This secondary training phase is specifically designed to bolster the model’s capabilities in both scientific reasoning and self-verification. The initial SciRM model is first refined, and then subjected to further training using a dedicated dataset and methodology focused on enhancing its ability to not only process scientific information, but also to critically evaluate and confirm the validity of its own conclusions. Empirical results demonstrate a significant performance increase in complex reasoning tasks and a measurable improvement in the accuracy of self-verified responses when compared to the original SciRM model.
SciRM-Ref incorporates a `Task Query` mechanism to direct model attention during scientific text processing. This query is a specifically formatted instruction provided as input, defining the precise task the model should perform on the given scientific writing. By explicitly outlining the desired outcome – such as identifying key findings, evaluating experimental methodology, or summarizing specific data – the `Task Query` ensures the model prioritizes relevant information and minimizes extraneous processing. This targeted approach improves both the accuracy and efficiency of SciRM-Ref in complex scientific reasoning and self-verification tasks, as it reduces ambiguity and focuses computational resources on the most pertinent aspects of the input text.
The Impact of Automated Evaluation: Reviews and Related Work
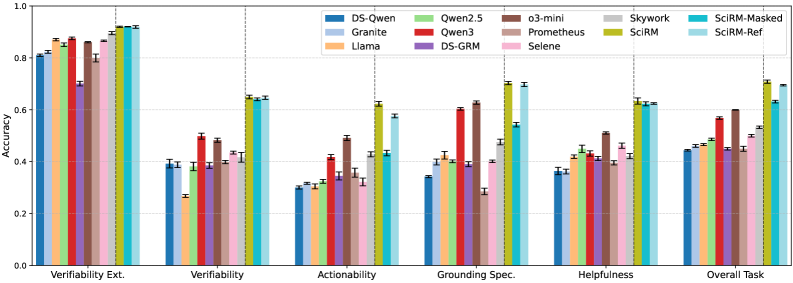
Scientific reviews are cornerstones of research, yet assessing their true utility remains a complex challenge. Recent advancements demonstrate that models like SciRM and SciRM-Ref excel at this very task, going beyond simple sentiment analysis to evaluate the helpfulness and overall quality of scholarly reviews. These models don’t merely identify positive or negative phrasing; instead, they discern whether a review provides constructive feedback, accurately summarizes the work, and offers insightful critiques. By focusing on aspects like clarity, comprehensiveness, and the validity of arguments presented within the review, SciRM and SciRM-Ref offer a nuanced evaluation, potentially automating a crucial component of the peer-review process and ensuring that valuable research receives the rigorous assessment it deserves. This capability holds significant promise for improving the efficiency and reliability of scientific discourse.
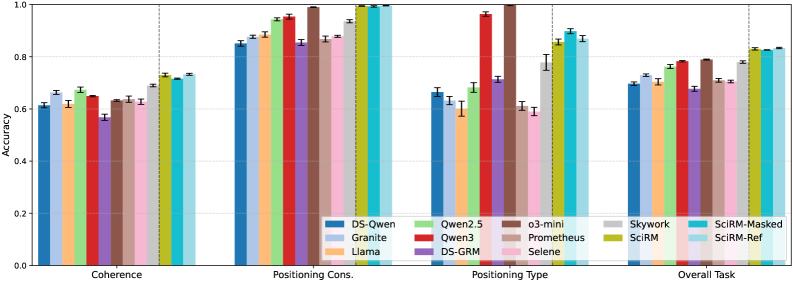
Scientific literature relies heavily on the effective integration of prior research, and accurately assessing this ‘related work’ is crucial for validating new findings. Recent models demonstrate a notable capacity to evaluate these citations, not simply for their presence, but for the quality of their integration. These systems judge whether cited papers are genuinely relevant to the presented arguments, whether the discussion of those works is coherent and logically sound, and, critically, whether the cited literature is positioned appropriately within the broader scientific context. This goes beyond simple keyword matching; the models discern whether a paper is used to support a claim, contrast with existing knowledge, or build upon previous findings, offering a nuanced evaluation of how effectively a study engages with the existing body of knowledge.
A robust evaluation of scientific literature hinges on assessing not just what is claimed, but how those claims are substantiated and presented. Central to this process are metrics of verifiability and coherence. Verifiability demands that assertions are demonstrably supported by evidence – whether through direct citations, experimental data, or established theory – acting as a safeguard against unsubstantiated statements. Equally crucial is coherence, which gauges the logical flow and interconnectedness of arguments; a coherent study presents ideas in a clear, understandable sequence, building upon previous points to reach well-reasoned conclusions. These metrics, when applied systematically, offer a rigorous means of determining the overall quality and reliability of scientific research, ensuring that published work is both well-supported and logically sound.
Evaluations demonstrate that SciRM exhibits a remarkable capacity for assessing scientific literature, achieving near-perfect accuracy in determining ‘Positioning Consistency’ – verifying that cited works are logically integrated within a research context. Furthermore, the model consistently surpassed baseline performance with greater than 90% accuracy across multiple facets of ‘Review Utility Evaluation’, indicating its effectiveness in gauging the helpfulness and quality of scientific reviews. Notably, SciRM-Ref, an enhanced iteration of the model, achieved the highest average score across all four evaluation tasks, suggesting an overall superior ability to comprehensively assess both the relevance of related work and the utility of existing reviews.
Future Directions: Towards Automated Scientific Discourse
The convergence of SciRM and SciRM-Ref with efficient serving frameworks like vLLM unlocks the potential for automated response generation during scientific writing evaluation. This integration moves beyond simple scoring metrics by enabling the system to proactively produce alternative phrasing or arguments, creating a comparative landscape for assessment. By automatically generating candidate responses, the evaluation process becomes more dynamic, allowing for a nuanced understanding of an article’s strengths and weaknesses – not just whether it meets predefined criteria, but how it could be improved. This capability facilitates a deeper analysis of scientific discourse, effectively simulating aspects of peer review and paving the way for more comprehensive and insightful automated evaluations.
Traditional evaluations of scientific writing often rely on simplistic scoring metrics, which fail to capture the complexities of impactful communication. However, integrating frameworks like SciRM and SciRM-Ref with tools such as vLLM facilitates a shift towards more holistic assessments. This automated system doesn’t merely assign a number; it generates candidate responses and evaluates writing based on a range of criteria, including novelty, clarity, and logical coherence. By moving beyond simple scoring, researchers gain access to nuanced feedback that highlights specific strengths and weaknesses, enabling more targeted revisions and ultimately improving the quality and impact of scientific discourse. This approach promises a richer understanding of a manuscript’s contribution and its potential to advance knowledge within its field.
Continued development centers on refining the scope of assessment within these automated systems. Current evaluations primarily address aspects like relevance and novelty, but future iterations aim to incorporate a broader spectrum of criteria – including methodological rigor, statistical validity, and the clarity of argumentation. Crucially, adaptation to the nuances of diverse scientific fields is also a priority; a model trained on biomedical literature may not perform optimally when applied to astrophysics papers, necessitating discipline-specific fine-tuning and the incorporation of domain-specific knowledge. This targeted expansion promises to yield evaluation tools that are not only comprehensive but also sensitive to the unique standards and expectations of each scientific community, ultimately enhancing the reliability and utility of automated scientific discourse analysis.
Recent advancements in automated scientific evaluation have yielded promising results, notably with the SciRM-Ref model. This system demonstrated performance remarkably close to that of o3-mini, a traditionally closed-source model, in assessing novelty alignment – a crucial aspect of scientific rigor. This near-parity signifies a substantial leap forward in the field, indicating that open-source models are rapidly approaching the capabilities previously held exclusively by proprietary systems. Such progress paves the way for more accessible and scalable tools capable of objectively evaluating the originality and contribution of scientific work, ultimately streamlining the research process and fostering innovation.
The advent of automated scientific discourse evaluation, driven by models like SciRM and SciRM-Ref, suggests a fundamental shift in how research is vetted and validated. Currently, peer review, while crucial, is a bottleneck susceptible to human biases and logistical constraints. This technology proposes to augment, not replace, human reviewers, by providing a preliminary, objective assessment of submissions, flagging potential issues, and prioritizing novel contributions. By automating aspects of the evaluation process, researchers could receive feedback more quickly, accelerating the pace of discovery. Furthermore, a transparent, algorithm-driven evaluation offers the potential to minimize subjective biases and enhance the overall reliability of scientific findings, fostering greater trust in the published literature and ultimately reshaping the landscape of scholarly communication.
The pursuit of effective reward modeling, as demonstrated by SciRM and SciRM-Ref, inherently demands a stripping away of superfluous complexity. This research focuses on refining LLM evaluation – not by adding layers of intricate metrics, but by bolstering their fundamental reasoning abilities through a focused, two-stage reinforcement learning process. This echoes Marvin Minsky’s sentiment: “The more you understand, the more you realize how little you know.” The authors don’t attempt to create a perfect, all-encompassing evaluation system; instead, they iteratively refine the model’s capacity to discern quality, acknowledging the inherent limitations and striving for clarity in judgment. It’s a testament to the power of subtraction as a means of achieving deeper understanding in scientific text generation and evaluation.
The Road Ahead
The pursuit of automated scientific writing evaluation, as exemplified by SciRM and SciRM-Ref, reveals less a problem of model inadequacy and more a problem of definition. The core challenge isn’t simply teaching a machine to score prose, but to precisely articulate what constitutes ‘good’ scientific writing. The current work, while demonstrably improving upon existing methods, merely refines the approximation. It does not resolve the fundamental subjectivity inherent in evaluating complex reasoning and nuanced argumentation.
Future iterations will likely focus on minimizing the distance between human judgment and machine assessment. However, the true advance will not come from incremental improvements in reinforcement learning, but from a more rigorous and formalized understanding of the qualities that distinguish impactful scientific communication. A shift from feature engineering to principle extraction-identifying the axiomatic properties of effective scientific prose-may prove more fruitful.
The lingering question is not whether machines can mimic scientific evaluation, but whether they can reveal biases and inconsistencies within the process itself. Perhaps the greatest contribution of this line of inquiry will not be a perfected scoring system, but a clearer reflection of the standards by which science is, and should be, judged. The elegance, ultimately, lies in what is discarded, not accumulated.
Original article: https://arxiv.org/pdf/2601.11374.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- M7 Pass Event Guide: All you need to know
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-19 22:53