Author: Denis Avetisyan
Researchers have developed a novel framework that enables vision-language models to improve their reasoning abilities through self-play, bypassing the need for human-labeled training data.
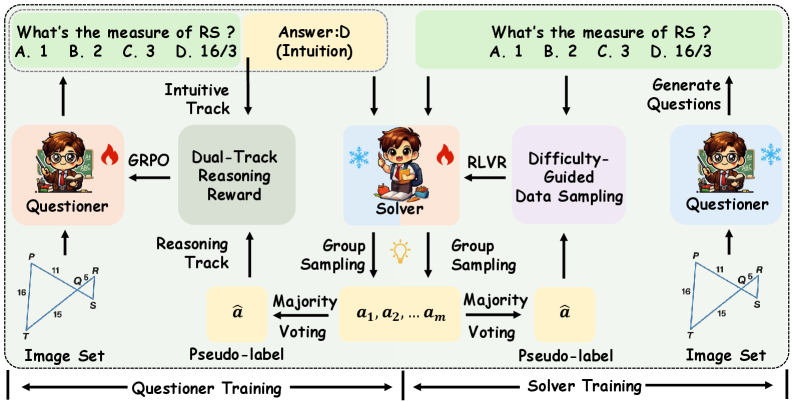
V-Zero leverages a co-evolutionary learning process between a Questioner and Solver to achieve self-improvement in multimodal reasoning tasks.
Despite recent advances in multimodal reasoning, vision-language models remain heavily reliant on costly and time-consuming human-annotated datasets. This limitation motivates the work presented in ‘V-Zero: Self-Improving Multimodal Reasoning with Zero Annotation’, which introduces a novel post-training framework enabling self-improvement using exclusively unlabeled images. By establishing a co-evolutionary loop between a Questioner and a Solver-optimized through pseudo-labeling and reinforcement learning-V-Zero demonstrates consistent performance gains without any human intervention, improving visual mathematical and general vision-centric reasoning. Could this approach unlock a new paradigm for developing truly autonomous and adaptable multimodal AI systems?
The Illusion of Scale: Why More Data Isn’t Always Better
The foundation of many current visual reasoning systems, including Supervised Graph Reasoning via Propagation Optimization (GRPO), rests upon substantial quantities of meticulously labeled data. This reliance presents a significant bottleneck, as acquiring and annotating datasets for complex tasks – such as understanding spatial relationships or inferring object properties – is both expensive and time-consuming. The need for exhaustive labeling not only limits the scalability of these approaches, but also introduces potential biases reflecting the annotators’ interpretations, hindering generalization to novel scenarios. Consequently, the performance of supervised learning methods often plateaus as the complexity of the visual reasoning task increases, revealing the inherent limitations of learning solely from explicitly provided examples.
Despite achieving success within constrained domains, current supervised learning approaches often falter when confronted with scenarios differing even slightly from their training data. This limitation stems from a reliance on correlative patterns rather than a deeper comprehension of underlying visual principles; the models excel at recognizing what has been seen, but struggle to infer what could be. Consequently, tasks demanding abstract reasoning, commonsense knowledge, or the ability to extrapolate from limited examples prove exceptionally challenging. These systems frequently misinterpret subtle contextual cues or fail to account for the physical constraints of the visual world, highlighting a fundamental gap between pattern recognition and genuine visual understanding – a capacity that necessitates more than simply scaling up existing architectures or datasets.
Escaping the Labeling Trap: A Self-Evolving Framework
V-Zero represents a departure from traditional supervised learning paradigms by enabling model improvement without reliance on large, labeled datasets. This is achieved through a system that operates entirely on unlabeled image data, utilizing a co-evolutionary loop to drive performance gains. The framework iteratively challenges and refines its internal reasoning processes based solely on the inherent structure within the unlabeled data itself, eliminating the costly and time-consuming process of manual annotation. This approach allows for continuous self-improvement and adaptation to new data distributions without external human intervention, offering a scalable and efficient alternative to conventional methods.
V-Zero’s core functionality revolves around a Questioner and Solver architecture, designed for iterative refinement without external data labeling. The Solver attempts to address given prompts or tasks, while the Questioner generates challenging queries intended to expose weaknesses in the Solver’s reasoning. Responses from the Solver, and the subsequent questioning, form a co-evolutionary loop; the Questioner adapts to better identify flaws, and the Solver improves its responses to address those identified weaknesses. This process enables continuous improvement in reasoning capabilities as the system self-corrects through internal challenge and response, bypassing the need for human-annotated datasets.
V-Zero’s operational infrastructure is predicated on the Verl Framework, a system designed for scalable and reproducible AI development. This foundation provides the necessary components for managing the complex co-evolutionary loop between the Questioner and Solver agents. Furthermore, V-Zero integrates with vLLM, a high-throughput and memory-efficient serving system for large language models. This integration allows for rapid deployment and evaluation of model iterations, significantly accelerating the self-improvement process by enabling efficient rollout of updated Questioner and Solver configurations.
The Devil is in the Question: Dual-Track Reasoning for Deeper Understanding
The V-Zero framework’s performance is directly linked to its Dual-Track Reasoning Reward, a mechanism designed to elicit more complex questioning from the Questioner model. This reward system functions by evaluating whether generated questions necessitate reasoning beyond simple pattern recognition in the Solver. Specifically, the reward is higher when the Solver’s initial, intuitive response differs from its subsequent, reasoned output after attempting to answer the question. This discrepancy indicates the question successfully probed for deeper understanding and prevented a superficial answer, thereby reinforcing the generation of challenging and insightful queries.
The Dual-Track Reasoning Reward system functions by explicitly comparing the Solver’s immediate, unreasoned response to its subsequent, logically derived answer. This comparison isn’t simply a check for correctness; it assesses whether the generated question necessitates a distinction between these two outputs. If the Solver can answer the question using only its initial intuition, the question is deemed insufficiently challenging and receives a lower reward. Conversely, questions that force the Solver to engage in a more deliberate reasoning process, producing a different answer than its initial response, are positively reinforced. This mechanism ensures that the Questioner focuses on generating inquiries that genuinely test the Solver’s understanding, rather than exploiting superficial patterns or easily accessible information.
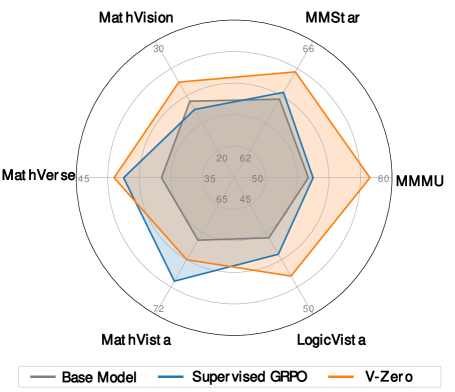
Evaluations demonstrate that V-Zero attains an average score of 51.9 across all benchmark tests, encompassing both mathematical and general knowledge assessments, when utilizing the Qwen2.5-VL-7B-Instruct language model. This performance represents a 2.0 point increase over the baseline model’s average score on the same benchmarks. The scoring methodology consistently applies to both benchmark categories to facilitate direct comparison and quantify the improvement achieved through the V-Zero framework and the specified language model.
Difficulty-Guided Data Sampling within the V-Zero framework prioritizes training examples that fall within an optimal complexity range for the Solver. This technique avoids both trivially solvable instances, which offer minimal learning signal, and excessively ambiguous problems that hinder effective reasoning. By focusing on examples of moderate difficulty, the Solver is presented with challenges that require genuine problem-solving capabilities, promoting more robust and generalizable learning. The selection process dynamically adjusts to the Solver’s current proficiency, ensuring a continuous stream of appropriately challenging examples throughout the training process, thereby maximizing learning efficiency and performance.
Beyond Benchmarks: Towards Adaptable and Efficient Visual Intelligence
Recent experimentation reveals a compelling advancement in visual reasoning through V-Zero, a framework designed to elevate the capabilities of existing large multimodal models. Utilizing both Qwen2.5-VL-3B-Instruct and Qwen2.5-VL-7B-Instruct as foundational models, researchers demonstrate that V-Zero substantially improves reasoning performance without the need for costly and time-consuming labeled datasets. This approach allows models to refine their understanding of visual information and complex relationships solely through the process itself, offering a pathway towards more adaptable and efficient visual-language models capable of tackling sophisticated tasks with greater accuracy and less reliance on extensive pre-training data.
The development of V-Zero relies heavily on the OpenVLThinker Dataset, a purposefully constructed benchmark that pushes the boundaries of visual and linguistic reasoning. This dataset isn’t simply a collection of images and questions; it’s specifically designed to rigorously evaluate a model’s ability to interpret geometric relationships and extract meaningful insights from charts and diagrams. By training on this complex dataset, V-Zero hones its capacity for abstract thought and logical deduction, learning to connect visual cues with corresponding linguistic representations. The dataset’s emphasis on spatial reasoning and data interpretation allows V-Zero to develop a nuanced understanding of visual information, ultimately improving its performance on tasks requiring more than simple object recognition and captioning.
Evaluations on the MMMU (Multi-Modal Multi-task Understanding) benchmark reveal a substantial performance gain following the implementation of V-Zero training; the model achieved an improvement of +3.9 points, demonstrating a heightened capacity for complex reasoning. This benchmark assesses a model’s ability to integrate visual and textual information to solve multifaceted problems, and the observed increase signifies a tangible advancement in V-Zero’s comprehension and analytical skills. The gain isn’t merely incremental; it highlights the framework’s potential to unlock more sophisticated understanding in visual language models without relying on extensive, labeled datasets, suggesting a path toward more efficient and capable AI systems.
A notable outcome of the V-Zero training process is the dramatic improvement in format validity – the ability of the model to consistently produce structurally correct answers. Initial performance with the base models registered a Format Validity Rate of only 64.9%, indicating frequent errors in the presentation of solutions. However, after a single iteration of V-Zero training, this rate surged to 99.1%. This signifies a substantial enhancement in the model’s capacity to not just arrive at the correct answer, but to express it in a logically sound and easily interpretable format, suggesting a deeper understanding of the underlying reasoning process and a refined ability to translate internal calculations into externally valid responses.
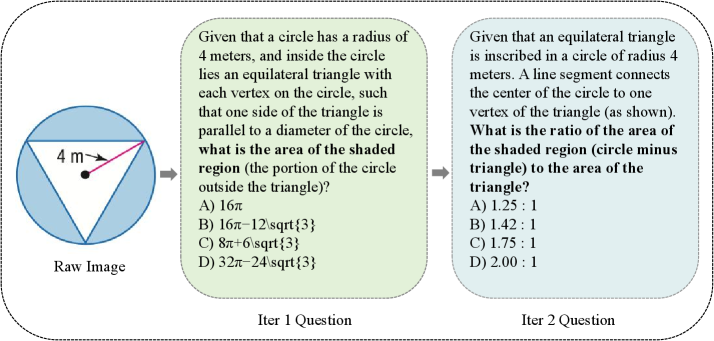
Evaluation using Qwen3-VL-8B-Instruct reveals a marked improvement in the complexity of questions successfully addressed following a single iteration of V-Zero training; the Question Difficulty Score rose substantially from 0.52 in the original base model to 0.60. This increase indicates that V-Zero not only enhances a model’s ability to answer questions, but also its capacity to grapple with more challenging and nuanced visual reasoning problems. The observed shift suggests that the training process effectively equips the model to interpret intricate visual information and derive accurate conclusions, representing a considerable step towards more sophisticated visual language understanding.
Evaluations on the MathVerse benchmark reveal a substantial performance boost following V-Zero training, with the model achieving a 3.0 point improvement. This benchmark specifically challenges visual language models with complex mathematical problems presented in visual formats, requiring not only accurate image understanding but also the ability to translate visual information into symbolic mathematical reasoning. The gain on MathVerse underscores V-Zero’s capacity to bridge the gap between visual perception and abstract thought, indicating enhanced capabilities in tackling problems that demand both geometric and algebraic intelligence. This improvement highlights the potential of the framework to deliver more robust and versatile visual language models capable of addressing real-world applications requiring mathematical proficiency.
The development of V-Zero introduces a paradigm shift in visual language model (VLM) training, offering a potent alternative to the resource-intensive demands of traditional supervised learning. By leveraging unlabeled data and a carefully constructed training framework, V-Zero demonstrates the capacity to significantly enhance reasoning abilities in base models without requiring costly and time-consuming data annotation. This approach not only streamlines the development process but also unlocks the potential for creating more adaptable VLMs capable of generalizing to novel visual reasoning tasks – from geometric problem-solving to chart interpretation and complex mathematical reasoning – ultimately paving the way for more efficient and versatile artificial intelligence systems.
The pursuit of fully autonomous learning, as demonstrated by V-Zero’s self-improvement through question generation and solving, feels…familiar. It echoes a cycle seen countless times. The framework eliminates human annotation, a laudable goal, yet one must recall David Marr’s observation: “Representation is the key.” V-Zero constructs its own representations through co-evolution, but the inherent messiness of production environments will inevitably expose limitations in those self-generated structures. The elegance of eliminating human labels will likely be offset by the cost of debugging emergent, unexpected behaviors. It’s a clever architecture, certainly, but an expensive way to complicate everything. One anticipates a long tail of edge cases requiring manual intervention, proving, yet again, that ‘MVP’ often translates to ‘we’ll fix it later.’
The Road Ahead
The authors propose an escape from the annotation bottleneck, a noble aim. One suspects, however, that this ‘self-improvement’ is merely a sophisticated form of automated stress-testing. The system will undoubtedly discover edge cases – it always does. The real question isn’t whether V-Zero can generate questions, but whether those questions expose fundamental flaws in the Solver’s understanding, or simply reveal a knack for adversarial trivia. Scaling this co-evolutionary loop will be… interesting. Anything called ‘scalable’ hasn’t been properly tested, of course.
The current framework sidesteps annotation, but not evaluation. Someone, somewhere, still has to decide what ‘correct’ looks like. That judgement, however subtly embedded in the reward function, remains a human constraint. Future work will likely focus on automating that process, creating a closed loop of self-assessment. One anticipates a fascinating proliferation of internally consistent, yet demonstrably false, ‘truths.’
Better one robust, painstakingly curated dataset than a thousand automatically generated ones. Legacy data, while imperfect, at least carries the faint scent of human intention. The pursuit of annotation-free learning is laudable, but it’s a reminder that sometimes, the cost of avoiding effort upfront is paid in debugging cycles later. This isn’t a criticism; it’s just how things work.
Original article: https://arxiv.org/pdf/2601.10094.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- M7 Pass Event Guide: All you need to know
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
2026-01-19 00:45