Author: Denis Avetisyan
A new framework uses the power of large language models to map out causal relationships with unprecedented transparency and confidence.
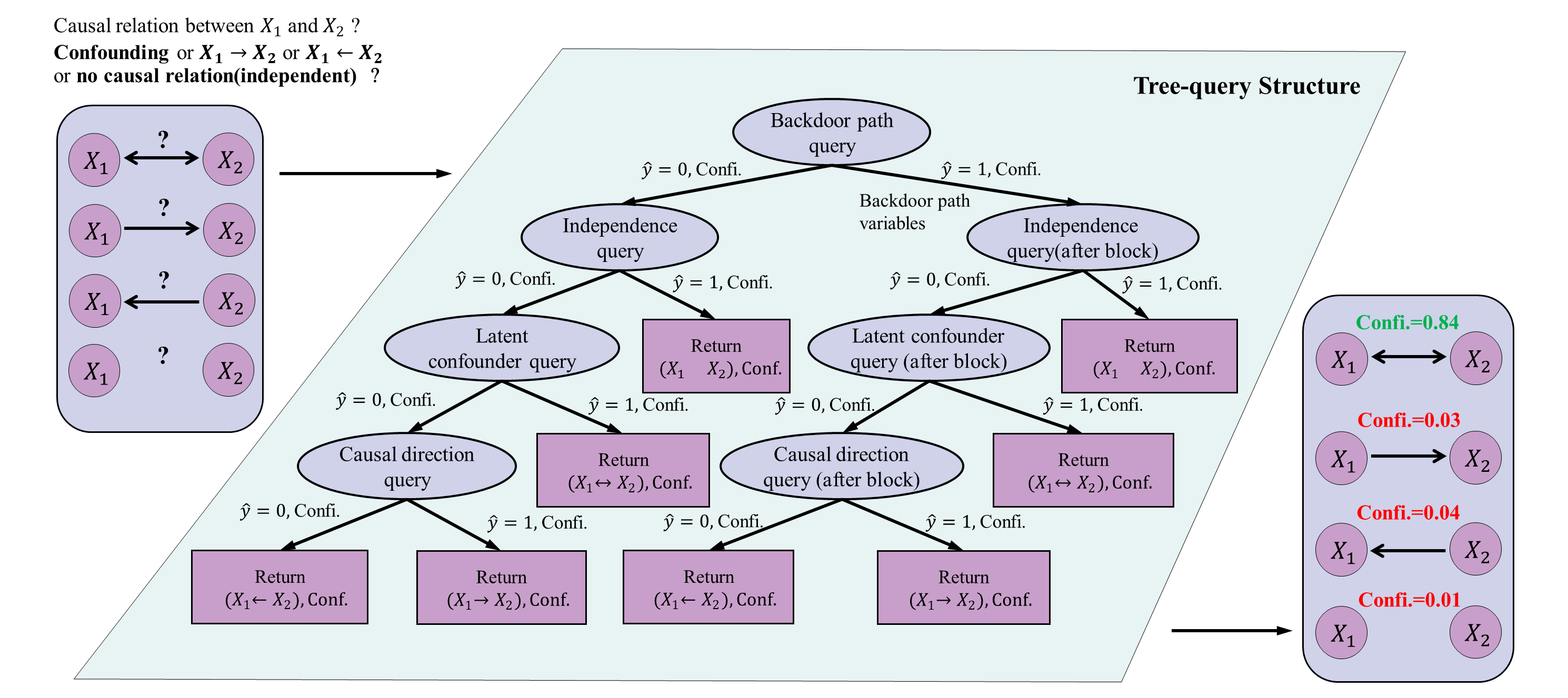
This work introduces Tree-Query, a multi-agent system for data-free causal discovery utilizing adversarial confidence estimation and structural causal models.
Despite advances in causal discovery, methods often struggle with error propagation or lack transparency, particularly when leveraging the potential of large language models. This paper introduces ‘Step-by-Step Causality: Transparent Causal Discovery with Multi-Agent Tree-Query and Adversarial Confidence Estimation’, a novel framework-Tree-Query-that decomposes causal inference into interpretable steps using a multi-expert LLM system and provides robustness-aware confidence scores. Demonstrating improved performance on benchmark datasets and a real-world case study, Tree-Query offers a principled approach to obtaining data-free causal priors from LLMs. Could this transparent, confidence-aware approach bridge the gap between LLM-based reasoning and rigorous causal analysis?
The Persistence of Causality in Data’s Absence
The prevailing methods in causal discovery typically demand substantial datasets – either observational records detailing correlations or, more powerfully, interventional data from experiments where specific variables are manipulated. However, acquiring such data can be a formidable obstacle; in many real-world scenarios, collecting comprehensive information is prohibitively expensive, time-consuming, or even ethically impossible. This limitation significantly restricts the application of causal reasoning to domains like drug discovery, climate modeling, or social science, where large-scale experimentation is impractical, and reliance on existing data is often insufficient to confidently determine cause-and-effect relationships. The dependence on readily available data therefore presents a crucial bottleneck in advancing the broader field of causal AI and its potential impact.
The practical deployment of causal artificial intelligence is often hampered by a fundamental need for extensive datasets, a requirement that presents considerable obstacles across numerous fields. Many real-world problems, from personalized medicine to climate modeling, involve systems where acquiring sufficient observational or interventional data is prohibitively expensive, time-consuming, or even ethically impossible. This data scarcity severely restricts the scope of causal AI, preventing its application to crucial areas where causal understanding-rather than mere correlation-is paramount. Consequently, the inability to effectively reason about cause and effect in data-limited environments diminishes the potential impact of this powerful technology, leaving many critical challenges unaddressed and hindering progress in domains reliant on informed decision-making.
Data-Free Causal Discovery represents a pivotal frontier in artificial intelligence, addressing the fundamental limitation of conventional causal inference methods – their reliance on substantial datasets. This emerging field seeks to delineate cause-and-effect relationships purely through background knowledge, assumptions about the underlying system, or constraints imposed on the possible causal structures. Unlike traditional approaches that statistically analyze observed patterns, Data-Free methods operate in scenarios where empirical data is either inaccessible, prohibitively expensive to acquire, or simply nonexistent. Successfully navigating this challenge requires innovative techniques, often drawing from fields like symbolic reasoning, constraint satisfaction, and the formalization of domain expertise, to effectively ‘infer’ causality without the benefit of statistical evidence. The potential impact of such advancements is significant, promising to extend the reach of causal AI into domains previously considered intractable, such as early-stage scientific discovery, policy-making with limited historical data, and the development of robust AI systems capable of reasoning in data-scarce environments.
Deconstructing Causality: The Tree-Query Framework
Tree-Query functions as a multi-expert system by breaking down the problem of determining causal relationships between two variables into a structured sequence of individual queries. Rather than attempting to directly assess the overall causal connection, the system decomposes this complex task into smaller, more manageable sub-problems, each addressed by a specialized query type. This decomposition enhances transparency by allowing explicit examination of the reasoning behind each step and facilitates the application of Large Language Models (LLMs) to targeted inference tasks. The modular design allows for focused expertise within each query, improving the accuracy and interpretability of the causal discovery process.
Tree-Query employs a structured approach to causal discovery through the sequential application of specific query types. Independence Queries determine statistical independence between variables to identify potential direct causal effects. Backdoor Path Queries assess whether a non-causal path between two variables exists, requiring adjustment to estimate the true causal effect. Finally, Latent Confounder Queries investigate the presence of unobserved variables that may be influencing the observed relationship between variables; these queries are crucial for identifying and accounting for biases introduced by unmeasured confounding. This systematic query sequence allows for a focused analysis of potential causal relationships, facilitating more reliable causal inference.
Tree-Query operationalizes causal inference by transforming the problem into a sequence of discrete, linguistically structured queries that align with the capabilities of Large Language Models (LLMs). Rather than requiring LLMs to directly assess complex causal graphs, Tree-Query presents focused questions regarding statistical independence, potential backdoor paths, and the presence of latent confounders. This decomposition allows LLMs to utilize their established strengths in natural language processing – including parsing, semantic understanding, and logical inference – to provide answers that are then aggregated to determine causal relationships. By framing the process as question answering, Tree-Query bypasses the need for LLMs to possess intrinsic causal reasoning abilities and instead leverages their proficiency in understanding and responding to natural language prompts.
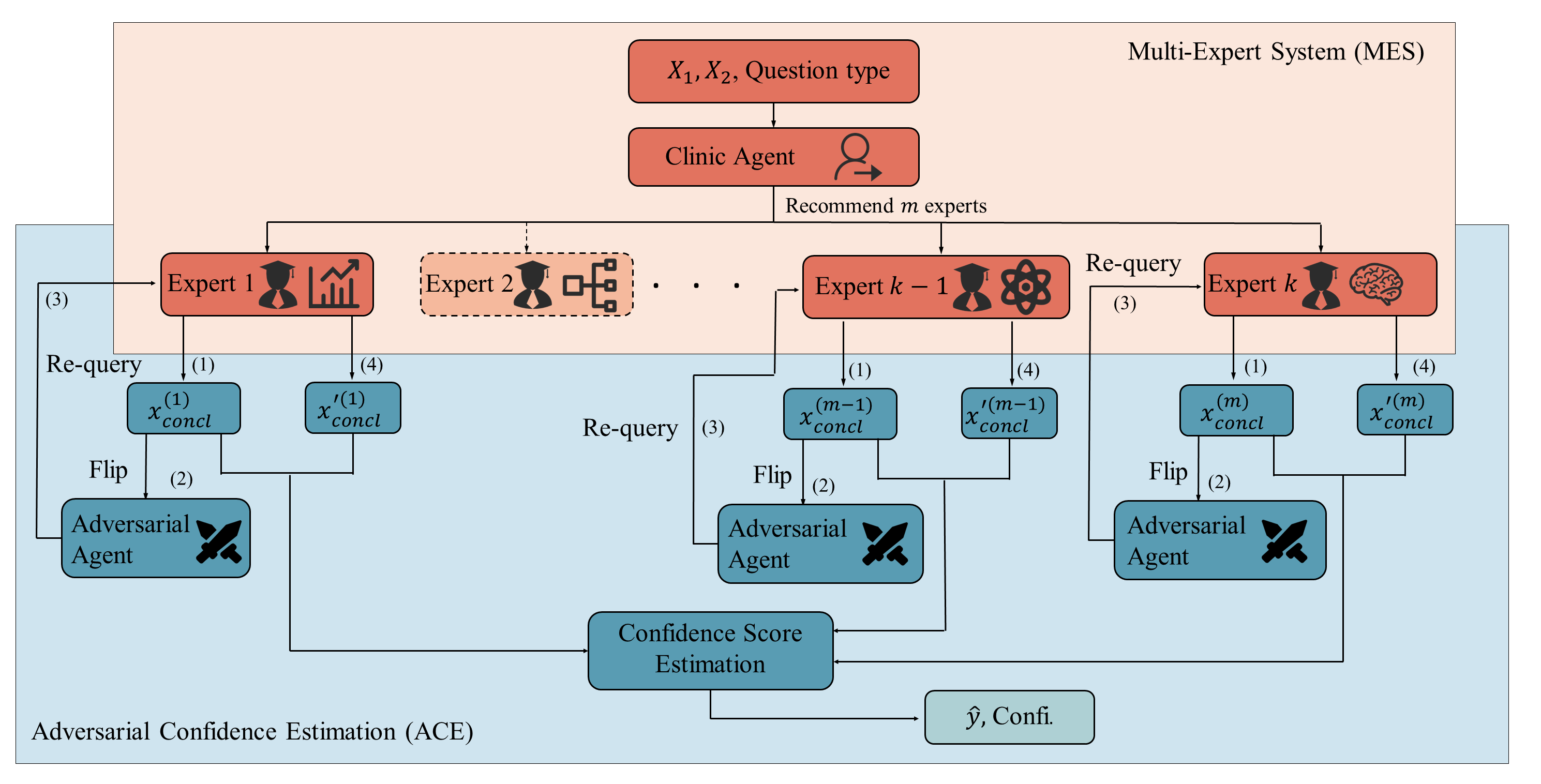
Bolstering Judgements: Adversarial Confidence Estimation
The Adversarial Confidence Estimator functions as a core component of the Tree-Query framework by systematically evaluating the stability of causal judgements produced by Large Language Models (LLMs). This is achieved through the generation of adversarial counterarguments designed to challenge the LLM’s initial conclusions. By presenting alternative perspectives and probing for inconsistencies, the estimator identifies vulnerabilities in the LLM’s reasoning process. The resulting analysis provides a quantifiable assessment of the LLM’s robustness, indicating the degree to which its judgements are resistant to subtle changes in input or framing. This process is crucial for determining the reliability of LLM-derived causal claims and mitigating the risk of erroneous conclusions.
The adversarial counterargument generation process within Tree-Query involves constructing alternative prompts designed to elicit different responses from the Large Language Model (LLM) regarding the same causal query. These counterarguments are not simply rephrased questions; they introduce subtle but relevant contextual shifts or challenge underlying assumptions within the initial query. By comparing the LLM’s responses to both the original and adversarial prompts, the framework identifies potential inconsistencies or sensitivities in the model’s reasoning. Significant divergence between these responses indicates a vulnerability, suggesting the LLM’s initial judgement may not be robust to minor variations in input or context and highlighting a lack of consistent causal understanding.
The Wasserstein-1 Distance, also known as the Earth Mover’s Distance, is employed to numerically assess the difference between the probability distributions of the Large Language Model’s (LLM) original response and its response to an adversarial counterargument. This distance metric calculates the minimum “cost” of transforming one distribution into another, where cost is defined by the amount of “work” required to move probability mass. A larger Wasserstein-1 Distance indicates a greater distributional shift between the original and adversarial answers, signifying lower confidence and potential instability in the LLM’s causal judgement. Conversely, a smaller distance suggests the LLM maintains consistent reasoning even when challenged, implying a higher degree of robustness in its claims.
Evaluation using the Structural Hamming Distance (SHD) demonstrates that Tree-Query significantly reduces structural errors in causal graph estimation compared to direct querying of Large Language Models. Specifically, Tree-Query achieves a reduction of approximately 20 edges in SHD on both Standard and Latent benchmarks. SHD quantifies the difference between the estimated causal graph and the ground truth; a lower SHD indicates higher accuracy. This reduction in structural errors suggests that the iterative refinement process within Tree-Query effectively mitigates inaccuracies introduced by the LLM’s initial responses, leading to more reliable causal graph constructions.
Evaluation of the framework using the Normalized Discounted Cumulative Gain (NDCG) metric demonstrates performance between 0.73 and 0.81 across both Standard and Latent benchmarks. NDCG assesses the ranking quality of the generated causal graphs by measuring the relevance of the predicted edges, with higher scores indicating better performance. This range signifies a substantial ability to accurately rank correct causal relationships relative to incorrect ones, providing a quantitative measure of the framework’s effectiveness in generating plausible and accurate causal structures on these datasets.
The Confidence Score generated by the Tree-Query framework represents a quantifiable metric for assessing the reliability of causal claims derived from Large Language Models. This score is calculated based on the distributional shift between the LLM’s initial response and its response to adversarial counterarguments, as measured by the Wasserstein-1 Distance. A lower Wasserstein-1 Distance – and therefore a higher Confidence Score – indicates greater consistency and robustness in the LLM’s reasoning, suggesting a higher degree of confidence in the causal claim. This provides a numerical value that can be used to compare the reliability of different causal assertions or to establish thresholds for accepting or rejecting LLM-generated conclusions.
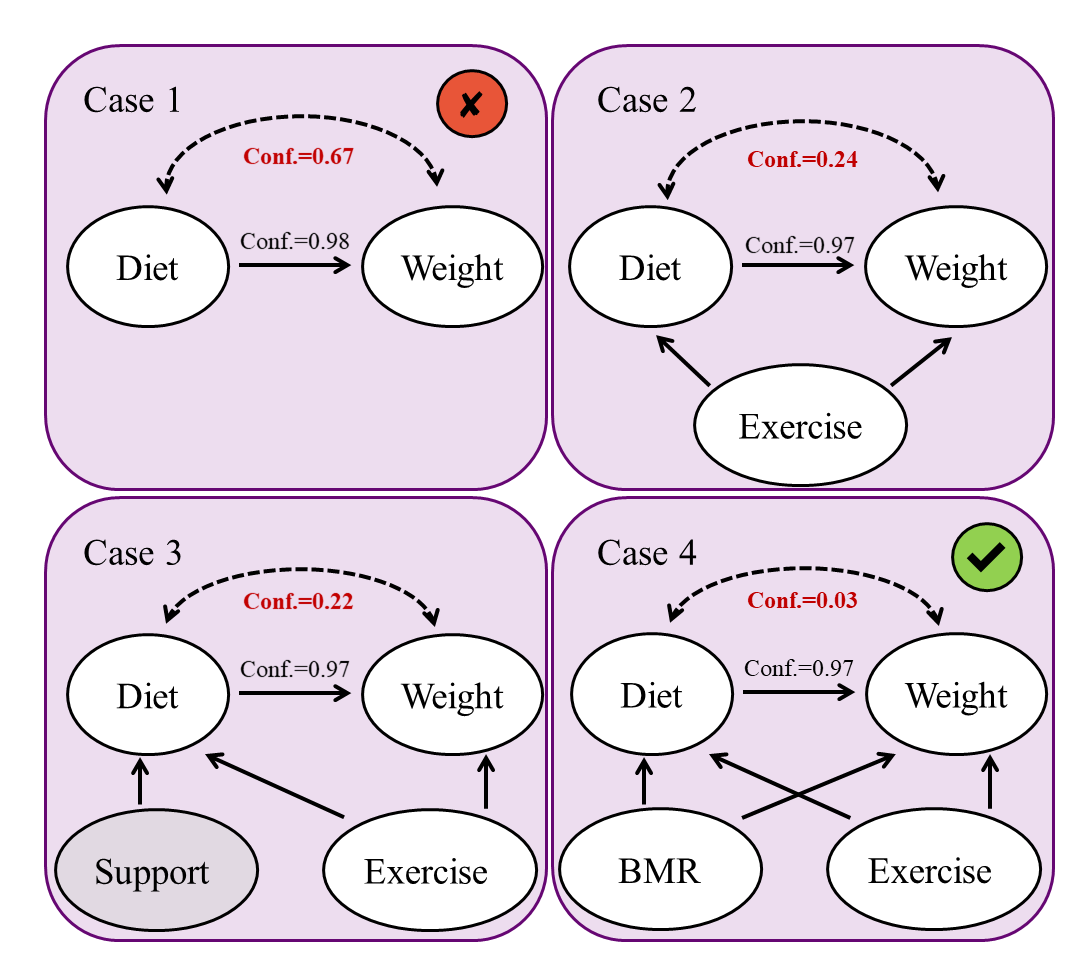
Extending the Reach: Applications and Future Directions
The innovative technique of Tree-Query, when paired with direct querying of large language models, dramatically broadens the potential of Data-Free Causal Discovery. Traditionally, establishing causal relationships required substantial datasets; however, this approach circumvents that limitation by leveraging the pre-existing knowledge embedded within LLMs. Tree-Query structures a series of targeted questions, prompting the LLM to evaluate potential causal links based on its understanding of the world, effectively simulating data-driven analysis without actual data. This allows researchers to explore causal hypotheses in scenarios where data is scarce, expensive to obtain, or simply doesn’t yet exist, opening avenues for discovery in fields like preliminary scientific investigation and prospective policy assessment. The combination offers a powerful means of causal reasoning previously unattainable, representing a significant leap forward in the field of causal inference.
The capacity to perform causal reasoning with limited or absent data represents a paradigm shift for numerous fields. Traditionally, establishing causal links demanded extensive datasets for statistical analysis; however, techniques like Tree-Query, when paired with large language models, circumvent this dependency. This unlocks the potential for early-stage scientific discovery, where preliminary hypotheses often precede comprehensive data collection, allowing researchers to explore potential mechanisms and refine theories before investing in costly experiments. Similarly, policy evaluation benefits significantly, as the causal impacts of proposed interventions can be assessed before implementation, mitigating risks and optimizing strategies in scenarios where controlled trials are impractical or unethical. The ability to reason causally in data-scarce environments promises to accelerate progress across diverse disciplines, from fundamental science to societal problem-solving.
Ongoing development prioritizes enhancing Tree-Query’s computational performance and its ability to handle increasingly complex causal structures; current limitations in speed and scalability necessitate algorithmic refinements and potential parallelization strategies. Simultaneously, research is directed towards building more robust counterfactual reasoning by generating adversarial arguments – carefully crafted scenarios designed to challenge the discovered causal relationships – which will rigorously test the model’s assumptions and identify potential vulnerabilities. This focus on both efficiency and argumentative robustness aims to move beyond simple causal identification towards a system capable of nuanced, defensible, and ultimately, more trustworthy causal inference in data-scarce environments.
The synergistic pairing of large language models with the principles of causal inference represents a paradigm shift in how complex systems are analyzed and potentially controlled. Traditionally, establishing causal relationships required extensive datasets and rigorous experimentation; however, the capacity of LLMs to articulate nuanced reasoning and simulate hypothetical scenarios provides a powerful new tool. This convergence allows researchers to move beyond mere correlation and explore the ‘what if’ questions crucial for effective intervention. By leveraging the knowledge embedded within these models, it becomes possible to not only understand the drivers of complex phenomena – from economic trends to biological processes – but also to predict the likely outcomes of different actions, paving the way for more informed decision-making and targeted interventions across diverse fields.
The pursuit of causal understanding, as detailed in this work, often leads to increasingly intricate models. However, the framework presented prioritizes distilling complex relationships into transparent, queryable structures. This echoes Donald Knuth’s sentiment: “Premature optimization is the root of all evil.” The researchers didn’t begin with a desire to create the most complex system, but rather focused on a clear, understandable method – Tree-Query – to establish causal links. This simplicity isn’t a limitation; it’s a direct result of deep comprehension, allowing for robust adversarial confidence estimation and ultimately, more reliable causal discovery. The elegance of the approach lies in its ability to reveal, rather than obscure, the underlying causal mechanisms.
What Remains?
The pursuit of causal structure, now mediated through the oracle of Large Language Models, arrives at a curious juncture. This work pares the process to its essence – a series of directed queries, a scaffold upon which confidence can be estimated, and ultimately, discarded if insufficient. The remaining challenge isn’t necessarily more data, or even larger models, but a ruthless examination of what is truly necessary to establish a meaningful causal link. The elegance of Tree-Query lies in its transparency; it exposes the scaffolding, rather than attempting to hide it within opaque layers of complexity.
Future work will inevitably explore scale – the application of this framework to domains of immense complexity. However, a more fruitful path may reside in the inverse: identifying the minimal sufficient conditions for reliable causal inference. Can the adversarial confidence estimation be refined to a point where spurious connections are not merely flagged, but actively prevented? The field risks becoming enamored with increasingly intricate methods while neglecting the fundamental question of parsimony.
Ultimately, the true test won’t be the discovery of more causal relationships, but the ability to confidently discard those that are not demonstrably true. A simpler map, accurately depicting the essential connections, remains preferable to a sprawling, detailed atlas filled with conjecture. The value lies not in what is added, but in what is left behind.
Original article: https://arxiv.org/pdf/2601.10137.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- M7 Pass Event Guide: All you need to know
- ATHENA: Blood Twins Hero Tier List
2026-01-18 02:56