Author: Denis Avetisyan
Generative AI is rapidly changing how embedded systems are built, but integrating it into existing workflows presents significant hurdles.
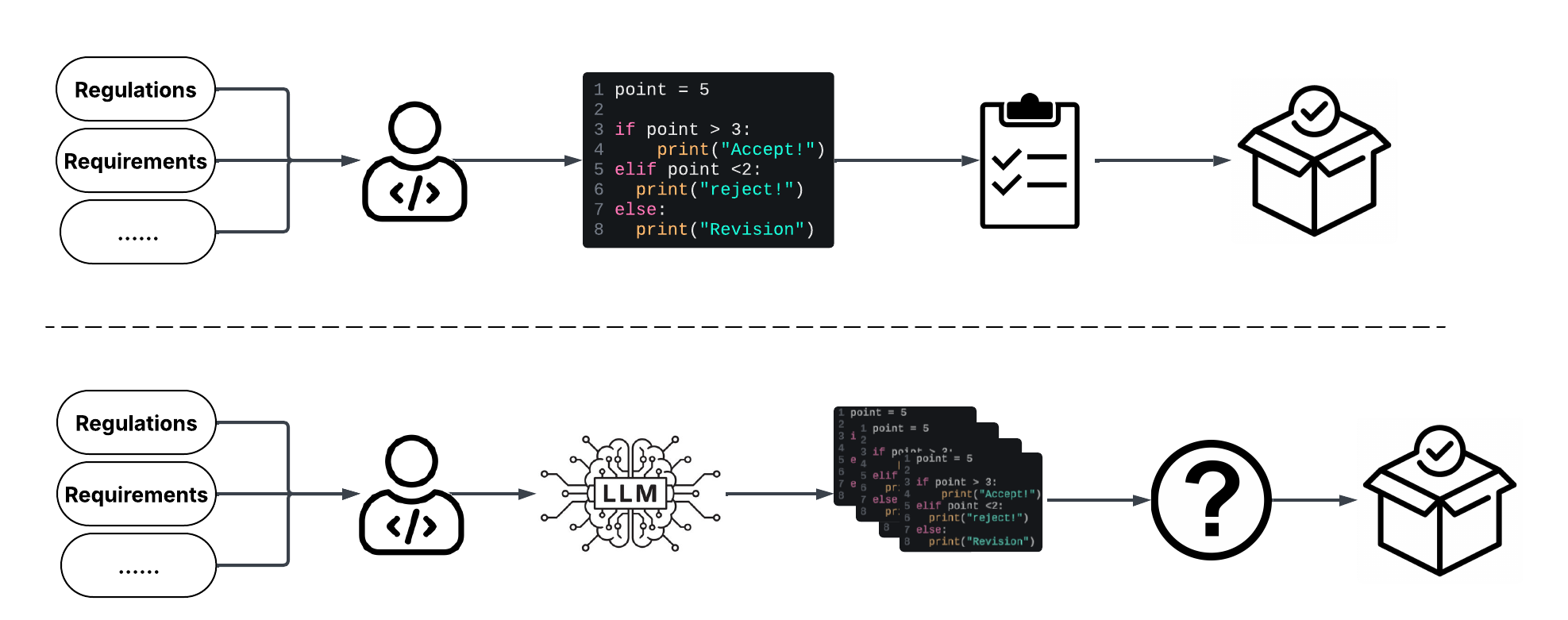
This review examines emerging practices and challenges in adopting agentic pipelines for embedded software engineering, focusing on traceability, governance, and human-in-the-loop integration.
While software engineering rapidly adopts generative AI, integrating these tools into the safety-critical domain of embedded systems presents unique hurdles. This paper, ‘Agentic Pipelines in Embedded Software Engineering: Emerging Practices and Challenges’, investigates how organizations are navigating this transition, revealing emerging practices and challenges related to workflow orchestration, responsible governance, and sustainable adoption. Our qualitative study with industry experts identifies eleven practices and fourteen challenges shaping the move toward agentic pipelines and generative AI-augmented development for embedded systems. How can engineering teams best balance the potential of generative AI with the stringent demands for reliability and traceability in resource-constrained environments?
The Weight of Assurance: Safety-Critical Software’s Demands
The development of software for safety-critical applications, such as those found in automotive and aerospace industries, is fundamentally governed by a suite of stringent, internationally recognized standards. Frameworks like ISO-26262 for automotive, DO-178C for aviation, and IEC-61508 for general industrial applications, don’t simply suggest best practices; they dictate a comprehensive lifecycle of development processes, documentation, and testing. These standards demand exhaustive verification and validation at every stage, from initial requirements specification to final implementation and maintenance, ensuring that system failures are either prevented or mitigated to an acceptable level of risk. The intention is to demonstrably prove that the software will operate reliably and predictably, even under adverse conditions, protecting human life and preventing catastrophic events. This rigorous approach, while effective, creates substantial overhead in both time and resources, prompting exploration into innovative development methodologies.
The pursuit of functional safety in traditionally engineered systems necessitates an exhaustive regimen of testing and verification, a process that escalates dramatically in complexity and cost alongside increasing software size and intricacy. Each line of code, each interaction between modules, and each potential failure mode requires meticulous examination to ensure reliable operation, especially within safety-critical applications like automotive control or aircraft avionics. This thoroughness isn’t merely about identifying bugs; it’s about demonstrably proving the absence of hazards, a task that demands extensive documentation, specialized tooling, and a significant investment of both time and resources. Consequently, the cost of achieving certification under standards like ISO-26262 or DO-178C can represent a substantial portion of the overall project budget, creating a growing challenge for developers striving to innovate within these highly regulated domains.
The integration of artificial intelligence into safety-critical systems, while promising increased automation and efficiency, presents substantial hurdles concerning reliability and assurance. Traditional software operates with defined, predictable behaviors, allowing for exhaustive testing and verification against established standards. However, the inherent complexity of AI, particularly with machine learning models, introduces non-deterministic behaviors – outputs aren’t always directly traceable to inputs, making it difficult to guarantee consistent performance. This poses significant challenges for industries like automotive and aerospace, where failures can have catastrophic consequences; verifying the safety of an AI component requires novel approaches that go beyond conventional testing methods, demanding new metrics and validation techniques to establish confidence in its predictability and deterministic operation before deployment in safety-critical applications.
Augmented Engineering: A Shift in Development Paradigms
Generative AI models, specifically Large Language Models (LLMs) such as GPT-5, Claude 3, Gemini 2, and Sonnet 4.5, are demonstrating the capacity to automate aspects of software development through code generation. These models, trained on extensive code datasets, can synthesize code snippets, complete functions, and even generate entire program structures based on natural language prompts or existing codebases. This automation potential extends to multiple programming languages and software architectures, offering a pathway to accelerate development cycles, reduce manual coding efforts, and potentially lower development costs. Current implementations typically involve developers providing high-level specifications or examples, with the LLM generating the corresponding code, which then requires review and testing by human developers to ensure functionality, security, and adherence to coding standards.
Agentic Software Engineering Frameworks utilize a distributed approach to software development, employing multiple autonomous agents within a Continuous Integration/Continuous Delivery (CI/CD) pipeline. These agents, each designed for specific tasks – such as code generation, testing, documentation, or deployment – communicate and collaborate to achieve project goals. Unlike traditional linear CI/CD, multi-agentic systems allow for parallel execution of tasks and dynamic task assignment based on agent capabilities and project needs. This architecture enables automation of complex workflows, including automated bug fixing, feature implementation, and refactoring, by distributing the workload and leveraging specialized agent expertise. Communication typically occurs via standardized interfaces and message passing, facilitating coordination and knowledge sharing between agents throughout the development lifecycle.
Effective integration of AI-generated code necessitates the implementation of stringent control and validation procedures within the software development lifecycle. Current testing methodologies, including unit, integration, and system testing, must be augmented to specifically address the unique characteristics and potential vulnerabilities of AI-produced code. This includes automated static and dynamic analysis tools configured to identify errors, security flaws, and deviations from established coding standards. Furthermore, existing CI/CD pipelines require adaptation to incorporate AI-specific validation stages, potentially involving human-in-the-loop review for critical components, and robust version control to manage AI-generated code modifications. Successful deployment hinges on the ability to reliably assess code quality, ensure functional correctness, and maintain adherence to project requirements despite the automated generation process.
Trustworthy Intelligence: Verification and Control Mechanisms
Human-in-the-loop supervision involves integrating human expertise into the AI-assisted code generation process to validate outputs and ensure safety. This typically manifests as a review stage where developers examine AI-generated code for functional correctness, security vulnerabilities, and adherence to established coding standards and safety protocols. Critical aspects of this supervision include verifying that the code behaves as intended, identifying potential edge cases or failure modes not addressed by the AI, and confirming compliance with relevant regulations or organizational policies. The process isn’t simply a post-hoc check; it can be iterative, with human feedback used to refine the AI’s subsequent outputs and improve its overall performance and reliability. This oversight is particularly crucial in safety-critical applications where even minor errors could have significant consequences.
Compiler-in-the-Loop (CITL) feedback integrates a compilation step directly into the AI-assisted code generation process. This allows for immediate detection of syntax errors, type mismatches, and other compile-time issues within the AI-generated code. Instead of solely relying on post-generation testing, CITL provides real-time error signals to the AI model, enabling it to iteratively refine and correct its output. This closed-loop system improves code quality by addressing errors during creation, reducing the burden on subsequent testing phases and accelerating the development lifecycle. CITL is particularly effective for identifying issues that might not be apparent through semantic analysis alone, such as incorrect use of APIs or library functions.
Prompt management and model context protocols are essential for regulating Large Language Model (LLM) behavior and achieving reproducible results. These mechanisms involve structuring input prompts with specific instructions, constraints, and examples to guide the LLM towards desired outputs. Model context protocols define the scope of information available to the LLM during inference, including relevant data, system messages, and conversation history, which influences its responses. By carefully controlling both the prompt structure and the model’s contextual awareness, developers can minimize ambiguity, reduce the likelihood of unintended outputs, and ensure consistent performance across multiple invocations of the LLM. This includes techniques such as few-shot learning, chain-of-thought prompting, and the use of specialized system prompts to establish clear behavioral guidelines.
AI-Friendly Artifacts represent a shift in software development practices towards structures specifically designed for efficient Large Language Model (LLM) processing. These artifacts prioritize clear, consistent code formatting, comprehensive and standardized documentation – including docstrings and API specifications – and the use of well-defined data schemas. By employing techniques such as modular code organization, explicit dependency declarations, and adherence to established coding standards, LLMs can more accurately interpret code intent, generate reliable modifications, and produce higher-quality outputs. The implementation of AI-Friendly Artifacts directly addresses the limitations of LLMs in handling ambiguous or poorly structured code, resulting in improved code synthesis, bug detection, and overall software reliability in AI-assisted development workflows.
The Horizon of Safe AI: Impacts and Future Directions
The integration of artificial intelligence into safety-critical systems necessitates a proactive investment in engineering education and skills development. Current software development curricula often lack sufficient training in the effective utilization and oversight of AI-powered tools, creating a potential skills gap as AI-augmented workflows become standard practice. Targeted training programs are therefore essential, focusing not only on how to use tools like generative AI for code creation and testing, but also on understanding their limitations, validating their outputs, and ensuring alignment with stringent safety standards. These programs must emphasize the importance of human oversight, critical thinking, and the ability to identify and mitigate potential risks introduced by AI, ultimately fostering a workforce capable of responsibly deploying and maintaining these complex systems.
The landscape of software development is poised for a dramatic shift as automated code generation tools, exemplified by platforms like GitHub Copilot and Amazon CodeWhisperer, become integral to daily workflows. These tools, driven by advancements in generative artificial intelligence, are no longer simply offering suggestions; they are actively composing functional code blocks, completing entire functions, and even proposing solutions to complex programming challenges. This increased automation isn’t intended to replace human developers, but rather to augment their capabilities, allowing them to focus on higher-level design, system architecture, and rigorous testing. The anticipated result is a significant acceleration in development cycles, a reduction in associated costs, and – crucially – the potential for improved code quality through consistent application of best practices and early detection of potential errors. As these AI-powered assistants mature, their prevalence will likely reshape the role of the software engineer, demanding a new skillset centered around prompt engineering, code review, and the responsible integration of AI-generated content.
The integration of generative AI into software development workflows is poised to reshape the creation of safety-critical systems, offering substantial gains in efficiency and dependability. Automated code generation tools are projected to dramatically curtail development timelines, as algorithms handle routine coding tasks and accelerate prototyping. This acceleration extends to cost reduction, stemming from decreased labor hours and optimized resource allocation. Crucially, the application of AI isn’t solely about speed and economy; it also offers pathways to enhanced reliability. By automating repetitive tasks and rigorously enforcing coding standards, these tools minimize the potential for human error – a major contributor to software vulnerabilities. The resultant systems are predicted to exhibit fewer defects, undergo more thorough testing, and ultimately deliver a heightened level of safety and performance, especially within domains where failure carries significant consequences.
The development of truly trustworthy and safe artificial intelligence for critical applications hinges not on replacing human expertise, but on amplifying it. Current advancements indicate a future where AI tools, such as automated code generators, handle repetitive tasks and accelerate development cycles, yet human engineers remain essential for oversight, validation, and the critical application of nuanced judgment. This collaborative paradigm leverages the strengths of both – AI’s capacity for rapid processing and pattern recognition combined with a human’s ability to understand complex requirements, anticipate unforeseen scenarios, and ensure ethical considerations are integrated into the system’s core functionality. Consequently, the most robust and reliable AI-powered systems will not be built by machines alone, but through a synergistic partnership between artificial intelligence and the skilled professionals who guide and refine its capabilities.
The integration of generative AI into embedded systems, as detailed in the study of agentic pipelines, necessitates a re-evaluation of established software engineering practices. Traditional CI/CD pipelines, designed for deterministic processes, struggle with the inherent stochasticity of large language models. The pursuit of reliability and traceability-key concerns within this evolving landscape-demands novel approaches to model context and governance. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This observation resonates deeply; the engine – or, in this case, generative AI – remains reliant on precise instruction and meticulous oversight, highlighting the continued importance of human-in-the-loop systems to ensure predictable and verifiable outcomes within complex embedded systems.
The Road Ahead
The integration of generative AI into embedded systems development, as this work illustrates, is not a problem of can it be done, but rather of discerning should it. The immediate challenges – traceability, governance, the maintenance of a coherent development lifecycle – are not merely technical hurdles. They are symptoms of a deeper unease: the introduction of non-deterministic elements into systems historically predicated on predictable behavior. The pursuit of automated efficiency threatens to obscure the fundamental need for understanding.
Future research must move beyond the optimization of pipelines and address the ontological shift underway. The Model Context Protocol, while a pragmatic step, is merely a scaffolding. A more substantial inquiry concerns the very nature of ‘correctness’ in a world where code is authored, not by human intention alone, but by probabilistic inference. What constitutes verification when the genesis of a function is an algorithmic approximation?
The ultimate limitation, one this study implicitly highlights, is not computational, but cognitive. The capacity to absorb complexity is finite. The true metric of success will not be lines of code generated per hour, but the ability to maintain a clear and concise mental model of the system – a model that, ironically, may become increasingly reliant on the very tools that threaten to obscure it.
Original article: https://arxiv.org/pdf/2601.10220.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- M7 Pass Event Guide: All you need to know
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-18 01:27