Author: Denis Avetisyan
A new framework ensures scientific automation is not only efficient, but also verifiable and auditable, addressing a critical need in modern research.
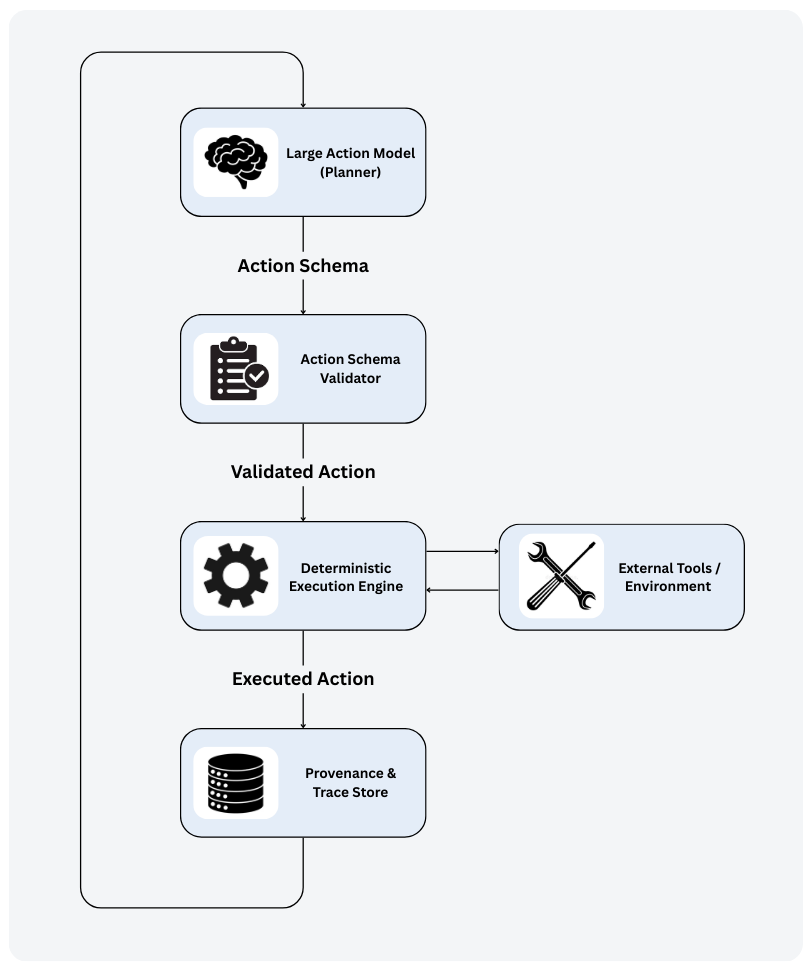
Researchers introduce R-LAM, a system enforcing constraints on action models to guarantee deterministic execution and provenance tracking in scientific workflows.
While large language models show promise for automating complex scientific workflows, their inherent non-determinism poses a critical challenge to reproducibility and reliability. This paper introduces R-LAM: Reproducibility-Constrained Large Action Models for Scientific Workflow Automation, a framework designed to address this limitation by enforcing structured action schemas, deterministic execution, and explicit provenance tracking. Our approach enables auditable and replayable workflows, improving both the success rate and trustworthiness of automated scientific experimentation. Could R-LAM unlock a new era of verifiable and adaptive automation in scientific discovery?
The Reproducibility Mirage: Why Workflows Break Down
Scientific advancement is now deeply intertwined with computationally intensive, automated workflows – sequences of tasks executed by computers to analyze data, simulate phenomena, or test hypotheses. While these workflows accelerate discovery, a critical challenge has emerged: ensuring the reproducibility of their results. Unlike traditional experiments with clearly defined protocols, these digital processes can involve intricate dependencies on software, data versions, and computational environments. This complexity creates a ‘reproducibility crisis’ as independent verification becomes difficult, potentially leading to wasted resources, flawed conclusions, and erosion of trust in scientific findings. The increasing scale and sophistication of these workflows demand new tools and practices to meticulously document each step, track data lineage, and guarantee that results can be reliably replicated by other researchers.
Scientific reproducibility is increasingly threatened by limitations in how research workflows are documented and tracked. Historically, many workflow systems prioritized execution over detailed provenance – a complete record of data origins, processing steps, and parameter settings. This lack of comprehensive tracking becomes particularly problematic as scientific projects evolve; dependencies on software, datasets, and computational environments change over time. Without precise records of these evolving dependencies, reconstructing a specific experimental result becomes exceedingly difficult, if not impossible. A workflow that functioned flawlessly yesterday might fail today due to an updated library or a subtly altered dataset, and pinpointing the source of the discrepancy requires far more than simply re-running the code – it demands a complete audit trail of the entire computational history.
Scientific workflows frequently involve intricate sequences of computational steps where intermediate data and configurations-the ‘hidden state’-are not explicitly recorded or documented. This lack of transparency presents a substantial obstacle to reproducibility, as independent researchers lack the necessary information to precisely recreate the original experimental conditions. Subtle, undocumented alterations to parameters, software versions, or even the execution environment can introduce unintended biases or errors, leading to discrepancies in results. Consequently, even seemingly minor omissions in workflow documentation can undermine the validity of scientific findings and contribute to the growing ‘reproducibility crisis’, highlighting the critical need for comprehensive provenance tracking and rigorous documentation standards within computational science.
The increasing reliance on parallel computing and stochastic algorithms introduces inherent non-determinism into scientific workflows, challenging the very foundation of reproducible research. Parallel execution, while significantly accelerating computation, doesn’t guarantee identical results across different runs due to variations in task scheduling and resource allocation. Similarly, algorithms incorporating randomness – such as Monte Carlo simulations or machine learning models initialized with random weights – will yield slightly different outputs each time they are executed. This means that even with identical input data and code, achieving bitwise reproducibility becomes exceedingly difficult. The subtle variations introduced by these factors necessitate careful consideration of statistical significance and the reporting of multiple independent runs to establish confidence in the validity of scientific findings, demanding a shift towards workflows that explicitly account for and quantify such inherent variability.
Beyond Scripts: The Rise of Actionable Models
Large Action Models (LAMs) represent an advancement beyond Large Language Models (LLMs) by integrating language understanding with the capacity to execute actions within digital environments. While LLMs primarily generate text, LAMs utilize that textual understanding to control tools, APIs, and software, thereby enabling automation of complex, multi-step tasks. This functionality is particularly relevant to scientific workflows, where LAMs can autonomously perform experiments, analyze data, and manage resources. The core distinction lies in the ability to not only describe a process but to execute it, effectively transforming LLMs from information providers to active agents within a computational system. This action execution is typically achieved through function calling or API interaction, guided by the LLM’s interpretation of user prompts or predefined protocols.
Large Action Models (LAMs) offer the potential to accelerate scientific research through automation of tasks commonly requiring significant researcher time. This includes automating data collection, experimental control, and analysis pipelines, thereby reducing turnaround times for iterative experiments. Beyond simple repetition, LAMs can facilitate the exploration of new hypotheses by systematically varying experimental parameters and analyzing resulting data, identifying trends and anomalies that might be missed through manual investigation. The ability to rapidly test a wider range of conditions and analyze larger datasets than is currently feasible expands the scope of scientific inquiry and can lead to the discovery of novel relationships and insights.
Integrating Large Action Models (LAMs) into scientific workflows presents challenges regarding action validity and system control due to the inherent complexity of translating high-level instructions into executable actions within physical or computational systems. Specifically, ensuring each action performed by the LAM aligns with established scientific protocols and does not introduce experimental error requires rigorous validation procedures. Furthermore, maintaining control over the system-including instrument settings, data acquisition parameters, and safety protocols-demands robust mechanisms for monitoring, intervention, and error recovery, as unintended or erroneous actions could compromise experimental integrity or system functionality. These challenges necessitate development of techniques for formally verifying action plans, implementing runtime monitoring, and providing human-in-the-loop control options to mitigate risks associated with autonomous operation.
Adaptive control and failure-aware execution are essential for reliable Large Action Model (LAM) integration into scientific workflows due to the inherent complexities of automating physical processes. LAMs operating in real-world environments encounter unpredictable conditions and potential errors in action execution; therefore, systems must dynamically adjust to changing circumstances. This necessitates incorporating feedback loops that monitor action outcomes and modify subsequent actions as needed. Failure-aware execution requires anticipating potential errors, implementing redundancy where feasible, and designing mechanisms for graceful degradation or recovery from failures without compromising data integrity or experimental safety. Robust systems employ techniques such as real-time monitoring of critical parameters, anomaly detection, and automated rollback procedures to mitigate the impact of unexpected events and ensure workflow stability.
R-LAM: Constraining Chaos for Reliable Results
R-LAM establishes a framework for integrating Large Action Models (LAMs) into scientific workflows while guaranteeing reproducibility. This is achieved through a system designed to deliver deterministic execution, complete provenance capture, and full reproducibility – indicated by a Reproducibility Success of 1 – without limiting the adaptive capabilities inherent in LAMs. The framework ensures that identical inputs consistently produce identical outputs without requiring re-execution of the workflow, and that all executed actions are fully logged, resulting in a Trace Completeness of 1.0. This combination of adaptive control and rigorous reproducibility is enabled by mediating the LAM’s reasoning process and isolating it from non-deterministic external factors.
The Deterministic Execution Engine within R-LAM functions as an intermediary for all Large Action Model (LAM) reasoning and action execution. This engine enforces pre-defined execution policies, which govern permitted actions and their parameters, and isolates the LAM from non-deterministic external factors such as network latency, system load, or random number generators. By mediating the execution path, the engine ensures that the same input always results in the same output, providing a crucial foundation for reproducibility. All actions initiated by the LAM are routed through this engine, which validates them against the defined policies before execution, and logs all actions for provenance tracking. This controlled environment is essential for achieving deterministic behavior in a system leveraging the adaptive control capabilities of a LAM.
R-LAM utilizes Provenance-Aware Trace Graphs to record a comprehensive execution history of scientific workflows. These graphs achieve a Trace Completeness score of 1.0, signifying that all executed actions and their associated data are captured within the provenance logs. This complete capture includes details of parameter values, software versions, and environmental conditions relevant to each action. The resulting provenance logs provide a fully auditable record, enabling precise reconstruction of the workflow’s execution path and facilitating detailed analysis of results and potential errors. This level of traceability is critical for validating scientific findings and ensuring reproducibility.
R-LAM employs Formal Action Schemas to separate the desired outcome of an action from the specific code used to achieve it, thereby enhancing the reliability of action execution and strengthening system control. This design has resulted in a measured Reproducibility Success of 1, meaning that the system consistently generates identical outputs upon repeated execution without requiring re-computation. Furthermore, R-LAM achieves a Failure Visibility of 1, indicating that all instances of failed actions are explicitly recorded within the execution trace, providing complete diagnostic information for debugging and analysis.

Beyond Verification: Reclaiming Control of Scientific Workflows
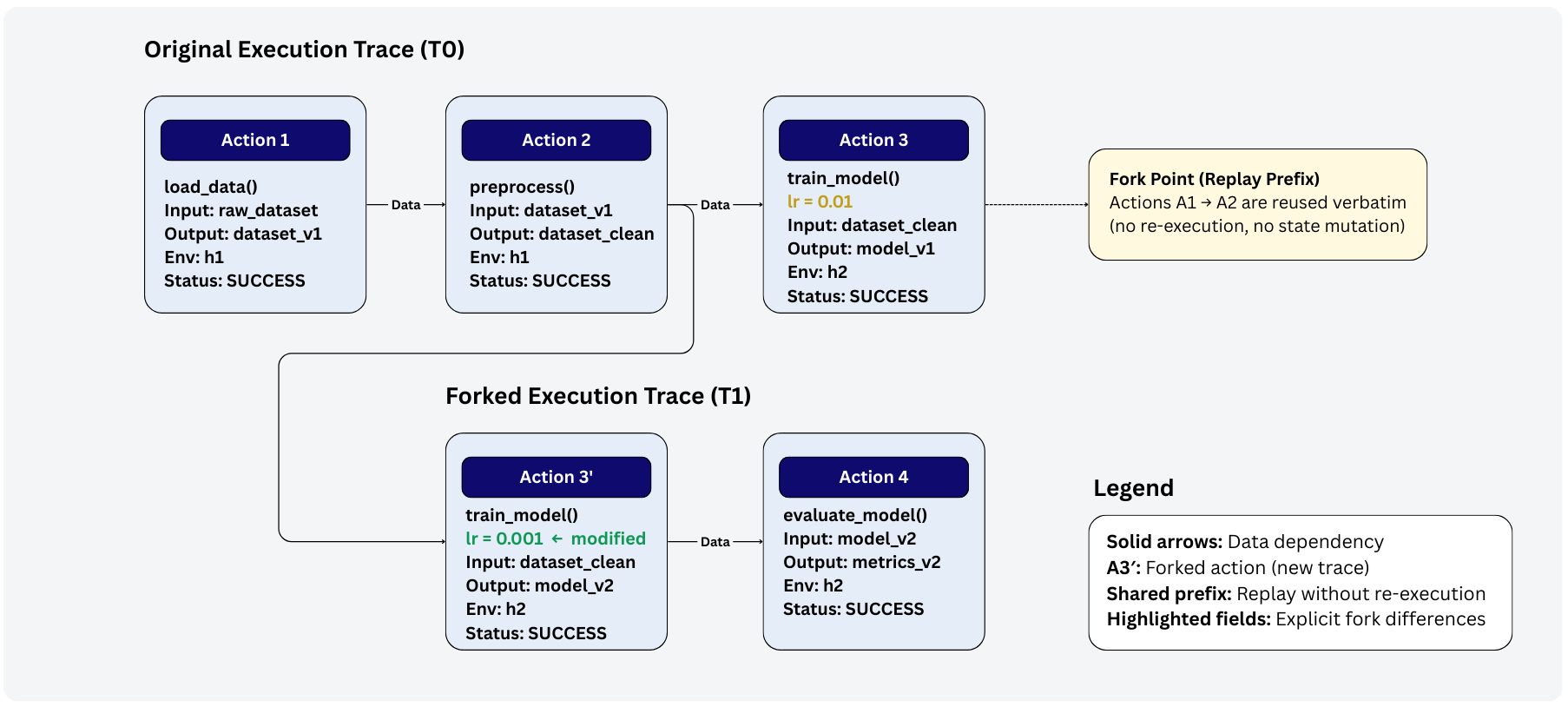
Researchers benefit from accelerated workflow development thanks to R-LAM’s capacity to both replay past executions and create divergent “forks” for experimentation. This functionality stems from the system’s meticulous recording of every computational step, effectively building a detailed execution trace. Instead of restarting lengthy analyses to test modifications, scientists can replay a workflow with altered parameters or even branch off into entirely new configurations-allowing for rapid iteration and comparison of results. This approach not only saves valuable computational resources but also empowers researchers to systematically explore the design space of complex workflows, uncovering optimal configurations and improving overall scientific productivity.
Rigorous provenance tracking, a core feature of R-LAM, dramatically streamlines the process of failure auditing within complex scientific workflows. By meticulously recording every step of an execution – including data lineage, parameter values, and software versions – the system creates a comprehensive historical record. This allows researchers to pinpoint the exact source of errors with unprecedented speed and accuracy, moving beyond guesswork to targeted correction. Instead of repeating entire workflows to diagnose issues, the detailed logs enable precise reconstruction of the failing execution path, isolating the problematic component and significantly reducing debugging time. This capability isn’t merely about fixing mistakes; it fosters a proactive approach to workflow development, allowing for iterative refinement and the creation of demonstrably more reliable scientific processes.
R-LAM fundamentally enhances the reliability of scientific inquiry through meticulous reproducibility. By capturing a complete record of workflow execution – encompassing data lineage, parameter settings, and computational steps – the system allows any researcher to recreate prior results with confidence. This isn’t merely about verifying computations; it’s about establishing a solid foundation for building upon existing knowledge. Independent verification becomes streamlined, allowing external parties to rigorously assess findings, while the ability to reliably extend previous work accelerates the pace of discovery. Consequently, R-LAM cultivates a higher degree of trust in scientific outputs, transforming workflows from opaque processes into transparent, verifiable, and collaborative endeavors.
Detailed execution traces allow for the complete reconstruction of past workflow runs, a capability crucial for long-term data analysis and the development of more resilient scientific processes. This isn’t simply about retracing steps; it facilitates the identification of subtle errors or biases that might emerge over time, especially when dealing with complex datasets or evolving analytical techniques. Researchers can effectively revisit prior results, validate findings against new evidence, and iteratively refine workflows to enhance their robustness and reliability. By preserving a comprehensive record of each execution, the system enables a form of ‘digital archeology’ of scientific inquiry, fostering a deeper understanding of data provenance and promoting the creation of workflows that consistently deliver trustworthy outcomes, even when subjected to scrutiny years after their initial implementation.
The pursuit of automated scientific workflows, as outlined in this paper, feels remarkably like building a house of cards. They strive for deterministic execution and reproducibility with R-LAM, attempting to tame the chaos inherent in complex systems. It’s a noble effort, but one suspects the first production run will expose unforeseen edge cases. As Andrey Kolmogorov observed, “The most important thing in science is not to be afraid to make mistakes.” They’ll call it AI and raise funding, of course, but the inevitable discrepancies between theory and reality will quickly accumulate. It used to be a simple bash script, now it’s a ‘Large Action Model’ and someone will inevitably blame the provenance tracking when it breaks. The documentation lied again.
What’s Next?
The pursuit of deterministic execution in scientific workflows, as exemplified by R-LAM, feels… familiar. It recalls a time when perfectly defined inputs were considered sufficient for reliable outputs, before the world embraced emergent behavior and ‘self-healing’ systems. This framework diligently addresses reproducibility, but one suspects production environments will swiftly reveal edge cases where the constraints themselves introduce novel failures. The devil, predictably, will be in the action-level details.
Future work will inevitably focus on scaling these constraints – and the computational cost of enforcing them – to workflows of truly significant complexity. The question isn’t whether the system can guarantee reproducibility, but whether the performance penalty makes it practical. There’s a looming trade-off between verifiable results and timely discovery, and it’s a trade-off that rarely favors rigor.
Ultimately, R-LAM appears to be a sophisticated attempt to impose order on a fundamentally chaotic process. It’s a laudable goal, certainly, and one that will likely offer temporary respite. But the history of automation suggests this is simply the old problem of state management, re-packaged with Large Action Models and worse documentation.
Original article: https://arxiv.org/pdf/2601.09749.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-17 23:54