Author: Denis Avetisyan
A new approach to autonomous machine learning agents tackles exceptionally long-term tasks by continuously refining its internal knowledge and capabilities.
This paper introduces ML-Master 2.0, an agent employing hierarchical cognitive caching to achieve ultra-long-horizon autonomy in machine learning engineering.
Achieving true scientific autonomy in artificial intelligence remains challenging due to limitations in sustaining strategic coherence over extended experimental cycles. This is addressed in ‘Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering’, which introduces ML-Master 2.0-an agent employing Hierarchical Cognitive Caching to effectively manage and evolve its cognitive state for ultra-long-horizon machine learning engineering tasks. Demonstrating a state-of-the-art medal rate on OpenAI’s MLE-Bench, our results suggest that decoupling immediate execution from long-term strategy is key to scalable autonomous scientific exploration. Could this approach unlock AI’s potential to navigate complexities beyond current human capabilities?
The Illusion of Long-Term Planning
Conventional machine learning agents often falter when faced with tasks demanding long-term strategic planning. These systems typically excel at identifying patterns within limited datasets or reacting to immediate stimuli, but struggle to maintain a cohesive strategy over extended periods. The root of this difficulty lies in their reliance on fixed-context learning; each decision is based on a snapshot of the current state, without effectively retaining and applying lessons learned from distant past experiences. Consequently, these agents exhibit a limited capacity for anticipating future consequences and adapting to evolving circumstances, hindering their performance in complex, dynamic environments where sustained coherence is paramount. This presents a significant challenge for applications requiring proactive, goal-oriented behavior over timescales exceeding those typically addressed by current machine learning paradigms.
Fixed-context models, prevalent in traditional machine learning, operate with a limited ‘memory’ of past experiences, fundamentally restricting their ability to extract enduring lessons from complex interactions. These models typically process information within a defined window, discarding valuable historical data that could reveal subtle patterns and long-term consequences. Consequently, distilling experience into genuinely actionable knowledge proves challenging; the agent struggles to generalize beyond the immediate context, leading to suboptimal decisions when faced with evolving circumstances or delayed rewards. This limitation contrasts sharply with human cognition, where the capacity for cumulative learning – building upon past successes and failures – is central to effective adaptation and strategic planning. The inability to effectively compress and utilize extended histories therefore represents a significant hurdle in developing truly intelligent agents capable of navigating dynamic, real-world scenarios.
The limitations of current artificial intelligence systems in tackling long-term challenges necessitate a shift towards agents capable of continuous learning and adaptation. Unlike traditional models with fixed memories, these advanced agents aim to emulate the human capacity for distilling experience into evolving strategies. This involves not simply memorizing past events, but building an internal representation of the world that allows for flexible responses to unforeseen circumstances and sustained coherence across extended periods. Such systems would require the ability to identify relevant patterns, generalize from limited data, and refine their understanding over time – effectively building a knowledge base that grows and adapts alongside the complexity of the environment, mirroring the plasticity of human cognition and paving the way for truly intelligent, long-term problem-solving.
Hierarchical Caching: A Band-Aid on the Problem
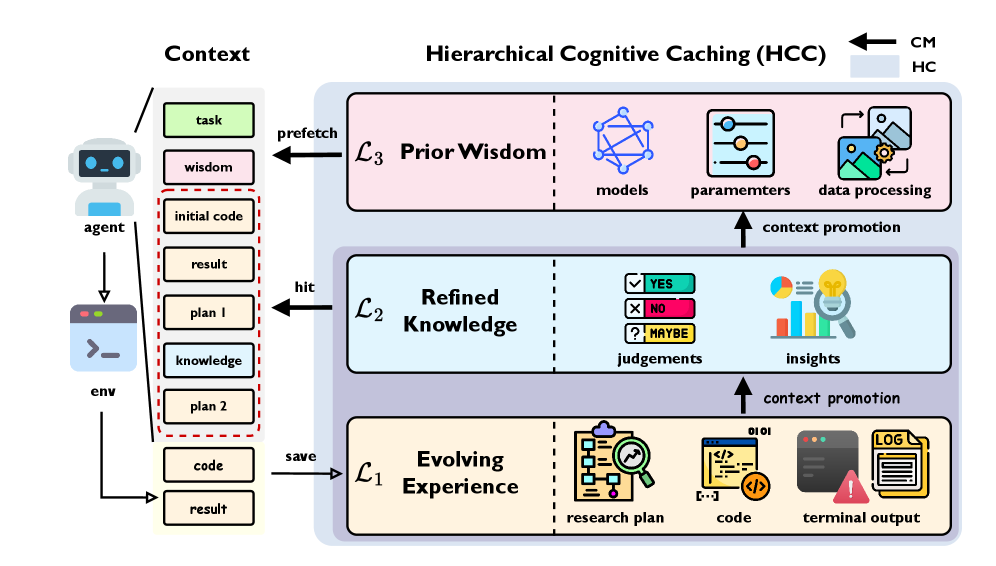
ML-Master 2.0 utilizes Hierarchical Cognitive Caching (HCC) as its primary mechanism for contextual management. HCC achieves this by structuring information across varying levels of abstraction – from concrete, immediate experiences to generalized, long-term knowledge. Simultaneously, HCC incorporates temporal resolution, allowing the system to differentiate between recent, highly relevant data and older, potentially less critical information. This tiered approach enables dynamic prioritization; the agent can rapidly access and utilize short-term contextual data while also retaining and applying previously learned insights for broader reasoning and strategic planning. The system’s ability to manage context in both abstract and temporal dimensions is fundamental to its performance in complex, extended tasks.
Hierarchical Cognitive Caching (HCC) within ML-Master 2.0 is structured around three distinct caches operating at different levels of abstraction and retention. The Level 1 (L1) cache, termed the Evolving Experience Cache, functions as a short-term buffer for raw sensory input and immediate reasoning processes, prioritizing rapidly changing data. The Level 2 (L2) cache, the Refined Knowledge Cache, stores consolidated and stabilized insights derived from L1, representing knowledge that has undergone initial validation and filtering. Finally, the Level 3 (L3) cache, the Prior Wisdom Cache, holds long-term, transferable strategies and generalized knowledge extracted from L2, enabling the agent to apply past experiences to novel situations and facilitate continual learning.
The tiered caching system within ML-Master 2.0 facilitates dynamic information prioritization by assigning different retention policies to each cache level. The Evolving Experience Cache (L1) provides rapid access to immediate sensory data, prioritizing recent events; the Refined Knowledge Cache (L2) stores generalized rules and patterns derived from L1, emphasizing stabilized, frequently accessed information; and the Prior Wisdom Cache (L3) maintains long-term strategies and abstract principles, retaining knowledge across extended periods and diverse contexts. This hierarchical structure enables the agent to selectively retain and retrieve information based on its relevance and temporal distance, improving learning efficiency and adaptive capacity over prolonged interactions and complex scenarios.
Context Migration: Shuffling the Deck
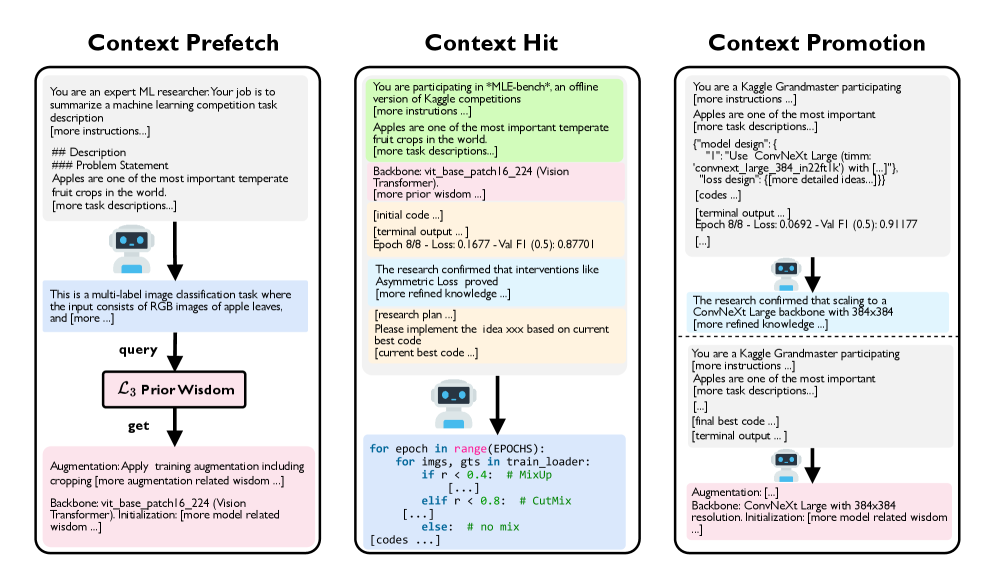
Context Migration within the Hierarchical Cache Controller (HCC) manages the transfer of information between the L1, L2, and L3 caches. This process isn’t a simple copy operation; rather, it involves analyzing data relevance and prioritizing information transfer based on access patterns and predictive algorithms. The L1 cache, being the fastest but smallest, receives frequently accessed data. Less frequently used, but still relevant, data is moved to the larger, slower L2 cache. The L3 cache serves as a final repository for data with lower immediate access priority, ensuring data persistence without occupying the faster cache levels. Efficient context migration minimizes data redundancy across the hierarchy and reduces access latency by proactively positioning necessary information closer to the processing core.
Context Promotion is the mechanism by which Hierarchical Context Compression (HCC) transforms unprocessed data into actionable intelligence. Raw data, initially captured during exploration, undergoes a series of refinements. This involves identifying patterns, extracting key insights, and generalizing findings to create knowledge. Subsequently, this knowledge is further distilled into reusable wisdom – abstract principles and strategies applicable across multiple contexts. The process isn’t simply data storage; it’s an active refinement, prioritizing information based on relevance and potential for future application, enabling efficient knowledge transfer and utilization within the HCC framework.
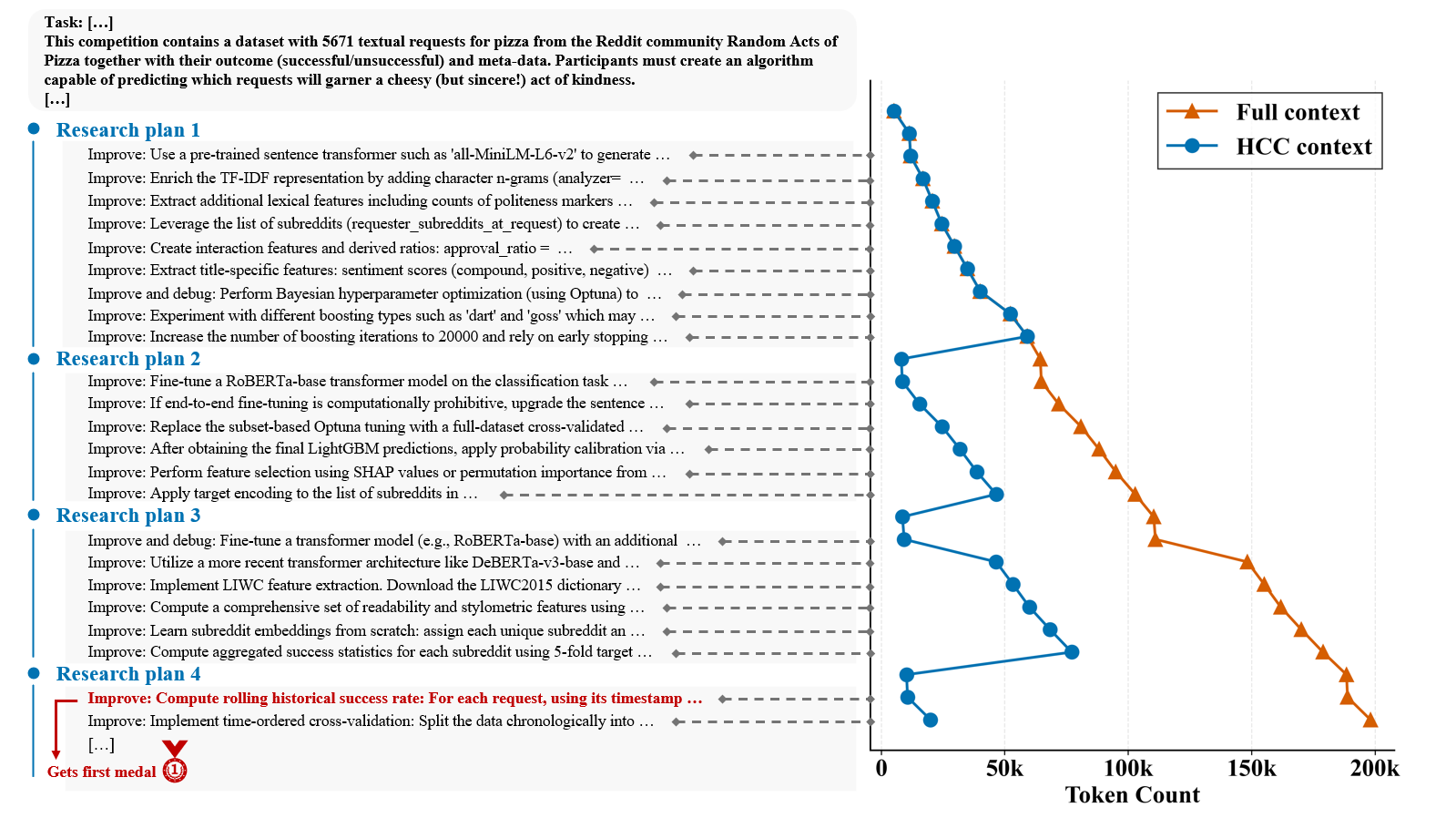
Phase-Level Context Promotion is a targeted implementation of the overall Context Migration system, operating specifically at the conclusion of each exploration phase within the Hierarchical Context Cache (HCC). This process refines accumulated data from the L1 and L2 caches by consolidating it into higher-level knowledge representations suitable for storage in the L3 cache. By performing this distillation at phase boundaries, the system minimizes the propagation of irrelevant or redundant information, thereby optimizing the efficiency of knowledge transfer and reducing the computational load associated with subsequent exploration phases. This targeted approach ensures that only refined and reusable wisdom is promoted to the L3 cache, maximizing its utility for future decision-making processes.
MLE-Bench: A Statistical Blip
To rigorously assess its capabilities, ML-Master 2.0 underwent evaluation on MLE-Bench, a challenging and diverse benchmark constructed from 75 actual machine learning competitions hosted on Kaggle. This benchmark isn’t comprised of synthetic datasets; instead, it presents the agent with the complexities and nuances of real-world data science problems, encompassing a wide range of tasks and evaluation metrics. By testing on previously-completed competitions, MLE-Bench offers a standardized and objective measure of performance, allowing for direct comparison against existing methods and providing a robust indication of the agent’s ability to generalize to unseen, practical challenges. The breadth of competitions within MLE-Bench ensures that the evaluation isn’t skewed towards a specific type of machine learning problem, offering a comprehensive assessment of the agent’s overall proficiency.
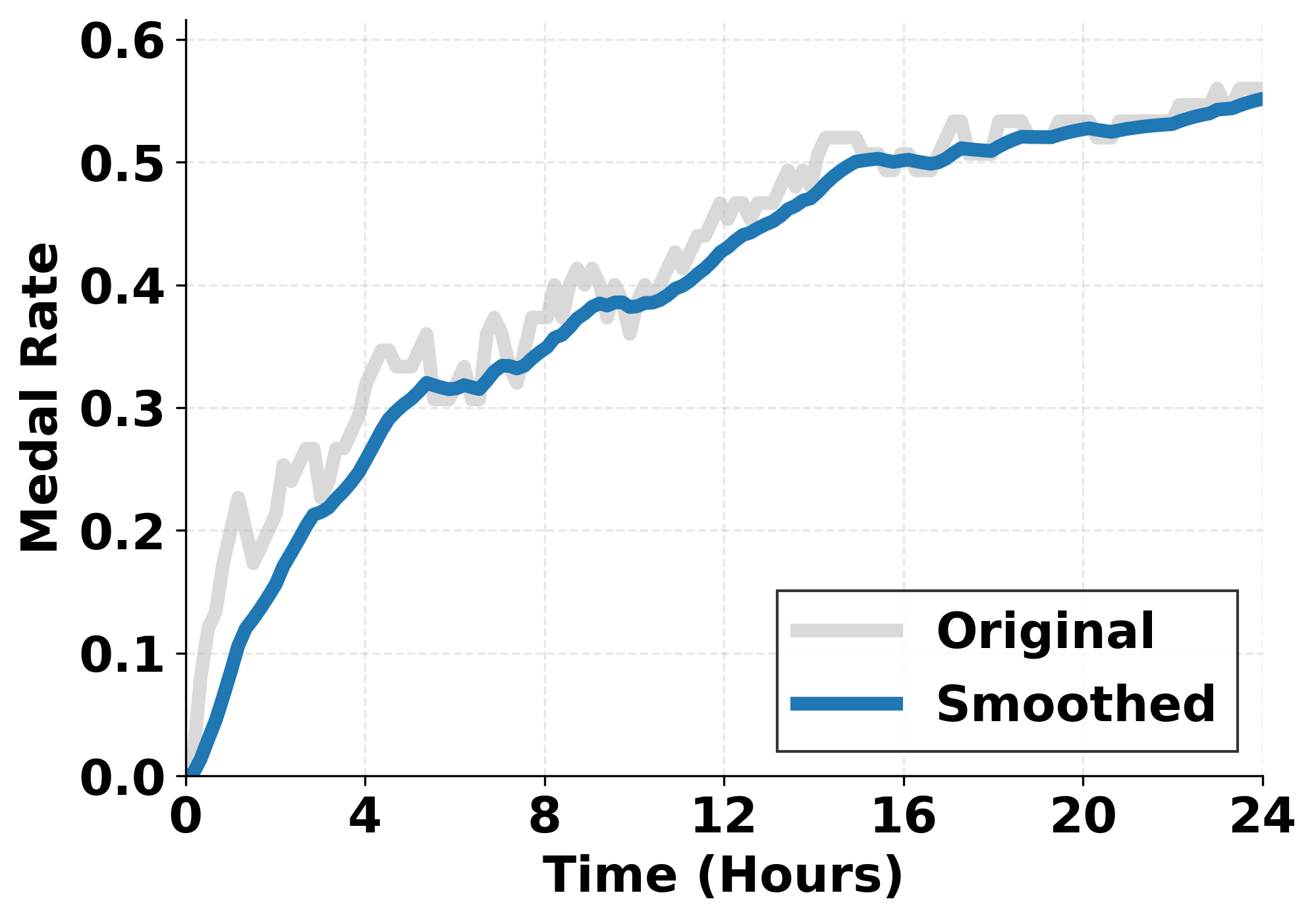
Evaluations on the challenging MLE-Bench benchmark reveal that the agent exhibits markedly improved performance and strategic planning capabilities when compared to existing machine learning models. Achieving a state-of-the-art average medal rate of 56.44% across 75 real-world Kaggle competitions, the agent consistently demonstrates a capacity for sustained success. This isn’t merely about isolated wins; the agent maintains high performance over extended evaluation periods, indicating a robust and reliable approach to complex machine learning tasks. The achieved medal rate represents a substantial advancement, highlighting the agent’s ability to not only participate effectively in competitions but to consistently rank among the top performers.
The latest iteration of the machine learning agent demonstrated substantial advancements in predictive modeling, achieving a 92.7% relative improvement over its predecessor, ML-Master. This progress isn’t limited to easier problems; the agent consistently outperformed existing methods across the entirety of MLE-Bench, securing the top rank in competitions categorized by low, medium, and high complexity. This consistent success indicates a robust ability to generalize learned strategies and adapt to diverse datasets, marking a leap towards truly autonomous machine learning and a capacity to tackle increasingly challenging real-world predictive tasks.
The robust performance of ML-Master 2.0 extends beyond simply achieving high ranks; the agent demonstrates a remarkable ability to reliably produce valid solutions, attaining a 95.6% valid submission rate – a metric comparable to leading methodologies. Critically, the agent surpassed the performance of over half of human participants in 63.1% of the tasks within the benchmark, representing the highest such proportion achieved by any tested method. This suggests not only a capacity for sophisticated problem-solving but also a level of consistency and practical application that approaches, and in many instances exceeds, human expertise in real-world machine learning challenges.
The Illusion of Progress
The pursuit of Ultra-Long-Horizon Autonomy hinges significantly on a principle called Cognitive Accumulation – the dynamic evolution of an agent’s contextual understanding over extended periods. Unlike systems with static knowledge bases, agents capable of cognitive accumulation don’t simply recall information; they continuously refine it, integrating new experiences and observations to reshape their internal representation of the world. This isn’t merely about storing more data, but about building a progressively more nuanced and accurate model of complex environments. Through this ongoing process, an agent moves beyond reactive responses to proactive anticipation, enabling it to navigate unforeseen challenges and achieve goals that demand sustained, intelligent behavior over potentially limitless timescales. The ability to build upon past knowledge, correct errors, and adapt strategies effectively defines the core of truly autonomous intelligence, moving beyond narrow task completion toward genuine, long-term problem-solving capabilities.
The capacity for agents to continuously refine their knowledge hinges on effective context management and the implementation of Hierarchical Compositional Caching (HCC). This allows systems to not simply store information, but to dynamically build and reorganize it, creating a layered understanding of the world that evolves with each interaction. Robust context management ensures that relevant past experiences are readily accessible, enabling agents to interpret new information within a broader, accumulated framework. Consequently, agents equipped with these capabilities demonstrate markedly improved adaptability; they aren’t simply reacting to stimuli, but proactively adjusting their strategies and predictions based on a continuously updated internal model of the environment, paving the way for truly autonomous behavior in complex and ever-changing scenarios.
ML-Master 2.0’s progression isn’t left to chance; it operates under the direction of a carefully constructed Research Plan. This plan functions as a dynamic curriculum, strategically sequencing complex machine learning tasks to build increasingly sophisticated capabilities. Rather than randomly exploring the vast landscape of algorithms and datasets, the agent prioritizes challenges that demonstrably expand its existing skillset, fostering a process of continuous refinement. By meticulously charting a course through problem spaces, the Research Plan optimizes learning efficiency, allowing ML-Master 2.0 to tackle more intricate problems with greater success, and ultimately, pushing the boundaries of what’s achievable in artificial intelligence.
The pursuit of ultra-long-horizon autonomy, as demonstrated by ML-Master 2.0, inevitably invites a cascade of technical debt. The system’s reliance on Hierarchical Cognitive Caching, while elegantly addressing the challenge of maintaining a cognitive state over extended periods, is merely delaying the inevitable entropy. Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This sentiment applies perfectly; each layer of abstraction added to manage complexity creates another point of failure. The elegance of the design will ultimately be tested-and likely broken-by the sheer unpredictability of production environments. Documentation, of course, remains a myth.
What Lies Ahead?
ML-Master 2.0, with its hierarchical caching, attempts to address the practical entropy of extended machine learning tasks. The system’s performance will, predictably, be the first casualty of deployment. Tests are, after all, a form of faith, not certainty. The real challenge isn’t building a system that can accumulate knowledge over time, but one that degrades gracefully – and doesn’t rewrite core functions based on spurious correlations unearthed from months-old data.
The notion of ‘cognitive accumulation’ itself feels… optimistic. It assumes a relatively stable problem space. Production environments rarely cooperate. The next iteration will likely focus less on elegant architectures and more on robust failure modes – a means of isolating and discarding corrupted ‘memories’ before they trigger cascading errors. Perhaps a dedicated ‘forgetting’ module, ironically, will prove more valuable than further refinement of the caching mechanism.
The pursuit of ultra-long-horizon autonomy is, at its core, a search for predictable unpredictability. Automation will not ‘save’ anyone; it will simply create new, more subtle failure states. The true metric of success won’t be achieving a goal after months of operation, but minimizing the damage incurred along the way. The system that crashes least badly on Mondays will ultimately be the most valuable.
Original article: https://arxiv.org/pdf/2601.10402.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- How to find the Roaming Oak Tree in Heartopia
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- ATHENA: Blood Twins Hero Tier List
2026-01-17 10:20