Author: Denis Avetisyan
Researchers have developed a new modular agent, M3Searcher, designed to gather and reason about information online with improved flexibility and accuracy.
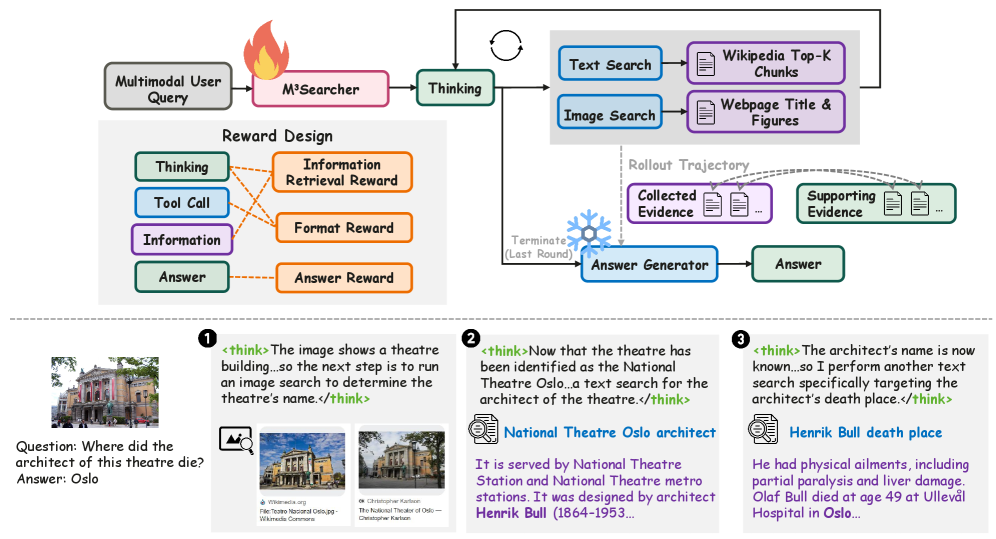
M3Searcher decouples information retrieval from answer generation, leveraging reinforcement learning and multimodal inputs for enhanced web-based information seeking.
While recent advances in autonomous agents have shown promise in web-based information gathering, they largely remain limited to text-based modalities. This work introduces ‘M$^3$Searcher: Modular Multimodal Information Seeking Agency with Retrieval-Oriented Reasoning’, a novel agent designed to overcome this limitation through a modular architecture that explicitly separates information acquisition from answer derivation. By optimizing for both factual accuracy and retrieval fidelity, M$^3$Searcher demonstrates improved reasoning and adaptability in complex multimodal tasks, alongside a new multimodal multi-hop dataset for reinforcement learning. Could this decoupling of retrieval and reasoning unlock more robust and versatile information-seeking agents capable of navigating the increasingly complex digital landscape?
The Limits of Synthesis: Why Scale Demands a New Approach
Conventional information retrieval systems frequently encounter limitations when faced with queries demanding complex, multi-hop reasoning. These systems typically excel at identifying documents containing keywords, but struggle to synthesize information scattered across multiple sources to arrive at a logical conclusion. This necessitates extensive data processing – a computationally intensive process where algorithms must traverse vast datasets, identify relevant connections, and infer relationships between disparate pieces of information. The challenge arises from the need to not only locate facts, but to understand their context and combine them in a meaningful way, a task that quickly becomes unwieldy as the number of required reasoning steps increases. Consequently, answering seemingly simple questions that require connecting several facts often demands significant computational resources and time, hindering real-time responsiveness and scalability.
Contemporary artificial intelligence systems often encounter limitations when tasked with synthesizing information presented across different formats-text, images, audio, and video-a challenge known as multi-modal integration. While individual modalities can be processed with increasing sophistication, combining these diverse inputs remains a significant hurdle. The difficulty stems from the inherent differences in how each modality is represented and the complexities of establishing meaningful connections between them. Consequently, systems struggle to build a cohesive understanding, leading to inaccuracies and a restricted ability to tackle complex reasoning tasks that require drawing inferences from multiple sources of information. This constraint ultimately diminishes the scope of solvable problems and hinders the development of truly comprehensive artificial intelligence.
Decoupling the Cognitive Ecosystem: An Agentic Architecture
M3Searcher’s architecture fundamentally separates the processes of information retrieval and reasoning into distinct modules. This decoupling allows for independent optimization of each function; retrieval tools can be updated or specialized without impacting the reasoning engine, and vice-versa. This modularity increases system flexibility, enabling the integration of diverse retrieval methods – including vector databases, web search APIs, and specialized knowledge sources – tailored to specific query types. Furthermore, by prioritizing retrieval as a separate step, the system minimizes the computational load on the reasoning component, leading to increased efficiency and scalability in complex analytical tasks.
The M3Searcher architecture utilizes a Decoupled Agentic MRAG (Multi-modal Reasoning Agent Group) framework to facilitate independent operation of specialized search tools. This decoupling allows for dedicated agents focused on either text or image retrieval, each employing optimized search methodologies without being constrained by the processing requirements of the other. These agents function concurrently, acquiring relevant information from their respective modalities, and then contribute their findings to a central reasoning engine. This modular approach enhances efficiency by enabling parallel processing and allows for the seamless integration of new or improved search tools without requiring modifications to the core reasoning components.
Retrieval-Oriented Reasoning forms the foundational principle of the M3Searcher architecture, emphasizing information acquisition as a primary step preceding analytical processing. This approach dictates that the system first focuses on identifying and extracting relevant data from various sources-text and images-before attempting to synthesize or interpret that information. By prioritizing retrieval, the system aims to reduce the computational burden of analysis and improve the accuracy of conclusions, as the reasoning engine operates on a focused and validated dataset. This contrasts with systems that integrate retrieval and reasoning, potentially leading to analysis based on incomplete or irrelevant information.
Learning to Seek: Reinforcement Learning for Adaptive Information Gathering
M3Searcher employs Reinforcement Learning (RL) to enhance its information seeking process by dynamically adjusting search strategies based on feedback. The system learns to identify and prioritize information sources deemed most relevant to the query, subsequently improving the accuracy of its reasoning. This is achieved through iterative training where the agent receives rewards for successful information retrieval and accurate conclusions, allowing it to refine its policy over time. The RL framework enables M3Searcher to move beyond static search algorithms and adapt to the nuances of complex information landscapes, ultimately optimizing for both the quality and utility of the retrieved data.
The M3Searcher employs a multi-objective reward modeling scheme to train its information seeking agent, utilizing a Large Language Model (LLM) functioning as a judge to assess search performance. This scheme moves beyond single-metric optimization by simultaneously evaluating accuracy, completeness, and relevance of retrieved information. The LLM-as-Judge provides scalar rewards for each objective, which are then combined to form a composite reward signal. This allows the agent to learn policies that effectively balance these competing objectives, preventing over-optimization for one metric at the expense of others, and ultimately improving the overall quality of information seeking.
Group-Relative Policy Optimization (GRPO) addresses the challenge of efficiently updating the agent’s policy in a multi-agent reinforcement learning environment. Traditional policy gradient methods can suffer from high variance and slow convergence, particularly when dealing with complex search spaces. GRPO mitigates this by grouping similar states together and optimizing the policy based on the aggregated rewards from these groups. This reduces the variance of the policy gradient estimates, leading to faster and more stable learning. Specifically, GRPO calculates the policy update based on the average reward received by a group of states, effectively smoothing the learning signal and accelerating adaptation of the agent’s information seeking strategies.

Validating the Ecosystem: Data and Tool Integration for Rigorous Evaluation
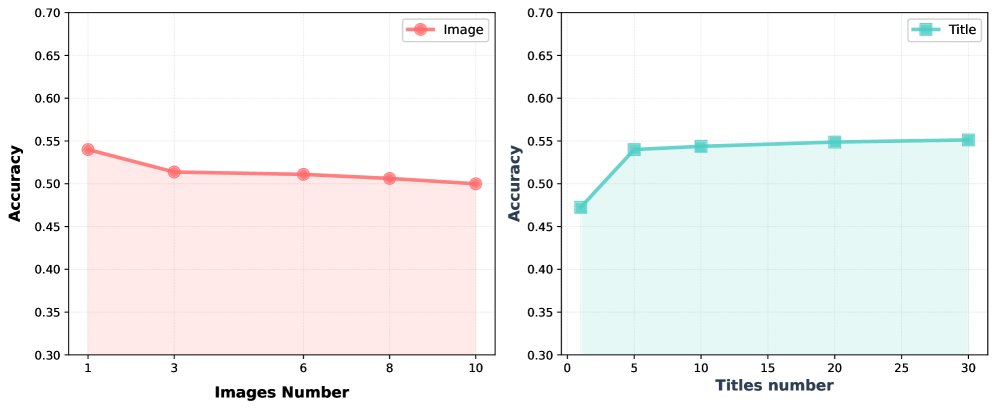
M3Searcher utilizes a modular architecture incorporating dedicated tools for text and image retrieval to enhance information gathering. The ‘Text Search Tool’ employs ‘E5 Models’, a class of embedding models designed for semantic similarity search, enabling the identification of relevant textual content. Complementing this, the ‘Image Search Tool’ leverages the ‘Serper API’ to access and process image data based on query parameters. This integration of specialized tools allows M3Searcher to perform comprehensive searches across multiple data modalities, facilitating a more complete understanding of the information landscape.
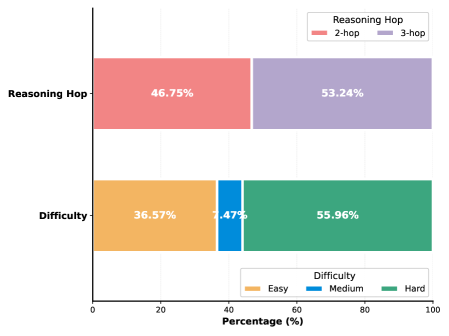
MMSearchVQA is a newly constructed dataset used for rigorous performance evaluation, comprising 6,000 question-answer pairs. The dataset is built upon the established ‘ReasonVQA’ framework, providing a foundation for complex reasoning challenges. Critically, MMSearchVQA integrates information derived from the ‘Wikidata’ knowledge graph, enabling questions that require accessing and synthesizing structured knowledge. The dataset’s construction specifically targets scenarios necessitating at least two reasoning hops to arrive at the correct answer, demanding multi-step inference capabilities from evaluated systems.
M3Searcher is designed to address complex question answering scenarios that necessitate the combination of information retrieved from diverse sources. Evaluation on the MMSearchVQA dataset confirms this capability; the dataset comprises 6,000 questions constructed using the ReasonVQA framework and Wikidata, and is specifically engineered to require a minimum of two reasoning hops to arrive at the correct answer. This design ensures that the system must not only locate relevant information but also synthesize it through multiple inferential steps, demonstrating a capacity for multi-hop reasoning and knowledge integration.
Beyond the Horizon: Towards Agents That Grow, Not Just Respond
The architecture of M3Searcher is fundamentally designed for extensibility, enabling the seamless incorporation of novel tools and data types without requiring substantial systemic overhauls. This modularity isn’t merely about adding features; it facilitates a dynamic expansion of the agent’s cognitive toolkit. New functionalities, such as specialized search engines, knowledge bases, or even entirely different sensory modalities – like audio or visual input – can be integrated as independent modules. This plug-and-play approach not only accelerates development but also promotes robustness; a failure in one module doesn’t necessarily compromise the entire system. Consequently, M3Searcher demonstrates a significant step toward creating adaptable reasoning agents capable of operating effectively in ever-changing and increasingly complex environments, promising a future where AI can readily assimilate new information and skills.
M3Searcher’s architecture fundamentally leverages reinforcement learning, enabling a process of continuous refinement beyond initial training. This approach allows the system to dynamically adapt its reasoning strategies based on feedback received from interactions with various data sources and problem-solving attempts. Unlike systems with fixed algorithms, M3Searcher actively learns which tools and reasoning paths are most effective in different contexts, improving performance over time without explicit reprogramming. The capacity to ingest and learn from diverse data-ranging from structured knowledge bases to unstructured text and even observational data-is central to this ongoing improvement, allowing the system to generalize its reasoning abilities and tackle increasingly complex challenges. This iterative learning process positions M3Searcher as a potentially scalable solution for building agents capable of autonomous knowledge acquisition and problem-solving.
The development of M3Searcher signifies progress toward artificial general intelligence, moving beyond narrow task-specific systems. This research demonstrates a pathway for creating agents capable of not just processing information, but actively reasoning about it to solve multifaceted challenges. The system’s architecture suggests potential applications extending far beyond its current capabilities, hinting at future agents that could autonomously contribute to scientific discovery by formulating hypotheses and analyzing data, or synthesize knowledge from disparate sources to address complex inquiries. Ultimately, this work proposes a framework for building systems that don’t simply react to problems, but proactively engage with them, mirroring-and potentially augmenting-human cognitive abilities in domains demanding nuanced understanding and creative problem-solving.
The pursuit of adaptable information systems, as demonstrated by M3Searcher’s modular architecture, mirrors a fundamental truth: rigid structures inevitably succumb to entropy. The system’s decoupling of retrieval from generation isn’t a solution, but an acceptance of inherent instability. As Tim Bern-Lee observed, “The Web is more a social creation than a technical one.” This resonates deeply with the agent’s design; it doesn’t build a definitive answer, but grows one from the chaotic abundance of web data. Stability, in this context, is merely an illusion that caches well, a temporary reprieve from the inevitable shift in information landscapes. The agent acknowledges that chaos isn’t failure – it’s nature’s syntax, and M3Searcher navigates it with calculated, modular grace.
What Lies Ahead?
M$^3$Searcher, with its deliberate decoupling, feels less like a solution and more like a carefully charted acceptance of inevitable decay. The architecture doesn’t solve the problem of brittle knowledge; it anticipates the moment the knowledge inevitably becomes outdated and provides a framework for localized failure. This is, perhaps, a more honest approach than striving for monolithic, perpetually-updated systems. The question now isn’t how to build a perfect agent, but how to cultivate an ecosystem where these modules can be replaced, retrained, or allowed to wither gracefully.
The true challenge isn’t merely improving retrieval-augmented generation, but acknowledging its fundamental limitation: information on the web is not a stable resource. Every query is an archaeological dig, every answer a temporary reconstruction. Future work will likely focus not on scaling these agents, but on developing methods for assessing and communicating the confidence in retrieved information – a sort of ‘half-life’ indicator for web facts.
One wonders if the pursuit of generalizable information-seeking agents is a fool’s errand. Perhaps specialization-agents meticulously crafted for narrow domains-will prove more resilient. Or, more likely, the field will continue to iterate on modularity, creating ever more fragmented systems, each a small, self-contained apocalypse waiting to happen. No one writes prophecies after they come true, of course.
Original article: https://arxiv.org/pdf/2601.09278.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Clash Royale Furnace Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- What If Spider-Man Was a Pirate?
2026-01-16 02:25