Author: Denis Avetisyan
Researchers have developed an automated system to build complex research tasks and rigorously assess the factual accuracy and quality of reports generated by artificial intelligence agents.
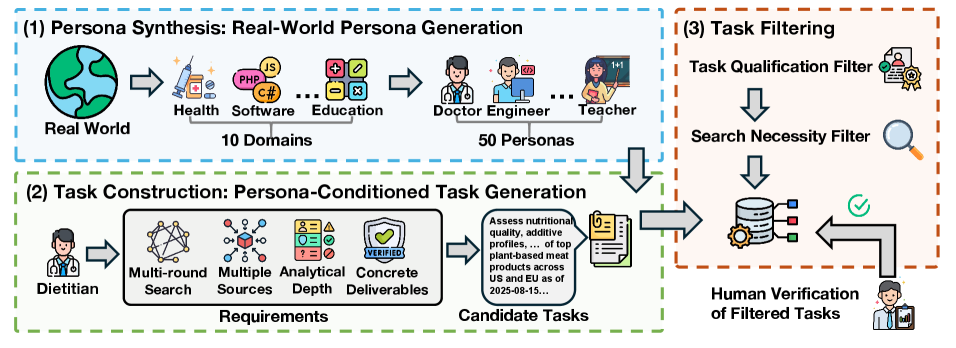
DeepResearchEval provides a comprehensive solution for evaluating long-form report generation by agentic systems, addressing key limitations in current benchmarks.
Despite the increasing prevalence of systems designed for complex web-based research, robust and reliable evaluation remains a significant challenge. This paper introduces DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation, a novel approach to automatically generating challenging research tasks and assessing the quality and factual accuracy of resulting reports. The framework leverages persona-driven task creation with rigorous filtering, coupled with an agentic evaluation pipeline featuring dynamic, task-specific criteria and autonomous fact-checking-even in the absence of explicit citations. Will this automated approach unlock more trustworthy and insightful deep research capabilities in increasingly sophisticated agentic systems?
The Limits of Statistical Proficiency in Deep Inquiry
While Large Language Models demonstrate remarkable proficiency in tasks like text generation and translation, deep research presents a unique challenge that exposes limitations in their core architecture. These models often succeed by identifying patterns and statistical relationships within their training data, but genuine research demands more than pattern recognition; it necessitates complex, multi-stage reasoning – formulating hypotheses, designing investigations, critically evaluating evidence, and synthesizing findings. LLMs frequently falter when faced with tasks requiring prolonged chains of inference, external knowledge integration, and the ability to discern credible information from noise. This isn’t simply a matter of scale; even the most powerful LLMs struggle with the nuanced cognitive processes inherent in truly deep exploration of a subject, highlighting a fundamental gap between statistical proficiency and genuine understanding.
Current large language models, despite their impressive capabilities, face fundamental limitations when confronted with deep research challenges. Simply increasing the size of these models – a common strategy for improvement – yields diminishing returns when tasks demand more than pattern recognition. True deep research necessitates the integration of external knowledge sources and, crucially, the ability to critically verify information – processes that existing LLMs struggle to perform reliably. A paradigm shift is therefore required, moving beyond mere scaling to explore architectures and methodologies that explicitly incorporate knowledge retrieval, reasoning, and validation mechanisms. This involves developing systems capable of not just generating text, but of actively seeking, assessing, and synthesizing information from diverse and authoritative sources, ultimately bridging the gap between statistical language proficiency and genuine understanding.
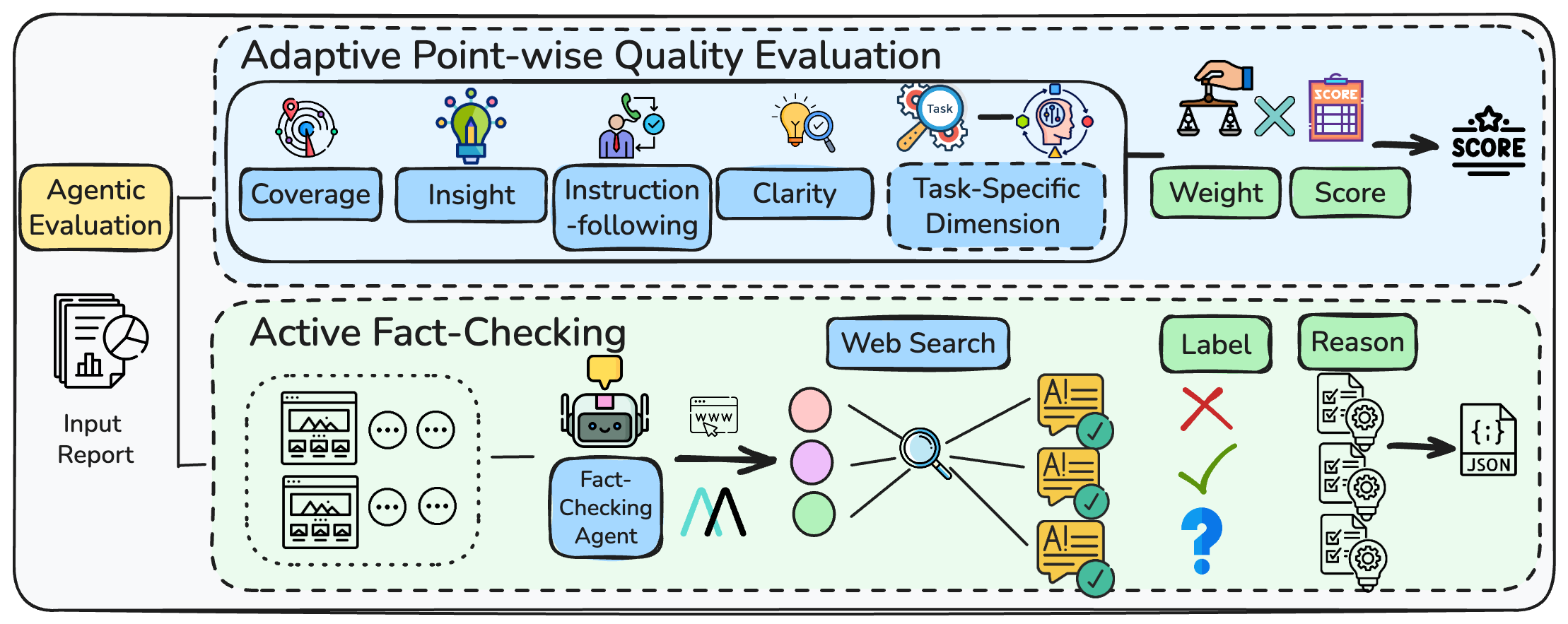
DeepResearchEval: A Framework for Rigorous Investigative Assessment
DeepResearchEval is an automated framework designed to facilitate the creation of complex research tasks and the subsequent evaluation of reports generated in response to those tasks. The system automates the process of task instantiation, removing the need for manual construction of research prompts and associated evaluation criteria. This automation allows for scalable and repeatable assessments of information-seeking behavior and report quality. The framework’s architecture supports the generation of tasks requiring investigation across multiple sources and the objective measurement of the completeness, accuracy, and relevance of resulting reports, thereby enabling rigorous analysis of research capabilities.
Persona-Driven Task Construction within DeepResearchEval involves formulating research tasks around detailed user personas, each possessing specific information needs, backgrounds, and goals. These personas drive the creation of scenarios requiring investigation to satisfy their defined objectives, moving beyond simple fact retrieval. The system generates tasks that necessitate synthesizing information from multiple sources to address complex queries that a single source cannot resolve. This approach ensures the generated tasks aren’t artificially simple and instead mirror the complexities of real-world information seeking, demanding comprehensive research and analysis to formulate a complete response appropriate for the designated persona.
The DeepResearchEval framework employs a Task Qualification Filter to refine the initial task pool from 200 candidates down to a focused set of 100. This filtering process is specifically designed to prioritize tasks that inherently require external evidence for resolution and necessitate the integration of information from multiple sources. Tasks failing to meet these criteria – those solvable with readily available internal knowledge or single-source information – are excluded, ensuring the retained tasks accurately assess a system’s ability to perform comprehensive, multi-faceted research and synthesize information effectively.
Beyond Simple Metrics: Evaluating the Nuances of Deep Research
Adaptive Point-wise Quality Evaluation moves beyond single-score assessments by employing a multi-dimensional approach to determine research quality. This method combines general dimensions – such as clarity, coherence, and methodology soundness – with task-specific criteria relevant to the research’s objectives. Scoring is performed on a point-wise basis, allowing for granular feedback and identification of specific strengths and weaknesses. The integration of both general and task-specific dimensions ensures a holistic assessment, capturing nuances often missed by simpler metrics and providing a more comprehensive evaluation of the research’s overall quality and contribution.
Active fact-checking involves the automated extraction of discrete, verifiable statements from generated text. This process is followed by the retrieval of supporting or contradictory evidence from external knowledge sources, such as web pages or structured databases. The retrieved evidence is then used to assess the factual correctness of each statement, providing a granular evaluation beyond simple overall metrics. This approach focuses on identifying and validating individual claims, rather than relying on holistic assessments of text quality, and enables a more precise determination of factual accuracy.
The Agentic Evaluation Pipeline automates research assessment by integrating adaptive quality evaluation and active fact-checking techniques. This pipeline utilizes autonomous agents to perform evaluations, facilitating a standardized and reproducible process. Performance metrics demonstrate a 73% agreement rate between the automated fact-checking results generated by the pipeline and corresponding human annotations, indicating a high degree of correlation and validating the pipeline’s effectiveness in mimicking human judgment regarding factual accuracy and overall quality.
Expanding the Boundaries of Knowledge: Automated Systems and the Pursuit of Verifiable Truth
Deep Research Systems are fundamentally assessed by two crucial metrics: report quality and factual correctness. These aren’t simply about generating text; the systems must demonstrate a capacity for thorough, well-structured reasoning and verifiable accuracy. Report quality encompasses elements like coherence, clarity, and the logical flow of arguments, ensuring the presented information is easily understandable and effectively communicated. Simultaneously, factual correctness demands that all claims are supported by credible evidence and accurately reflect established knowledge. The interplay between these two indicators – a compellingly written report built upon a foundation of truth – defines the efficacy of these automated research tools, pushing the boundaries of what’s possible in automated knowledge synthesis and evaluation.
Automated deep research systems are no longer confined to static datasets; instead, they actively leverage web browsing capabilities to dynamically gather and synthesize external evidence. This allows these systems to move beyond pre-existing knowledge and access the most current information available online, significantly enhancing the comprehensiveness and timeliness of their insights. By autonomously exploring the web, these systems can corroborate findings, identify emerging trends, and incorporate diverse perspectives, ultimately producing reports grounded in a continually updated understanding of the subject matter. This dynamic information gathering process is crucial for tackling rapidly evolving fields and ensures that research outputs remain relevant and reliable, offering a substantial advantage over traditional, static research methods.
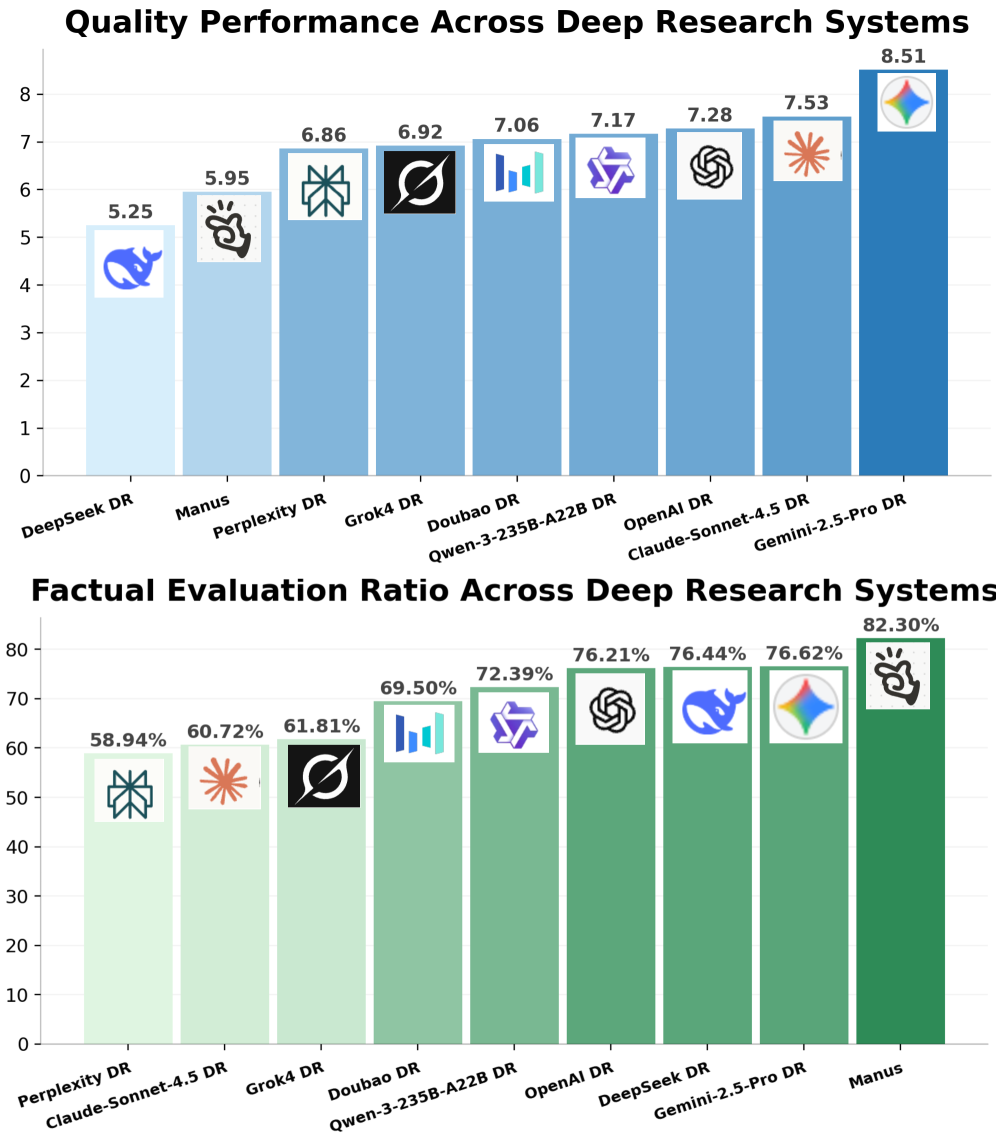
Automated evaluation represents a significant leap in the capacity to rigorously assess complex research reports. Utilizing models like Gemini-2.5-Pro, these systems move beyond manual review, enabling the analysis of a substantial volume of information with consistent objectivity. Recent studies demonstrate Gemini-2.5-Pro’s ability to evaluate, on average, 86.99 statements within a single report, drastically increasing the scale of analysis possible. This automated approach not only enhances efficiency but also minimizes subjective biases inherent in human evaluation, paving the way for more dependable and reproducible research insights. The ability to consistently and comprehensively assess report quality at this scale promises to accelerate discovery and improve the overall trustworthiness of automated research systems.
The pursuit of robust evaluation, as exemplified by DeepResearchEval, echoes a fundamental principle of mathematical rigor. The framework doesn’t merely assess if an agentic system appears to function, but attempts to establish the invariant truths within its long-form reports-a crucial step towards reliable knowledge synthesis. As John McCarthy aptly stated, “It is better to have a small number of elegant solutions than many clumsy ones.” This sentiment underpins the entire approach; DeepResearchEval prioritizes a focused, automated methodology for factual verification, striving for an elegant solution to the complex problem of evaluating agentic research – a pursuit of provable correctness rather than superficial performance. The framework’s emphasis on constructing deep research tasks and verifying factual claims is a testament to this pursuit of mathematical purity in evaluation.
What’s Next?
The automation of deep research evaluation, as demonstrated by DeepResearchEval, represents a necessary, if belated, acknowledgement of the limitations inherent in purely empirical validation. The proliferation of large language models demands a shift from observing performance on curated datasets to proving the logical consistency and factual grounding of generated content. However, the framework itself merely addresses the symptom, not the disease. The fundamental challenge remains: how to codify ‘truth’ and ‘reason’ in a manner amenable to algorithmic scrutiny.
Future work must move beyond surface-level fact verification. Identifying factual inconsistencies is trivial; discerning subtle logical fallacies, nuanced misinterpretations, or the propagation of biases requires a far more sophisticated approach. The current reliance on LLMs to evaluate LLMs introduces a circularity that, while practical, lacks mathematical elegance. A truly robust system will necessitate the incorporation of formal methods – theorem proving, logical inference – to establish the validity of research claims independent of statistical correlation.
In the chaos of data, only mathematical discipline endures. While DeepResearchEval offers a valuable step towards automated assessment, the ultimate goal should not be to build better benchmarks, but to develop a formal language for expressing and verifying knowledge itself. The pursuit of artificial intelligence, it seems, will inevitably lead back to the ancient quest for logical certainty.
Original article: https://arxiv.org/pdf/2601.09688.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Clash Royale Furnace Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- Clash Royale Witch Evolution best decks guide
2026-01-15 21:29