Author: Denis Avetisyan
Researchers have developed a framework that blends geometric understanding with advanced neural networks, enabling humanoid robots to manipulate objects with greater accuracy and efficiency.
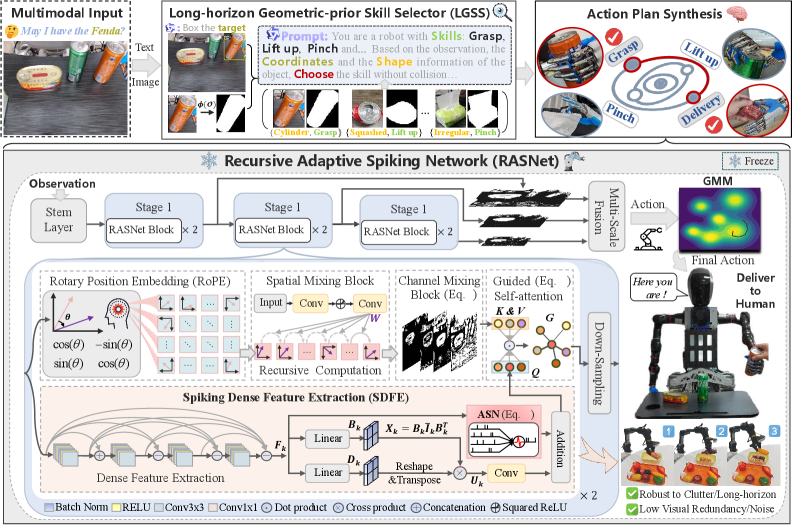
This work introduces RGMP-S, a system combining geometric priors and recurrent spiking neural networks for data-efficient robotic manipulation and improved spatial awareness.
Despite advancements in robotic manipulation, achieving both robust generalization and data efficiency remains a significant challenge for humanoid robots executing complex tasks. This paper introduces RGMP-S, a novel framework for ‘Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation’ that integrates geometric reasoning with spatiotemporal feature learning via spiking neural networks. By leveraging lightweight geometric priors within a vision-language model and employing a recursive adaptive spiking network, RGMP-S demonstrates superior performance across simulation and multiple real-world robotic platforms. Could this approach unlock more adaptable and resource-conscious humanoid robots capable of seamlessly interacting with complex environments?
Breaking the Static: The Limits of Pre-Programmed Control
Conventional robotic manipulation often demands an exhaustive understanding of the workspace before any physical interaction. Robots typically operate using meticulously crafted models of their surroundings and follow pre-defined movement plans, a strategy that proves brittle when faced with the unpredictable nature of real-world tasks. This reliance on precision necessitates significant upfront investment in environment mapping and programming, severely limiting a robot’s ability to adapt to even slight deviations from the expected. Consequently, these systems struggle with tasks requiring flexibility – picking up an object from a slightly different angle, navigating around an unexpected obstruction, or adjusting to variations in an object’s weight or texture – highlighting a critical need for more robust and adaptable approaches to robotic control.
Robotic manipulation, despite advances in precision, often falters when confronted with the unpredictable nature of real-world environments. Pre-programmed routines assume static conditions, yet objects vary in weight, texture, and even subtle deformations – a seemingly uniform apple, for example, might present an unexpectedly yielding surface. Moreover, unforeseen obstacles-a misplaced tool, a shifting shadow, or even a stray cable-can disrupt carefully planned trajectories. This sensitivity stems from a reliance on accurate environmental models; when reality diverges from these models, even slight discrepancies can cascade into significant errors, halting operations or causing collisions. Consequently, robots struggle with tasks requiring adaptability and robust handling of uncertainty, highlighting the limitations of purely model-based control strategies.
The development of truly versatile robotic systems hinges on overcoming the limitations of pre-programmed responses and embracing adaptability in uncertain environments. Current robotic manipulation often falters when faced with the unpredictable nature of the real world – an object might be slightly askew, a surface unexpectedly slippery, or an unforeseen obstacle may appear. Consequently, a central challenge for researchers involves designing robots capable of robustly handling this inherent uncertainty, not by anticipating every possibility, but by learning to react and adjust in real-time. This requires advancements in areas like sensor fusion, machine learning, and control algorithms, enabling robots to generalize from limited experience and successfully navigate novel scenarios without explicit, pre-defined instructions. Ultimately, the goal is to move beyond robotic automation towards genuine robotic intelligence – systems that can reliably perform tasks even when faced with the unexpected.

Beyond Prediction: Geometric and Temporal Intelligence in Action
Robotic manipulation frequently encounters challenges due to the complexity of real-world environments and the need for adaptable planning. RGMP-S addresses these issues by incorporating geometric priors – pre-existing knowledge concerning object shapes, sizes, and physical constraints such as stability and collision avoidance – directly into the robot’s planning process. This integration allows the system to predict plausible object configurations and interaction outcomes, reducing the search space for potential actions and enabling more efficient and reliable manipulation even with limited sensory information. By leveraging these priors, RGMP-S moves beyond purely reactive control and facilitates proactive, geometrically-informed decision-making during task execution.
The RGMP-S framework utilizes spatiotemporal features to enhance robotic manipulation by representing interactions not only as spatial configurations, but also as sequences evolving over time. This approach integrates information about an object’s position, orientation, and shape – the spatial component – with data regarding velocity, acceleration, and contact forces – the temporal dynamics. By jointly considering these factors, RGMP-S enables the system to anticipate and react to changes during interaction, leading to improved robustness in handling variations in object pose, environmental disturbances, and unforeseen contact events. This combined representation facilitates more adaptable behavior, allowing the robot to dynamically adjust its actions based on the evolving state of the interaction.
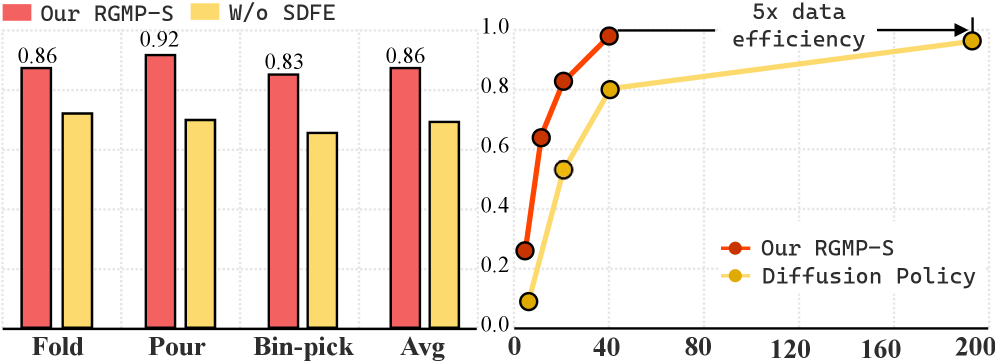
The RGMP-S framework utilizes a modular architecture comprising the Long-horizon Geometric-prior Skill Selector (LGSS) and the Recursive Adaptive Spiking Network (RASNet). The LGSS component pre-selects appropriate manipulation skills based on geometric priors and long-horizon planning, effectively narrowing the search space for optimal actions. RASNet then refines these selected skills through recursive adaptation, allowing for real-time adjustments based on sensory feedback. Benchmarking demonstrates a 5x improvement in data efficiency when compared to the Diffusion Policy baseline, indicating a significantly reduced requirement for training data to achieve comparable performance in robotic manipulation tasks.

Echoes of Biology: Spiking Networks and Robust Feature Learning
Spiking Neural Networks (SNNs) form the core of RASNet, offering a departure from traditional Artificial Neural Networks by more closely mimicking biological neural processes. This approach utilizes discrete, asynchronous events – “spikes” – for computation and communication, resulting in inherent efficiency gains due to event-driven processing and reduced energy consumption. Furthermore, the temporal dynamics of SNNs contribute to robustness against noise and variations in input data, as information is encoded not just in the rate of spiking, but also in the precise timing of spikes. This biological inspiration allows RASNet to achieve robust feature extraction with potentially lower computational cost compared to conventional deep learning architectures.
The Adaptive Spiking Neuron (ASN) within RASNet operates by dynamically adjusting feature retention based on incoming spike patterns. Unlike traditional spiking neurons with fixed thresholds, the ASN incorporates a mechanism to modulate its firing threshold. This allows the neuron to selectively retain and propagate features correlated with stronger or more frequent stimulation, effectively prioritizing relevant information while attenuating noise or less significant inputs. The ASN achieves this modulation through an internal state variable that is updated with each incoming spike, influencing the neuron’s sensitivity and ultimately controlling which features are passed on to subsequent layers of the network. This dynamic adjustment contributes significantly to RASNet’s robustness and efficiency in feature learning.
Rotary Position Embeddings (RoPE) and the Spatial Mixing Block are integral to RASNet’s ability to model spatial relationships within input data. RoPE incorporates positional information by applying rotation matrices to the feature vectors, allowing the network to differentiate features based on their location without requiring learned positional embeddings. The Spatial Mixing Block then leverages this positional awareness to explicitly model interactions between features at different spatial locations. This is achieved through a mechanism that aggregates features based on their relative positions, effectively capturing contextual information and improving the network’s understanding of complex spatial arrangements within the input data. The combined effect of RoPE and the Spatial Mixing Block is enhanced representation learning, particularly for tasks where spatial context is crucial.
Beyond Automation: Towards Truly Adaptive Robotic Systems
The RGMP-S framework addresses the inherent challenges of robotic manipulation by integrating a Gaussian Mixture Model into its action generation process. This allows the system to move beyond deterministic planning and embrace the uncertainties present in real-world environments. Instead of rigidly following a single predicted trajectory, the model generates a distribution of possible actions, weighted by their probability of success. This probabilistic approach enables the robot to gracefully recover from unexpected disturbances – such as slight inaccuracies in object positioning or unforeseen collisions – by selecting actions that maximize its chances of achieving the desired outcome. Essentially, the robot doesn’t just try a single action; it anticipates potential failures and prepares alternative responses, leading to more robust and adaptable performance in complex manipulation tasks.
Rigorous testing of the framework on the Maniskill2 Benchmark confirms its robust generalization capabilities across diverse robotic manipulation tasks. Notably, the system achieves a 96% success rate in grasping Fanta cans, representing a substantial 15% improvement over the Diffusion Policy. Performance extends to more complex scenarios, with a 26.48% success rate in opening cabinet doors – exceeding both the ManiSkill2-1st baseline (24.68%) and the Diffusion Policy (15.32%). Further demonstrating its efficacy, the framework nearly doubles the performance of leading external systems on the PushChair task, attaining a 16.47% success rate, and exhibits a 0.18 improvement in success rate on the Towel Folding task compared to Dex-VLA; these results collectively highlight the framework’s advancement in creating adaptable and reliable robotic systems.
The culmination of this research demonstrates a considerable advancement in robotic manipulation capabilities, as evidenced by the RGMP-S framework’s performance across several challenging benchmarks. Notably, the system achieves a 0.18 improvement in success rate on the complex Towel Folding task when compared to the established Dex-VLA baseline, indicating a heightened capacity for intricate, multi-step motions. This incremental, yet significant, gain, alongside successes in tasks like grasping and cabinet manipulation, suggests that RGMP-S is not merely achieving task completion, but is fostering a more adaptable and robust approach to robotic problem-solving – a crucial step towards deploying robots in dynamic, real-world environments where unforeseen circumstances are the norm.

The research detailed within pushes against the conventional boundaries of robotic manipulation, echoing a sentiment held by Carl Friedrich Gauss: “If others would think as hard as I do, they would not have so little to think about.” RGMP-S doesn’t simply accept existing paradigms; it dissects them, seeking a more fundamental understanding of spatial awareness. By integrating geometric reasoning with spiking neural networks, the framework effectively ‘reverse-engineers’ the process of grasping, demanding a higher level of comprehension than purely data-driven approaches. This isn’t merely about improving performance; it’s about building a system that understands the ‘why’ behind successful manipulation, much like a mathematician seeking elegant proofs rather than brute-force calculation. The pursuit of data efficiency, central to this work, stems from the same intellectual rigor – a refusal to accept limitations without first challenging the underlying assumptions.
What Remains to Be Disassembled?
The construction of RGMP-S-a system ostensibly capable of ‘geometric reasoning’-raises the predictable question: how much of this reasoning is truly understanding, and how much is exquisitely refined pattern matching? The framework demonstrably improves manipulation, yet the underlying principles of spatial awareness remain frustratingly opaque. One suspects the system excels at solving manipulation problems, rather than grasping the fundamental why of object interaction. Future work should not focus solely on achieving better performance metrics, but on developing diagnostic tools to dissect the system’s ‘knowledge’ – to expose the gears turning within this simulated mind.
A crucial limitation lies in the reliance on pre-defined geometric priors. This feels… convenient. True generalizability demands a system that discovers its own priors, that builds its understanding of space not from instruction, but from iterative interaction and, inevitably, failure. The current architecture effectively outsources the difficult part – the initial conceptual framework – leaving the ‘learning’ as a refinement of pre-existing biases. A more ambitious approach would relinquish this control, embracing the messiness of genuine discovery.
Finally, the integration of spiking neural networks, while promising, feels like a solution in search of a problem. The biological inspiration is admirable, but the actual advantage-beyond the theoretical benefits of energy efficiency-remains largely unproven. Perhaps the true potential lies not in mimicking the brain, but in exploiting the unique computational properties of spiking networks to unlock entirely novel approaches to robotic control – a path that requires abandoning the comfortable illusion of ‘intelligence’ and embracing the elegant chaos of emergent behavior.
Original article: https://arxiv.org/pdf/2601.09031.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- How to find the Roaming Oak Tree in Heartopia
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Clash Royale Furnace Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
2026-01-15 19:30