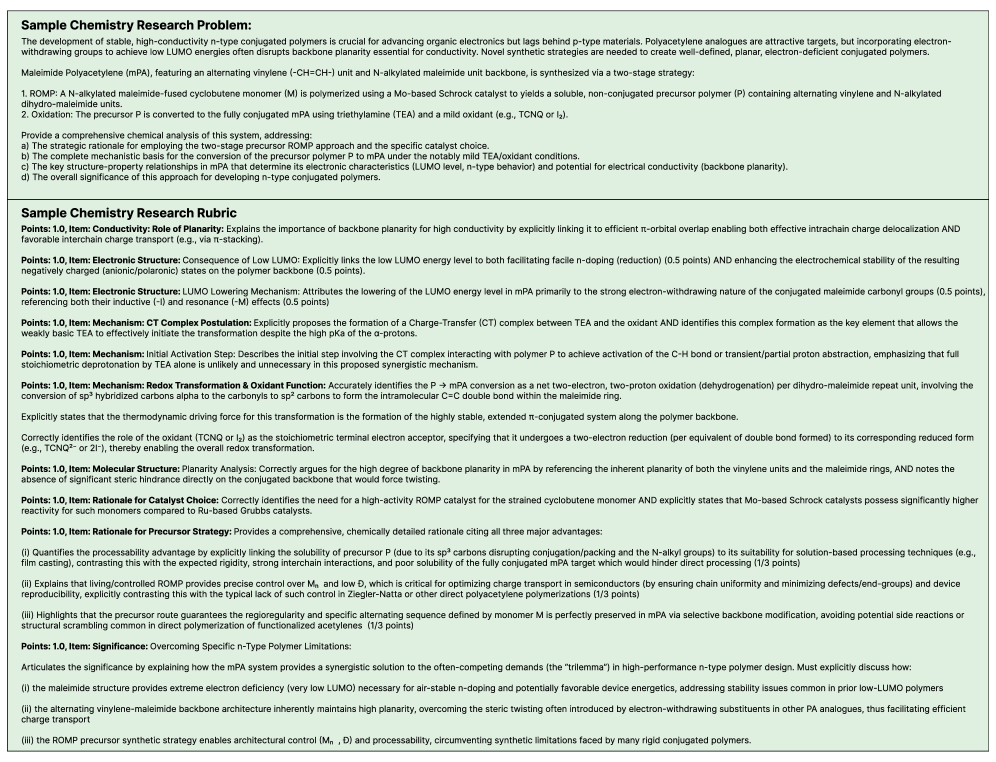
Author: Denis Avetisyan
A new benchmark assesses whether artificial intelligence can tackle complex, open-ended scientific problems at an expert level.

Researchers introduce FrontierScience, a challenging evaluation suite for probing the scientific reasoning abilities of large language models.
Despite recent advances in large language models, robustly evaluating and improving their capacity for expert-level scientific reasoning remains a significant challenge. To address this gap, we introduce FrontierScience: Evaluating AI’s Ability to Perform Expert-Level Scientific Tasks, a benchmark comprising both international olympiad-level problems and open-ended, PhD-level research sub-tasks across physics, chemistry, and biology. Our evaluation reveals that while models demonstrate progress on well-defined problems, substantial hurdles persist in tackling the nuanced, multi-step reasoning required for genuine scientific discovery. Can these models, with continued development and refined evaluation frameworks, ultimately contribute to accelerating the pace of scientific advancement?
Unveiling the Limits of Artificial Deduction
Despite remarkable advancements in processing and generating human language, current language models often falter when confronted with the intricacies of scientific reasoning. These models excel at pattern recognition and statistical correlations within text, enabling them to perform tasks like translation or summarization with impressive accuracy. However, genuine scientific understanding necessitates more than just identifying patterns; it demands the ability to apply fundamental principles, construct causal explanations, and perform logical deductions – skills that remain challenging for artificial intelligence. The limitations stem from a reliance on surface-level associations rather than a deep, conceptual grasp of the underlying scientific principles, hindering their capacity to solve novel problems or critically evaluate scientific claims. While proficient at retrieving information, these models struggle with the inferential leaps and abstract thinking crucial for scientific discovery, exposing a significant gap between linguistic proficiency and true scientific competence.
While benchmarks like MMLU and ScienceQA have become standard for evaluating AI’s scientific aptitude, they often present simplified scenarios that fail to capture the messy, iterative nature of genuine scientific inquiry. These assessments typically rely on multiple-choice questions with single, definitive answers, overlooking the ambiguity and uncertainty inherent in real-world research. Furthermore, they frequently test recall of established facts rather than the ability to synthesize information, formulate hypotheses, or critically evaluate evidence – skills crucial for groundbreaking discovery. Consequently, high scores on these benchmarks don’t necessarily translate to an AI’s capacity to tackle genuinely complex scientific problems, highlighting a significant gap between current evaluation metrics and the demands of authentic scientific reasoning.
The limitations in artificial intelligence’s ability to perform complex scientific reasoning pose a significant obstacle to progress in scientific fields. Current AI systems, despite excelling at pattern recognition and data processing, often lack the crucial capacity for nuanced analysis, hypothesis generation, and logical deduction required for genuine discovery. This deficiency impacts the potential for AI to serve as a collaborative partner to scientists, hindering the development of intelligent assistants that could accelerate research by, for example, identifying critical gaps in knowledge, proposing novel experiments, or efficiently synthesizing information from vast datasets. Ultimately, bridging this capability gap is not merely about improving AI performance; it’s about unlocking a powerful new tool that could redefine the landscape of scientific exploration and innovation, allowing researchers to tackle increasingly complex challenges with unprecedented efficiency and insight.
Constructing a Rigorous Test: The FrontierScience Benchmark
FrontierScience employs a dual-set structure to comprehensively evaluate scientific reasoning capabilities. The benchmark utilizes both an Olympiad set and a Research set, intentionally designed to probe different cognitive skills. The Olympiad set focuses on rapid problem-solving, utilizing concise, short-answer questions modeled after those found in International Science Olympiads. Conversely, the Research set presents complex, open-ended problems that require extended reasoning, detailed justification, and a more nuanced approach reflective of authentic scientific investigation. This bifurcated structure allows for a more granular assessment of an AI model’s ability to handle both immediate recall and application of principles, as well as sustained, in-depth analysis.
The FrontierScience Olympiad set consists of problems modeled after those used in International Science Olympiads, specifically designed to evaluate a candidate’s ability to rapidly apply established scientific principles. These questions require concise, short-answer responses, prioritizing speed and accuracy in recalling and utilizing fundamental knowledge across disciplines like physics, chemistry, and biology. The emphasis is on efficient problem-solving under time constraints, assessing not only understanding of concepts but also the ability to quickly identify and implement the correct approach. This format contrasts with more extended reasoning tasks by focusing on immediate application of learned material rather than in-depth investigation or justification.
The Research set within FrontierScience consists of problems formulated to resemble challenges encountered in authentic scientific research. Unlike the Olympiad set’s emphasis on rapid solution, Research problems necessitate extended reasoning chains and comprehensive justifications for proposed solutions. These problems are intentionally open-ended, allowing for multiple valid approaches and requiring models to demonstrate not just what the answer is, but why that answer is correct, including detailing the methodology and assumptions used in the solution process. This focus on justification is crucial for evaluating a model’s ability to perform complex scientific analysis and articulate its reasoning in a manner consistent with the scientific method.
Dissecting the Response: Rubric-Based Evaluation
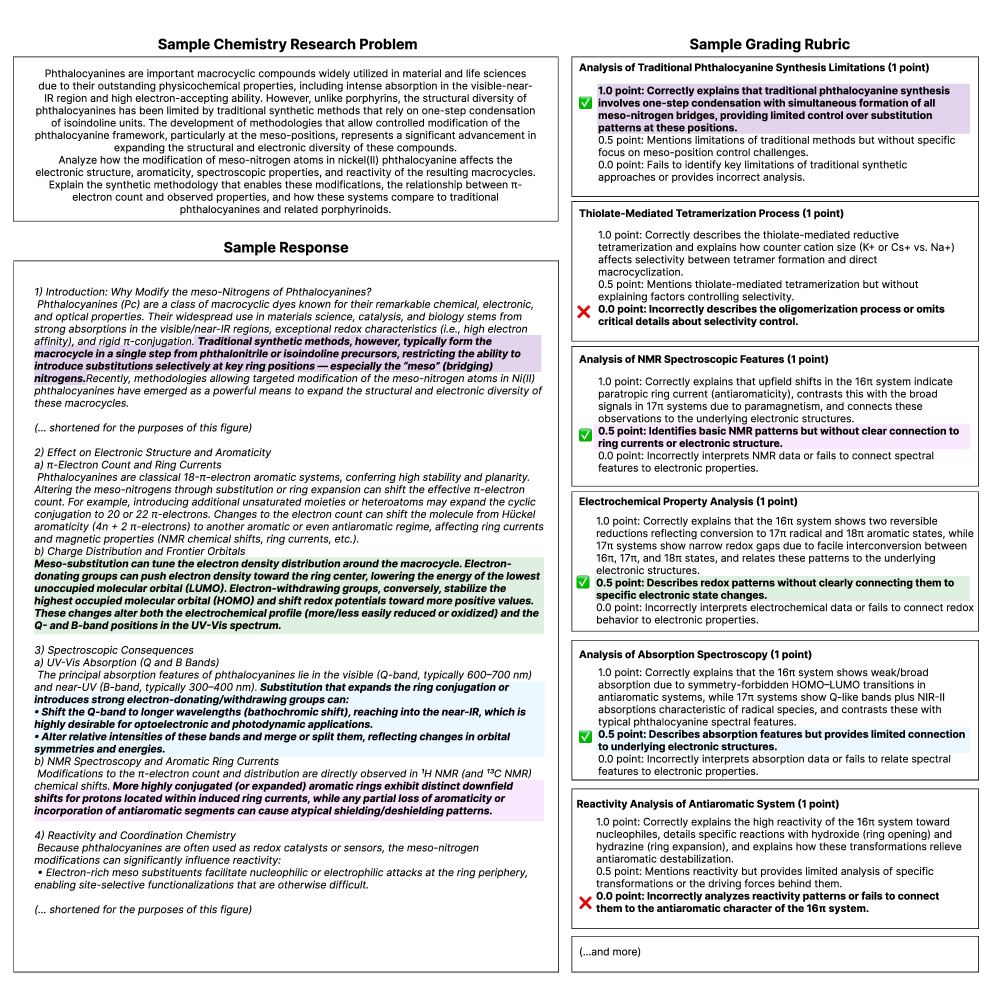
Rubric-based evaluation on the FrontierScience-Research set utilizes pre-defined criteria to systematically assess response quality. This methodology moves beyond simple accuracy metrics by focusing on specific facets of a good answer, such as factual correctness, reasoning quality, and clarity of explanation. Each criterion within the rubric is associated with a defined scoring level, ensuring that evaluations are consistent and replicable across different responses and evaluators. The implementation of a rubric minimizes the impact of subjective interpretation, providing a standardized framework for quantifying answer quality and enabling fair comparisons between model performance.
The evaluation process utilized detailed scoring rubrics designed to assess responses across predefined key aspects, including factual accuracy, reasoning quality, and clarity of explanation. These rubrics consist of specific criteria and associated point values, enabling consistent application of evaluation standards. By explicitly defining performance expectations for each criterion, the rubrics minimize subjective interpretation by human evaluators and the AI Model Judge. This standardized approach facilitates a fair comparison of model outputs, allowing for quantitative assessment of relative performance and identification of specific strengths and weaknesses across different models in the FrontierScience-Research set.
To augment the reliability of evaluations on the FrontierScience-Research set, an AI-driven ‘Model Judge’ utilizing GPT-5 was integrated into the assessment pipeline. This judge was not simply used for automated scoring, but rather to actively participate in the reasoning process, independently evaluating responses against established rubrics. The GPT-5 instance was prompted to provide justifications for its assessments, allowing for a review of its rationale and identification of potential biases or inconsistencies. This approach facilitated a more nuanced and transparent evaluation process, moving beyond simple metric-based comparisons and allowing for qualitative analysis of model performance based on the AI judge’s articulated reasoning.
Charting the Course: Performance and Future Trajectories
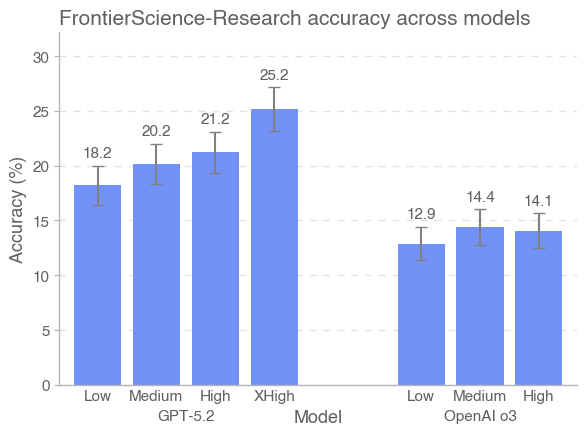
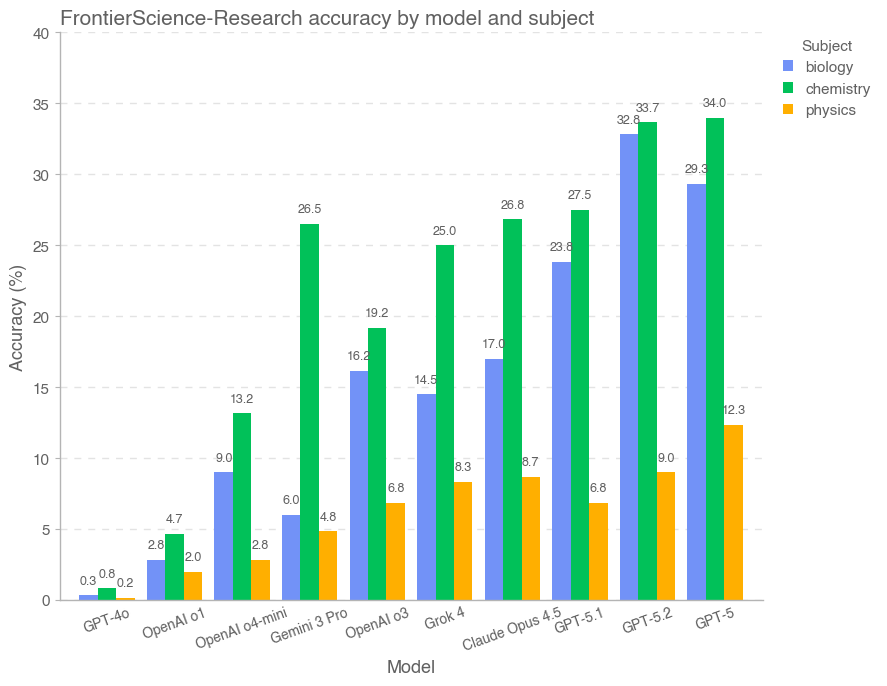
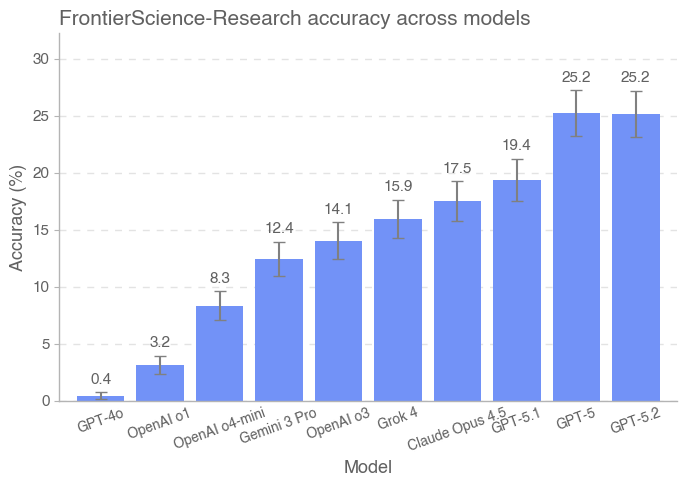
GPT-5.2 has established a new benchmark in artificial intelligence for scientific reasoning, as evidenced by its performance on the challenging FrontierScience benchmark. The model achieved an impressive 77% accuracy on the Olympiad set – a collection of highly complex, competition-level scientific problems – demonstrating a capacity for rapid and accurate problem-solving. While success on the Olympiad set is noteworthy, GPT-5.2 also attained 25% accuracy on the Research set, which presents more nuanced and open-ended research-level questions. This result, though lower, signifies a crucial step towards enabling AI to grapple with the ambiguities inherent in genuine scientific inquiry, and suggests increasing capabilities in expert-level reasoning that could one day contribute to novel discoveries.
Gemini 3 Pro’s performance on the FrontierScience Olympiad set reached 76% accuracy, a result demonstrably competitive with state-of-the-art models and indicative of its strength in swiftly analyzing and solving complex scientific problems. This proficiency suggests an advanced capacity for pattern recognition and logical deduction, allowing the model to efficiently navigate the structured challenges presented by the Olympiad benchmark. The achievement isn’t merely about achieving a high score; it points to a growing ability for AI to rapidly process information and apply established scientific principles, a crucial step towards automating elements of the scientific process and accelerating discovery.
Despite recent advancements showcased by models like GPT-5.2 and Gemini 3 Pro, significant challenges remain in leveraging artificial intelligence for genuine scientific discovery. Current AI capabilities, while proficient in rapidly solving well-defined problems – as evidenced by high scores on the Olympiad benchmark – still struggle with the nuanced complexities of the Research set. This set demands more than just computational power; it requires the ability to synthesize information from diverse sources, formulate novel hypotheses, and navigate ambiguous or incomplete data – skills crucial for pushing the boundaries of scientific knowledge. Further refinement of AI algorithms, coupled with access to comprehensive and meticulously curated scientific datasets, is therefore essential to unlock the full potential of these tools and facilitate breakthroughs across various scientific disciplines.
Expanding the Horizon: The Future of Scientific Benchmarking
FrontierScience emerges not as a replacement for established scientific benchmarks, but as an extension of their collective strengths. Existing resources like ChemBench, PHYBench, CritPt, LAB-Bench, and PaperBench each focus on specific domains or problem types, providing valuable, though often isolated, assessments of AI capabilities. This new benchmark intentionally complements these efforts by broadening the scope of scientific evaluation, integrating diverse challenges that demand reasoning across multiple disciplines. By building upon this foundation, FrontierScience aims to foster a more holistic understanding of an AI system’s scientific aptitude – its ability to not just solve problems within a narrow field, but to synthesize knowledge and apply it creatively to novel, interdisciplinary scenarios. This interconnected approach promises a more nuanced and comprehensive evaluation of progress in artificial intelligence for scientific discovery.
The creation of the Olympiad benchmark involved a rigorous distillation process, beginning with an initial collection of over 500 potential questions. Each question underwent careful scrutiny, assessing its scientific validity, clarity, and suitability for evaluating advanced AI reasoning capabilities. This extensive pool was systematically narrowed through multiple rounds of evaluation, focusing on identifying problems that demanded not just factual recall, but also deep understanding and innovative problem-solving skills. The final set comprises 100 high-quality questions, representing a challenging yet attainable standard for assessing the frontier of artificial intelligence in scientific domains – a curated collection designed to push the boundaries of automated reasoning and knowledge application.
The creation of the Research set involved a rigorous curation process, ultimately yielding a collection of 60 questions distilled from an initial pool exceeding 200. This careful selection wasn’t simply about quantity; each question underwent scrutiny to ensure it represented genuine research-level challenges, demanding not just factual recall but also analytical reasoning and problem-solving skills. The extensive filtering process aimed to identify questions that mirrored the complexities encountered in authentic scientific investigations, focusing on those requiring the application of multiple concepts and critical evaluation of information. This dedication to quality ensures the Research set provides a robust and realistic assessment of an AI’s capacity for advanced scientific inquiry, moving beyond textbook examples to embrace the nuanced demands of active research.
The progression of scientific benchmarking isn’t envisioned as static; ongoing development centers on crafting assessments that mirror the intricacies of authentic research. Future iterations will move beyond idealized problem sets to embrace the messiness of real-world data – incorporating datasets gleaned from experiments, observations, and simulations. This expansion includes the deliberate introduction of complex, multi-faceted scenarios demanding not just calculation, but also critical thinking, hypothesis generation, and error analysis. By challenging AI systems with problems lacking clean solutions and requiring integration of diverse information, researchers aim to foster a new generation of tools truly capable of assisting – and accelerating – scientific discovery across multiple disciplines.
The iterative improvement of scientific benchmarks is poised to unlock the potential of artificial intelligence in addressing critical scientific problems and driving a new era of discovery. By continually challenging AI systems with increasingly complex and realistic scenarios, researchers can foster the development of algorithms capable of not merely replicating existing knowledge, but of genuinely contributing to the scientific process. This ongoing refinement extends beyond simple accuracy metrics; it necessitates the creation of benchmarks that evaluate reasoning, creativity, and the ability to generalize knowledge to novel situations, ultimately empowering AI to accelerate innovation across diverse fields – from materials science and drug discovery to climate modeling and fundamental physics. The resulting systems promise to augment human capabilities, enabling researchers to explore previously inaccessible frontiers and tackle the most pressing challenges facing society.
The pursuit of FrontierScience exemplifies a willingness to dismantle established notions of AI capability. This benchmark, constructed around complex scientific queries, isn’t merely about answering questions, but probing the limits of what constitutes genuine reasoning. It inherently accepts that current systems will falter-and in those failures, valuable data emerges. As John McCarthy once stated, “It is better to be wrong and learn from your mistakes than to be right and learn nothing.” The study’s focus on open-ended research tasks deliberately pushes against pre-defined boundaries, embracing the necessary “wrongness” to map the terrain of true AI scientific potential. The challenges identified aren’t roadblocks, but invitations to re-engineer the very foundations of automated reasoning.
Beyond the Horizon
The exercise of benchmarking, particularly in a domain as stubbornly complex as scientific reasoning, always feels like mapping a ghost. FrontierScience doesn’t offer a perfect capture, but a clearer impression of where the current specter resides. The benchmark itself isn’t the destination; it’s a calibrated disruption, designed to expose the fault lines in the architecture of these models. The present results indicate a capacity for pattern recognition that mimics competence, but genuine scientific progress demands more than skillful mimicry – it requires the capacity to invent patterns.
Future iterations of this inquiry shouldn’t focus solely on increasing scores. The true challenge lies in constructing evaluations that demand not just correct answers, but justifiable approaches. Models can be trained to navigate existing knowledge; the critical next step is to assess their ability to formulate novel hypotheses, design experiments (even hypothetically), and embrace – even learn from – failure. The current paradigm prioritizes convergent thinking; the future demands divergent exploration.
Ultimately, the pursuit of artificial scientific intelligence isn’t about creating machines that do science, but about forcing a deeper understanding of what constitutes science itself. Each limitation revealed, each benchmark surpassed, merely clarifies the boundary of the unknown – and that, after all, is where the interesting work begins.
Original article: https://arxiv.org/pdf/2601.21165.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-30 07:58