Author: Denis Avetisyan
A new framework streamlines web automation by intelligently reducing the amount of webpage data agents need to process, leading to faster and more accurate results.

Prune4Web leverages multimodal learning and DOM pruning to enhance the efficiency of web automation agents.
Despite advances in large language model-driven web automation, efficiently navigating complex webpages remains challenging due to the massive size of their Document Object Model (DOM) structures. This paper introduces Prune4Web: DOM Tree Pruning Programming for Web Agent, a novel framework that shifts DOM processing from resource-intensive LLM analysis to efficient, programmatic pruning. By enabling LLMs to generate executable Python scripts for dynamically filtering DOM elements, Prune4Web achieves substantial reductions in candidate elements-up to 50x-while improving action localization and mitigating attention dilution. Could this paradigm of programmatic filtering unlock a new era of scalable and accurate web automation agents?
The Fragility of Digital Structures
Historically, automating tasks on the web has proven remarkably difficult due to the fundamental methods employed. Traditional web interaction typically depends on identifying elements through brittle selectors – code that pinpoints items based on their precise location within a webpage’s structure. This approach falters when websites undergo even minor redesigns, as these changes invalidate the selectors and break the automation. Moreover, complex tasks often necessitate extensive manual scripting, requiring developers to anticipate every possible scenario and write code to handle each variation. This reliance on rigid, hand-crafted solutions not only limits the adaptability of web automation but also makes it a time-consuming and expensive process, ultimately hindering the development of truly intelligent web agents capable of navigating the ever-changing digital landscape.
The modern web, characterized by frequent updates and intricate JavaScript frameworks, presents a significant challenge to automated agents. These agents require more than simple pattern matching; they must possess the ability to robustly interpret dynamic content, understand the underlying structure of webpages even as it shifts, and reliably navigate complex interactions. Existing automation techniques often falter when confronted with even minor webpage alterations, necessitating constant maintenance and limiting scalability. The development of agents capable of adapting to these fluid environments is therefore paramount, unlocking the potential for truly autonomous web interaction and enabling applications ranging from automated data extraction and monitoring to sophisticated digital assistants that can seamlessly operate within the ever-changing landscape of the internet.
Existing web automation techniques often falter when confronted with tasks demanding more than simple pattern matching. These systems typically excel at identifying and interacting with static elements, but struggle with scenarios requiring compositional reasoning – the ability to synthesize information gleaned from multiple webpages or dynamically changing content. For instance, a task like comparing prices across several e-commerce sites, each with differing layouts and update frequencies, presents a significant challenge. Current approaches frequently necessitate meticulously crafted, page-specific scripts that are easily broken by even minor website alterations. This limitation hinders the development of truly robust and adaptable web agents capable of autonomously completing complex, multi-step processes, effectively restricting automation to simpler, pre-defined workflows and necessitating ongoing manual maintenance.
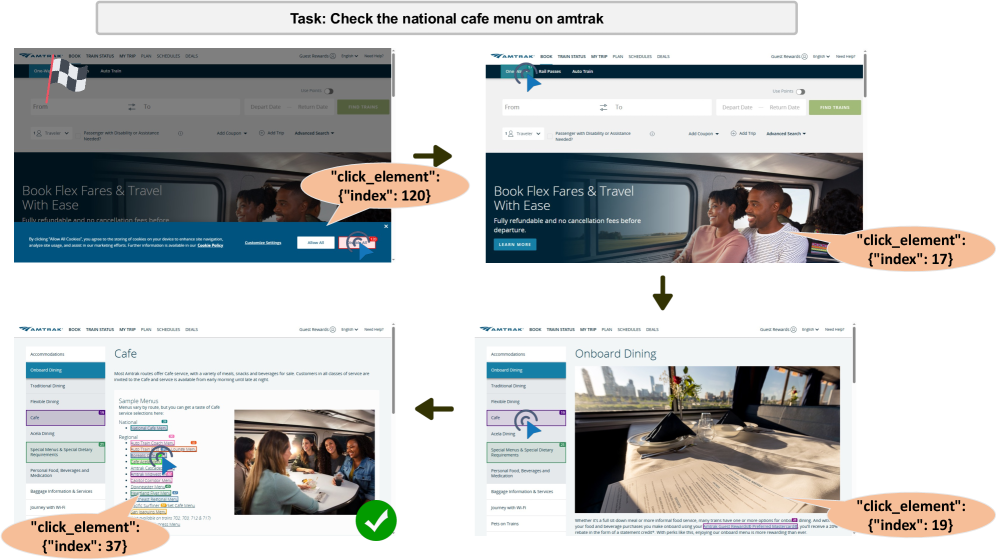
The Allure of Multi-Modal Perception
Large Language Models (LLMs) facilitate agent functionality by processing web content and deriving actionable plans. These models are capable of interpreting the semantic meaning of text-based web pages, identifying relevant information, and subsequently constructing a sequence of steps to achieve a specified goal. This reasoning process involves parsing HTML structure, extracting data from designated elements, and applying learned knowledge to determine appropriate actions, such as form completion, link navigation, or data extraction. The LLM’s ability to understand context and relationships within the web content is critical for formulating effective and coherent action plans without requiring explicit programming for each website or task.
While Large Language Models (LLMs) can process textual HTML content, agent performance is significantly improved by incorporating visual information via screenshots. This is because many web-based tasks require understanding elements not directly represented in the HTML source code, such as the visual layout, specific branding, or the content of images. By providing screenshots alongside the HTML, agents can leverage computer vision techniques to extract visual cues, allowing them to more accurately interpret the webpage and execute tasks that rely on visual understanding, such as identifying buttons, reading text within images, or verifying the visual state of an element.
Multi-modal systems improve agent performance by integrating diverse data types beyond text. While Large Language Models (LLMs) excel at processing textual information, supplementing this with visual data – such as screenshots of web pages or application interfaces – allows agents to better interpret context and user intent. Other modalities, including audio input, sensor data, or structured data formats, can further refine the agent’s understanding of the environment and task requirements. This combined approach addresses limitations inherent in relying solely on text, leading to increased accuracy, robustness, and adaptability in complex scenarios.

The Elegance of Minimal Representation
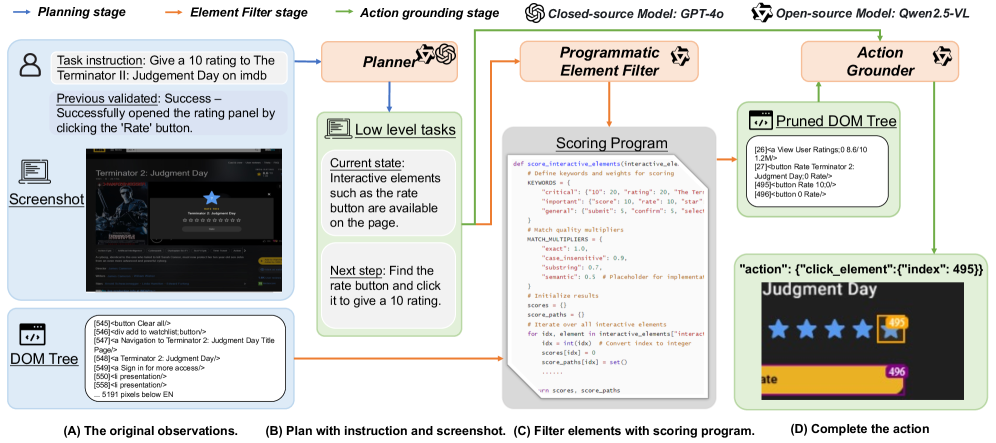
Programmatic DOM tree pruning represents a significant optimization in web page interpretation by selectively retaining only the elements pertinent to the current task. Instead of processing the entire Document Object Model, this technique focuses computational resources on a reduced subset of nodes, thereby decreasing latency and resource consumption. The process involves dynamically identifying and discarding irrelevant elements based on the specific requirements of the operation being performed, effectively streamlining the information flow and enhancing overall efficiency. This targeted approach contrasts with traditional methods that operate on the complete DOM, regardless of the task at hand.
The Programmatic Element Filter operates by dynamically generating Python scoring programs during web page interpretation. These programs are not pre-defined but are created on-the-fly based on the specific requirements of the current task. This approach allows for a flexible and context-aware evaluation of each DOM element, assigning a score reflecting its relevance. The generated Python code directly assesses element attributes and content against the defined criteria, enabling a precise ranking of elements for subsequent processing and reducing the computational burden of evaluating the entire DOM tree.
The computational efficiency of DOM interpretation is significantly improved by evaluating each element against the requirements of specific ‘LowLevelSubTask’ objectives. This evaluation, performed by dynamically generated Python scoring programs, allows the system to prioritize elements directly relevant to the current task and disregard those that are not. By focusing processing only on necessary elements, the overall computational overhead is drastically reduced, leading to faster and more resource-efficient web page analysis. This targeted approach avoids the need to process the entire DOM tree for every task, yielding substantial performance gains.
The efficacy of the DOM tree pruning stage is quantitatively assessed using the RecallAtK metric, which measures the proportion of relevant elements retained within the top $K$ ranked elements after filtering. Evaluation on low-level sub-task grounding tasks demonstrates an 88.28% grounding accuracy, indicating that the filtering process successfully identifies and retains the majority of elements crucial for completing these sub-tasks. This performance level suggests a significant reduction in computational load without substantial compromise to the ability to accurately interpret and process relevant web page content.
The Refinement of Automated Intellect
Agent performance is optimized via a sequential two-stage fine-tuning process. Initially, the model undergoes SupervisedFineTuning, leveraging a dataset of demonstrated interactions to establish foundational behavioral patterns. This is followed by ReinforcementFineTuning, where the agent learns to maximize cumulative rewards through interaction with an environment. This two-stage approach allows the agent to first acquire a broad understanding of desired behaviors, then refine these behaviors through iterative feedback, resulting in significantly improved performance metrics as demonstrated by a Recall@5 exceeding 95%.
The supervised learning phase utilizes the ‘TwoTurnDialogue’ paradigm to improve agent response quality and contextual understanding. This method involves presenting the agent with a two-turn conversational exchange – an initial user query followed by a desired model response – as training data. By explicitly demonstrating the expected response within a conversational context, the agent learns to better anticipate user needs and generate more relevant and coherent outputs. This approach moves beyond single-turn question-answer pairs, providing the model with a more complete representation of typical conversational flow and improving its ability to maintain context across interactions.
The reinforcement learning phase employs a Hierarchical Reward Mechanism to guide agent behavior by decomposing the overall task into sub-goals, each associated with a specific reward signal. This mechanism facilitates learning complex behaviors through incremental progress and avoids the challenges of sparse rewards. Optimization is achieved using the Generalized Reward-based Policy Optimization (GRPO) algorithm, a policy gradient method designed for stable and efficient learning in complex environments. GRPO iteratively refines the agent’s policy by maximizing the cumulative reward signal derived from the Hierarchical Reward Mechanism, resulting in optimized agent responses.
Evaluation of the fine-tuned models indicates a Recall@5 metric exceeding 95%, validating the effectiveness of the implemented training pipeline. This performance level is achieved while maintaining comparable results to larger models, specifically Qwen2.5-0.5B, when applied to tasks involving information filtering and grounding. This suggests the fine-tuned models offer a substantial performance-to-parameter ratio, delivering high accuracy with a reduced computational footprint for these specific functions.

Towards Systems That Adapt and Endure
Recent advancements in web automation have yielded agents possessing a remarkable capacity for navigating and interacting with online environments. These agents achieve robustness not through singular innovation, but through a synergistic combination of technologies; multi-modal perception allows them to interpret web pages using both visual and textual cues, mirroring human understanding. Crucially, an efficient Document Object Model (DOM) tree pruning technique minimizes computational load by focusing on relevant page elements, enabling faster processing and reduced resource consumption. This streamlined approach is further amplified by advanced training techniques – specifically, reinforcement learning – which allow the agents to adapt and improve their performance through repeated interaction with web pages, ultimately achieving a level of automation previously unattainable with rule-based or template-driven systems.
Traditional web automation often relies on brittle selectors – like XPath or CSS – that are easily broken by even minor website changes. This new approach sidesteps those limitations by leveraging multi-modal perception, allowing agents to ‘see’ and ‘understand’ web pages much like a human. Instead of rigidly following pre-defined instructions, these agents dynamically adapt to shifting layouts and content. Efficient pruning of the Document Object Model (DOM) tree further streamlines processing, enabling swift navigation even within highly complex and rapidly updating web environments. Consequently, the agents demonstrate significantly improved robustness and reliability when interacting with real-world websites, opening possibilities for automation tasks previously considered too challenging or impractical.
The development roadmap prioritizes extending the capabilities of these web automation agents to tackle increasingly intricate challenges. Current research concentrates on refining the agents’ ability to decompose complex goals into manageable sub-tasks, enabling them to handle multi-step workflows previously beyond their reach. A key area of investigation involves bolstering the agents’ resilience to unexpected changes in web page structure and content, ensuring reliable operation even in highly dynamic environments. Ultimately, the aim is seamless integration into practical applications – from automating customer service interactions and data extraction to assisting with e-commerce tasks and streamlining business processes – bringing the promise of truly intelligent web automation to fruition.
The pursuit of efficient web automation, as detailed in Prune4Web, inherently acknowledges the transient nature of digital structures. Any improvement to the agent’s analytical capabilities, while initially impactful, will inevitably face the increasing complexity of evolving web pages. As Robert Tarjan aptly stated, “The key to good programming is understanding the problem.” This understanding extends beyond immediate functionality; it demands anticipation of decay and a strategy for graceful adaptation. Prune4Web’s DOM pruning technique, by actively reducing analytical load, isn’t simply a performance boost, but a calculated maneuver against the inevitable entropy of the web-a system where even the most elegant solutions age faster than expected.
What’s Next?
The pursuit of robust web automation, as demonstrated by Prune4Web, inevitably confronts the entropic reality of the web itself. Each refinement of DOM parsing, each optimization of agent interaction, merely delays the inevitable accrual of technical debt – the constant expansion of brittle code attempting to map onto a perpetually shifting landscape. Uptime, in this context, isn’t a state to be achieved, but a rare phase of temporal harmony before the next unavoidable refactoring.
Future work must address the fundamental limitations of treating the DOM as a stable substrate. The current paradigm excels at navigating existing structures, but struggles with the dynamic, JavaScript-rendered web where content appears and vanishes with algorithmic indifference. A shift toward understanding webpages not as static trees, but as streams of events – a focus on change rather than state – may prove crucial. This requires moving beyond multimodal learning of content, toward learning the processes that generate it.
Ultimately, the challenge isn’t simply to build agents that can use the web, but agents that can anticipate its decay. True resilience lies not in minimizing complexity, but in embracing the inherent instability of the system, and designing for graceful degradation. The lifespan of any automation framework is finite; the art lies in extending that lifespan-not through perpetual motion, but through elegant acceptance of inevitable erosion.
Original article: https://arxiv.org/pdf/2511.21398.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Clash Royale December 2025: Events, Challenges, Tournaments, and Rewards
- Clash Royale Furnace Evolution best decks guide
- December 18 Will Be A Devastating Day For Stephen Amell Arrow Fans
- Clash Royale Witch Evolution best decks guide
- Mobile Legends X SpongeBob Collab Skins: All MLBB skins, prices and availability
- All Soulframe Founder tiers and rewards
- Now That The Bear Season 4 Is Out, I’m Flashing Back To Sitcom Icons David Alan Grier And Wendi McLendon-Covey Debating Whether It’s Really A Comedy
- Mobile Legends November 2025 Leaks: Upcoming new heroes, skins, events and more
- BLEACH: Soul Resonance: The Complete Combat System Guide and Tips
2025-12-01 06:35