Author: Denis Avetisyan
A new study demonstrates that directly comparing outputs from text-to-image models fundamentally changes how users evaluate and understand their underlying behaviors.

Researchers find a side-by-side comparison interface, MIRAGE, promotes a more comprehensive auditing strategy for generative AI and facilitates the detection of subtle biases.
Despite growing enthusiasm for generative AI, assessing the trustworthiness of text-to-image (T2I) models remains a significant challenge. This paper, ‘Seeing Twice: How Side-by-Side T2I Comparison Changes Auditing Strategies’, investigates how a comparative interface-MIRAGE-reshapes user approaches to auditing these models. Our findings reveal that side-by-side evaluation encourages a shift from analyzing individual outputs to identifying broader model ‘personalities’ and surfacing previously hidden biases, such as language-dependent fidelity gaps. Could such simple comparative tools fundamentally alter how we understand and evaluate the complex behaviors of generative AI?
Deconstructing the Image: Unveiling AI’s Hidden Biases
The surge in text-to-image models, capable of generating visuals from textual descriptions, presents a significant challenge to ensuring fairness and accuracy in artificial intelligence. As these models become increasingly prevalent, their potential to reflect and amplify existing societal biases-regarding gender, race, or other characteristics-demands careful scrutiny. Unlike traditional algorithms with clearly defined parameters, these generative models learn from vast datasets, inheriting and potentially exaggerating the prejudices embedded within them. This opacity makes identifying and mitigating bias exceptionally difficult, as the connection between input text and generated image is complex and non-linear. Consequently, the widespread deployment of these models without robust evaluation tools risks the inadvertent perpetuation of harmful stereotypes and misrepresentations, impacting perceptions and potentially reinforcing societal inequalities.
Current techniques for assessing text-to-image models frequently struggle to capture the subtleties of their performance and how people actually perceive the resulting visuals. Traditional metrics often prioritize quantifiable aspects – like image fidelity or adherence to the text prompt – while overlooking crucial nuances in representation and potential for bias. These evaluations often treat images as isolated outputs, failing to account for the broader patterns and distributions a model generates when prompted repeatedly. Consequently, even models scoring well on objective metrics can exhibit problematic tendencies – such as reinforcing stereotypes or generating skewed depictions – that remain undetected by conventional evaluation frameworks. This disconnect between automated assessment and human perception highlights a critical need for more holistic and user-centered evaluation methods to truly understand and mitigate the risks associated with these powerful generative technologies.
The unchecked deployment of text-to-image generation models presents a significant risk of reinforcing and amplifying societal biases. These models, trained on vast datasets often reflecting existing prejudices, can readily produce outputs that perpetuate harmful stereotypes regarding gender, race, and other sensitive attributes. Without comprehensive auditing tools capable of identifying and mitigating these biases, the potential for misrepresentation and the dissemination of prejudiced imagery increases substantially. This isn’t merely a technical challenge; it represents a societal concern, as these models increasingly shape visual culture and influence perceptions, potentially leading to real-world consequences for marginalized groups. The absence of such oversight could normalize biased representations, subtly influencing attitudes and reinforcing inequalities through seemingly innocuous generated content.
Recent research indicates a significant benefit to evaluating text-to-image artificial intelligence by presenting outputs from multiple models concurrently. The study revealed that participants, when presented with side-by-side comparisons, moved beyond scrutinizing individual images in isolation. Instead, users began to analyze the broader patterns and distributions of generated content, effectively identifying systemic biases and problematic representations that would remain hidden when assessing each model’s output in a vacuum. This shift in focus suggests that comparative analysis is a powerful tool for uncovering subtle but pervasive biases embedded within these increasingly sophisticated AI systems, offering a more comprehensive approach to responsible AI development and deployment.

MIRAGE: A System for Comparative Dissection
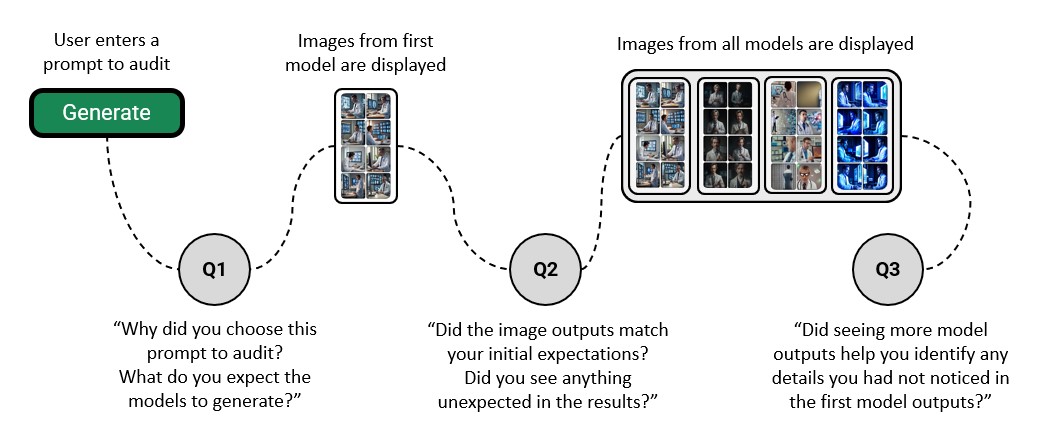
MIRAGE is a web-based application engineered to facilitate the comparative analysis of outputs generated by diverse text-to-image models. The platform enables users to submit identical text prompts to multiple models and view the resulting images in a synchronized, side-by-side format. This direct visual comparison is intended to support both qualitative assessment of image quality and identification of model-specific strengths and weaknesses. The application is designed to handle a variety of models without requiring local installation or complex configuration, streamlining the evaluation workflow for researchers and developers.
MIRAGE utilizes the Replicate platform as a backend for hosting and executing text-to-image models, and for generating the resulting images. This integration eliminates the need for local model deployments and associated infrastructure management for evaluators. Replicate’s API handles model loading, execution, and scaling, allowing MIRAGE to focus on the user interface and evaluation logic. Image generation requests are submitted to Replicate, and the generated images are then returned to MIRAGE for display and comparison, effectively streamlining the evaluation pipeline and reducing setup complexity.
Micro-interaction buffering in MIRAGE addresses the inherent latency associated with cloud-based image generation. The platform pre-fetches and buffers subsequent image requests while a prior request is being processed by the Replicate service. This technique anticipates user interaction and proactively prepares results, effectively masking network delays and processing times. Consequently, users experience a continuous and responsive interface, allowing for faster iteration and more efficient side-by-side comparison of model outputs without perceptible pauses between image renders.
User study data indicated a behavioral shift among participants utilizing the MIRAGE platform for multi-model comparison. Specifically, four participants reported transitioning their evaluation strategy from detailed inspection of individual image outputs to a focus on analyzing the broader distributions and patterns across all generated images. This suggests that MIRAGE facilitates a higher-level comparative assessment, enabling users to move beyond pixel-level differences and concentrate on systemic variations in model performance and output characteristics.

Exposing the Ghosts in the Machine: Model Personalities and Biases
Analysis within the MIRAGE framework revealed that different generative models consistently produce outputs with discernible stylistic characteristics, which can be described as emergent ‘personalities’. For example, Kandinsky 2.2 consistently generated images exhibiting a high degree of color saturation and visual vibrancy compared to other models tested. These differences were not random; side-by-side comparisons demonstrated a repeatable tendency for each model to favor specific aesthetic qualities, indicating inherent variations in how each model interprets and translates input prompts into visual representations.
Evaluations within the MIRAGE framework revealed consistent output characteristics across multiple generations from Stable Diffusion and Latent Consistency models. Specifically, 6 of 12 participants noted inaccuracies in the proportional representation of objects and figures generated by Stable Diffusion. Conversely, Latent Consistency frequently produced images exhibiting exaggerated features and a generally cartoonish aesthetic, as reported by 3 participants. These consistent tendencies suggest inherent limitations in the models’ abilities to accurately render realistic proportions or maintain stylistic fidelity, potentially stemming from the composition of their respective training datasets.
Variations in generated image characteristics, such as proportional inaccuracies in Stable Diffusion or the cartoonish style of Latent Consistency, can be attributed to inherent biases and limitations present in the datasets used for model training. These datasets, composed of images sourced from the internet, inevitably reflect existing societal biases and imbalances in representation. Consequently, models learn to reproduce these patterns, leading to skewed or inaccurate outputs. The observed differences aren’t random; they are systematic errors stemming from the statistical properties of the training data, impacting the model’s ability to generate neutral or universally accurate depictions. The MIRAGE study indicated that these discrepancies became apparent when comparing outputs across multiple models, highlighting how different datasets contribute to distinct visual tendencies and potential biases.
User evaluations within the MIRAGE study revealed consistent perceptual differences across generative models. Six participants specifically noted that images produced by Stable Diffusion frequently exhibited inaccuracies in the proportions of depicted subjects. A separate assessment indicated that three participants characterized outputs from Latent Consistency Models as cartoonish or exaggerated in style. Importantly, a single participant was able to identify a potential bias – a correlation between skin tone and occupational attire – only after comparative analysis of outputs generated by multiple models, highlighting the value of multi-model evaluation for uncovering subtle biases.
Towards a Future of Accountable Creation: Auditing and Transparency
MIRAGE addresses a critical need for systematic evaluation of text-to-image models, offering a platform designed to illuminate potential risks before they manifest in real-world applications. This tool empowers AI developers by providing a means to proactively identify and mitigate biases, safety concerns, and unintended outputs that may arise from increasingly sophisticated generative AI. Researchers benefit from a standardized environment for comparative analysis, fostering advancements in model robustness and reliability. Furthermore, policymakers can leverage MIRAGE’s insights to inform the development of responsible AI guidelines and regulations, ensuring these powerful technologies align with societal values and ethical considerations. By focusing on quantifiable metrics alongside human perception, MIRAGE moves beyond simple technical assessments, offering a holistic approach to understanding and managing the complex challenges posed by text-to-image generation.
The increasing complexity of artificial intelligence systems necessitates a shift towards explainable AI (XAI), and visual comparison plays a crucial role in achieving this transparency. Rather than relying solely on technical metrics, the platform emphasizes how humans perceive the outputs of text-to-image models. This approach acknowledges that AI evaluation isn’t simply about algorithmic accuracy, but also about subjective qualities like realism, coherence, and alignment with the given prompt. By directly comparing generated images and soliciting user feedback, the platform provides insights into potential biases, unexpected behaviors, and areas where models fall short of human expectations. This focus on user perception is increasingly vital as AI systems are deployed in creative fields and applications where aesthetic quality and nuanced understanding are paramount, offering a bridge between algorithmic performance and human-centered design.
A critical challenge in advancing artificial intelligence lies in evaluating model safety and fairness without compromising intellectual property. To address this, an anonymous auditing feature is proposed, allowing developers to assess their proprietary text-to-image models against established benchmarks and potential vulnerabilities without revealing sensitive training data or model architecture. This system functions by submitting prompts to a series of models-including the one being audited-and comparing the resulting images based on predefined metrics and human evaluation. The anonymity is preserved by masking the source of each image, ensuring that comparisons are based solely on output quality and adherence to safety guidelines. This approach fosters greater transparency and accountability in the development of AI, encouraging developers to proactively identify and mitigate risks associated with their models while maintaining a competitive edge.
A user study involving fifteen participants assessed the platform’s efficacy, requiring approximately 45 minutes of their time and providing a $15 gift card as compensation. Initial feedback revealed a notable preference for the ByteDance Sdxl model among five of those surveyed, who specifically lauded its superior image quality and greater diversity in generated outputs. This suggests that, while MIRAGE facilitates comparative analysis across various models, certain architectures already demonstrate a perceived advantage in visual fidelity and creative range, highlighting potential benchmarks for future AI auditing and development efforts.

The study reveals a fascinating interplay between observation and understanding, mirroring a core tenet of robust system analysis. It demonstrates that simply seeing a text-to-image model’s output isn’t enough; a comparative approach, such as that offered by MIRAGE, unlocks a deeper comprehension of its inherent biases and ‘personality’. This echoes Linus Torvalds’ sentiment: “Most good programmers do programming as a hobby, and then they get paid to do it.” The act of meticulously comparing outputs, probing for inconsistencies, isn’t merely an auditing procedure; it’s an intellectual exercise, a form of reverse-engineering the generative AI’s internal logic, driven by an inherent curiosity. The system isn’t just tested; it’s understood through deconstruction.
Unraveling the Source Code
The exploration of side-by-side comparison as a means of auditing text-to-image models doesn’t offer solutions, but rather, sharper questions. This work suggests that a user interface isn’t merely a window onto the model, but an active participant in constructing understanding. It highlights that identifying bias isn’t about finding definitive errors, but recognizing the consistent ‘personality’-the inherent limitations and stylistic quirks-of these generative systems. The real challenge lies in quantifying that personality, and determining whether it aligns with intended application.
Future work must move beyond simply detecting discrepancies. The field needs to establish methods for systematically deconstructing the internal logic of these models – essentially, reverse-engineering the algorithms that give rise to these ‘personalities’. This means developing tools that allow researchers to probe the latent space, identify the root causes of bias, and ultimately, rewrite the code.
Ultimately, this research reinforces a core principle: reality is open source-it’s just that the code is incredibly complex and poorly documented. The goal isn’t to achieve perfect objectivity, but to gain a more nuanced and critical understanding of the systems we create, acknowledging that every line of code carries an inherent perspective.
Original article: https://arxiv.org/pdf/2511.21547.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Clash Royale Furnace Evolution best decks guide
- December 18 Will Be A Devastating Day For Stephen Amell Arrow Fans
- Clash Royale Witch Evolution best decks guide
- All Soulframe Founder tiers and rewards
- Now That The Bear Season 4 Is Out, I’m Flashing Back To Sitcom Icons David Alan Grier And Wendi McLendon-Covey Debating Whether It’s Really A Comedy
- Riot Games announces End of Year Charity Voting campaign
- Mobile Legends X SpongeBob Collab Skins: All MLBB skins, prices and availability
- Deneme Bonusu Veren Siteler – En Gvenilir Bahis Siteleri 2025.4338
- Supercell to resurrect Clash Mini with Clash Royale in June 2025 as part of a new strategy platform
2025-11-30 10:45