Author: Denis Avetisyan
A new framework empowers robots to identify graspable objects and perform tasks in complex scenes simply by interpreting natural language instructions.

OVAL-Grasp leverages large language and vision models for zero-shot task-oriented affordance localization and grasping.
Robots often struggle to reliably manipulate objects in real-world environments due to challenges in identifying appropriate grasp locations based on task requirements. To address this, we introduce OVAL-Grasp: Open-Vocabulary Affordance Localization for Task Oriented Grasping, a novel zero-shot framework that leverages large language and vision-language models to localize and grasp objects based on natural language task descriptions. Our approach achieves significantly improved performance over existing methods in identifying correct grasp locations-reaching 78.3% success in real-world experiments-and demonstrates robustness to occlusion and reliance on visual features. Could this modular, open-vocabulary approach unlock more adaptable and intelligent robotic manipulation capabilities in unstructured environments?
The Challenge of Robotic Manipulation
Conventional robotic grasping systems frequently encounter difficulties when operating in environments mirroring the complexities of the real world. Unlike controlled laboratory settings, everyday scenes are rarely neatly organized; instead, they present cluttered arrangements of objects, varying lighting conditions, and unpredictable occlusions. This poses a considerable challenge for robots relying on pre-programmed grips or simplistic visual analysis, as these methods often fail to reliably identify secure grasp points amidst the chaos. The difficulty isn’t merely identifying an object, but discerning which portions of that object – or even neighboring objects – are suitable for manipulation without causing instability or collisions. Consequently, even seemingly straightforward tasks, such as retrieving a specific item from a crowded table, can prove remarkably difficult for robots employing traditional grasping techniques.
Current robotic grasping systems frequently demand vast amounts of training data to achieve even moderate success, a limitation that hinders their deployment in dynamic, unstructured environments. These systems often excel with objects they’ve been specifically trained on, but struggle significantly when presented with novel items or variations in object pose, lighting, or background clutter. This lack of generalization stems from an over-reliance on recognizing specific visual features rather than understanding the underlying physics of grasping and manipulation. Consequently, a robot trained to pick up a red block may fail completely when presented with a blue one, or even the same red block in a slightly different orientation, severely restricting their adaptability and usefulness in real-world applications where unpredictable scenarios are the norm.
True robotic autonomy demands more than simply detecting and grasping objects; it requires grasping for a reason. Current robotic systems often excel at isolating an object and securing a hold, but struggle to integrate that action into a larger, purposeful sequence. This deficiency stems from a reliance on pre-programmed grasps or extensive training datasets that fail to account for the infinite variability of real-world tasks. A robot tasked with, for example, assembling a circuit board doesn’t just need to pick up a resistor – it needs to grasp it in a way that facilitates precise placement, avoiding damage to delicate components. Achieving this “task-oriented grasping” necessitates advanced planning algorithms, real-time feedback mechanisms, and an understanding of how a grasp impacts subsequent actions, pushing the boundaries of robotic intelligence beyond mere manipulation and toward genuine problem-solving.

OVAL-Grasp: A Principled Approach to Grasp Selection
OVAL-Grasp leverages the complementary strengths of Large Language Models (LLMs) and Vision Language Models (VLMs) to determine object affordances, specifically identifying potential actions applicable to an object. VLMs process visual input to recognize objects and their features, while LLMs provide reasoning capabilities to interpret those features in the context of possible manipulations. This combined approach allows the system to move beyond simple object recognition and towards understanding how an object can be used; for example, differentiating between an object that can be “picked up” versus one that can be “pushed” or “turned”. The integration enables OVAL-Grasp to infer affordances from both visual observations and textual descriptions, creating a more robust and versatile understanding of object functionality.
OVAL-Grasp moves beyond purely geometric analyses of grasp stability by representing complex manipulation tasks as interactions between specific object parts. Traditional robotic grasping systems often evaluate grasp feasibility based on overall object shape and collision avoidance; however, OVAL-Grasp identifies key functional parts and reasons about how interactions between those parts enable or constrain a given action. This decomposition allows the system to infer affordances-what actions are possible with the object-based on the relationships between its components, resulting in a more nuanced and robust understanding of grasp requirements than methods relying solely on global geometric properties. The framework determines which part interactions are critical for successful manipulation, enabling stable grasps even for objects with complex geometries or unconventional shapes.
OVAL-Grasp employs ContactGraspNet to initially generate a set of potential grasp configurations for an object. These candidate grasps are then evaluated using a confidence heatmap, which assigns a score to each grasp based on the predicted stability and reliability of the contact points between the robotic gripper and the object’s parts. The heatmap utilizes information derived from the object’s geometry and the predicted interaction forces to quantify the likelihood of a successful and stable grasp, effectively filtering out suboptimal or unstable configurations before execution. This scoring mechanism prioritizes grasps with high part confidence, leading to improved robustness and success rates in robotic manipulation tasks.
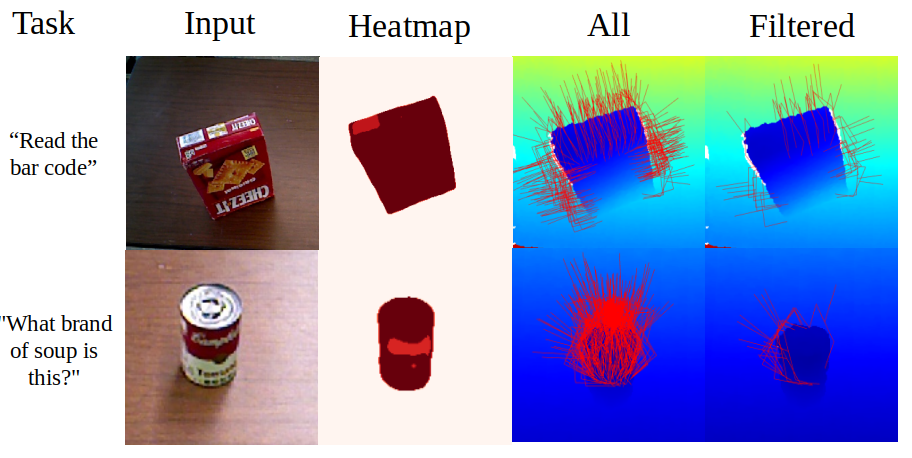
Empirical Validation: Demonstrating Superior Performance
OVAL-Grasp demonstrates a high degree of accuracy in identifying the specific parts of an object required for a successful grasp. This part selection success is a critical component of the system, enabling it to focus on the manipulable elements within a scene. Quantitative results indicate OVAL-Grasp outperforms comparative methods, achieving a 35% improvement in part selection accuracy when evaluated against models like GraspGPT and ShapeGrasp. This accurate identification of task-relevant parts contributes directly to the overall grasp planning and execution capabilities of the system, facilitating robust performance in complex environments.
Evaluations conducted using RGB-D imagery demonstrate OVAL-Grasp’s robust performance in grasp planning. Quantitative results indicate a statistically significant improvement in both part selection and grasp success rates when compared to existing methods. Specifically, OVAL-Grasp achieves a 35% higher part selection success rate and a 21.7% improvement in overall grasp success relative to benchmarks including GraspGPT and ShapeGrasp. These gains were observed across complex scenes, indicating the model’s ability to generalize and maintain performance in challenging environments.
Ablation studies were conducted employing large language models (LLMs) including GPT-4o, GPT-3.5 Turbo, and DeepSeek-R1, alongside part segmentation models such as PartGLEE and VLPart, to quantify the individual contribution of each component within the OVAL-Grasp framework. These studies systematically removed or replaced specific modules, evaluating the resulting impact on both part selection and grasp success rates. Results indicated that the LLM component is critical for reasoning about object affordances and generating viable grasp configurations, while the part segmentation models-particularly VLPart-significantly influence the accuracy of part selection. Performance degradation observed when removing either component highlighted their synergistic relationship and validated the design choices made in the OVAL-Grasp architecture. Quantitative analysis of these ablations provided insight into the relative importance of each module, guiding further optimization efforts.

Implications for Autonomous Systems and Future Research
The advent of OVAL-Grasp signifies a substantial leap toward practical robotic autonomy through its remarkable zero-shot capabilities. Traditionally, deploying robots in novel settings demands extensive, and often prohibitively expensive, task-specific training; each new environment or object necessitates a complete relearning process. However, OVAL-Grasp bypasses this limitation by leveraging pre-existing knowledge and adaptable reasoning, allowing robots to successfully execute tasks in completely unseen circumstances without any prior training. This capability dramatically reduces development time and costs, facilitating rapid deployment in dynamic environments such as warehouses, factories, or even domestic settings, and promises to unlock a new era of flexible and readily adaptable robotic solutions.
The advent of OVAL-Grasp promises a significant leap forward for robotic deployment across several critical sectors, notably manufacturing, logistics, and healthcare. These fields consistently demand a high degree of adaptability, as robots often encounter unpredictable conditions and varying task requirements; traditional robotic systems struggle with such dynamism. OVAL-Grasp, however, offers a pathway to overcome these limitations, envisioning robots capable of seamlessly transitioning between tasks and environments without extensive reprogramming. In manufacturing, this translates to flexible assembly lines; in logistics, it enables efficient navigation of complex warehouses; and in healthcare, it could facilitate delicate assistance during surgery or personalized patient care – all driven by a framework that prioritizes real-time adjustment and intelligent problem-solving in previously challenging scenarios.
Ongoing development of OVAL-Grasp centers on enhancing its capacity for complex reasoning, moving beyond immediate perceptual inputs to anticipate and plan for multi-step interactions with objects. Researchers are actively investigating the synergistic potential of combining OVAL-Grasp’s foundational zero-shot abilities with reinforcement learning techniques. This integration promises a system capable of continuous self-improvement; by learning from experience, the robot can refine its grasp strategies, optimize movements, and adapt to nuanced environmental changes-effectively moving from skillful initial attempts to consistently reliable performance over time. This iterative process holds the key to unlocking truly autonomous robotic manipulation in dynamic, real-world settings.

The pursuit of robust robotic manipulation, as demonstrated by OVAL-Grasp, necessitates a fundamentally correct approach to affordance localization. The framework’s success isn’t merely about achieving high accuracy on benchmark datasets, but rather about establishing a provable link between visual perception and action. This echoes the sentiment of Henri Poincaré, who stated, “Mathematics is the art of giving reasons.” OVAL-Grasp strives for precisely that – a reasoned, mathematically grounded understanding of how objects can be interacted with, moving beyond empirical success towards a system built on logical completeness. The ability to generalize to novel scenarios, a key aspect of zero-shot learning highlighted in the study, stems from this emphasis on underlying principles rather than memorized patterns.
What’s Next?
The presented framework, while demonstrating a capacity for zero-shot generalization, ultimately rests upon the somewhat precarious foundation of large language models. These models, prodigious as they are, remain fundamentally stochastic parrots – fluent in syntax, but deficient in genuine understanding. The true test lies not in identifying a grasp, but in proving its optimality – a demonstration conspicuously absent from current evaluations. To claim ‘success’ based solely on observed task completion is, frankly, a logical fallacy; correlation does not imply causation, nor does it guarantee robustness.
Future work must therefore shift from empirical observation toward formal verification. The definition of ‘affordance’ itself requires rigorous mathematical formulation, allowing for provable guarantees regarding grasp stability and task success. Simply scaling model parameters will yield diminishing returns. The problem is not one of data quantity, but of conceptual clarity. A solution devoid of a formal, provable basis remains merely a sophisticated heuristic, prone to unpredictable failures in novel environments.
Ultimately, the pursuit of truly intelligent robotic manipulation demands a move beyond the current paradigm of ‘learning’ and toward a synthesis of symbolic reasoning and geometric constraint satisfaction. Until then, the elegant articulation of a grasp remains distinct from its mathematical justification, and the field will continue to operate on the level of observed effect, rather than demonstrable cause.
Original article: https://arxiv.org/pdf/2511.20841.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Clash Royale Furnace Evolution best decks guide
- Chuck Mangione, Grammy-winning jazz superstar and composer, dies at 84
- December 18 Will Be A Devastating Day For Stephen Amell Arrow Fans
- Clash Royale Witch Evolution best decks guide
- Now That The Bear Season 4 Is Out, I’m Flashing Back To Sitcom Icons David Alan Grier And Wendi McLendon-Covey Debating Whether It’s Really A Comedy
- All Soulframe Founder tiers and rewards
- Riot Games announces End of Year Charity Voting campaign
- Deneme Bonusu Veren Siteler – En Gvenilir Bahis Siteleri 2025.4338
- BLEACH: Soul Resonance Character Tier List
2025-11-29 14:34