Author: Denis Avetisyan
A new framework distributes the task of generating synthetic data across multiple agents, dramatically increasing throughput and overcoming the limitations of centralized approaches.
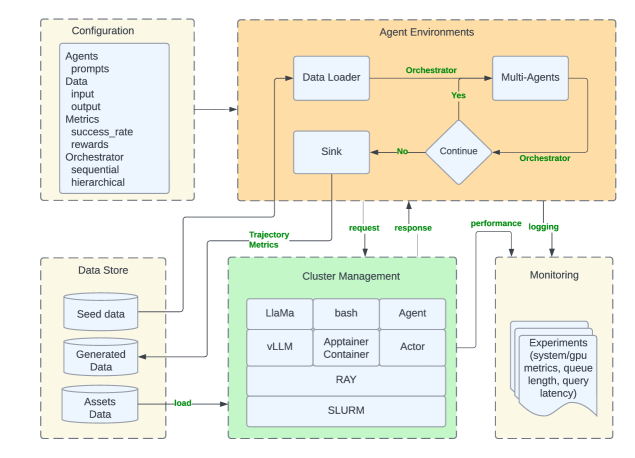
Matrix is a scalable, peer-to-peer runtime for multi-agent synthetic data generation leveraging asynchronous execution and a distributed architecture.
Despite the growing need for large-scale, high-quality datasets to train modern AI models, current multi-agent synthetic data generation frameworks often suffer from scalability issues or domain-specific limitations. This paper introduces Matrix: Peer-to-Peer Multi-Agent Synthetic Data Generation Framework, a decentralized runtime that overcomes these challenges by representing workflows as serialized messages passed between lightweight agents. Our peer-to-peer design, built on Ray, achieves up to 15x higher data generation throughput compared to centralized approaches without sacrificing output quality. Could this architecture unlock new possibilities for efficiently creating diverse and complex datasets for a wider range of AI applications?
The Evolving Landscape of Agentic Systems
Despite the remarkable fluency and breadth of knowledge exhibited by Large Language Models (LLMs), these systems frequently falter when confronted with tasks demanding intricate, sequential reasoning. While proficient at identifying patterns and generating text based on existing data, LLMs often struggle to decompose complex problems into manageable steps, maintain context across multiple operations, or effectively plan and execute multi-stage solutions. This limitation stems from their inherent architecture – primarily focused on predicting the next token in a sequence – which prioritizes statistical correlation over genuine understanding and deliberate problem-solving. Consequently, even relatively straightforward challenges requiring logical deduction, planning, or the integration of diverse information sources can expose the boundaries of LLM capabilities, highlighting the need for innovative approaches to augment their reasoning abilities.
Efforts to enhance Large Language Models (LLMs) through sheer scale – increasing parameters and training data – are encountering the law of diminishing returns. While initially effective, simply making models larger yields progressively smaller improvements in performance on complex reasoning tasks. This plateau in capability is driving research toward alternative architectural designs, most notably multi-agent systems. These systems distribute cognitive load across numerous specialized agents, each focused on a specific sub-problem, and allow for collaborative problem-solving. By breaking down intricate challenges into manageable components and fostering interaction between these agents, researchers aim to surpass the limitations inherent in monolithic LLMs and unlock genuinely robust and adaptable artificial intelligence.
Agentic systems represent a paradigm shift in artificial intelligence, moving beyond the constraints of monolithic large language models. These systems decompose complex problems into smaller, manageable tasks, assigning each to a specialized agent with a defined role and expertise. This distributed reasoning approach allows for parallel processing and focused computation, circumventing the limitations of sequential processing inherent in single LLMs. By fostering collaboration and information exchange between agents-through mechanisms like shared memory or communication protocols-the system can leverage collective intelligence to tackle multifaceted challenges. This modularity not only enhances problem-solving capabilities but also improves the system’s robustness and adaptability, as individual agents can be updated or replaced without disrupting the entire architecture. Ultimately, agentic systems aim to replicate the efficiency and flexibility of human cognitive processes by distributing workload and capitalizing on diverse skillsets.
Matrix: A Scalable Foundation for Agentic Experimentation
Matrix is a distributed runtime environment engineered to support scalable experimentation and synthetic data generation utilizing multiple interacting agents. The system is designed to overcome limitations inherent in centralized approaches by distributing the computational workload across a cluster of machines. This architecture enables parallel execution of agent tasks, facilitating the creation of large-scale synthetic datasets and the evaluation of complex multi-agent systems. The runtime handles agent lifecycle management, inter-agent communication, and data flow, providing a unified platform for researchers and developers to conduct experiments with a high degree of scalability and reproducibility.
Matrix optimizes performance through efficient data-to-data transformation techniques. Batch processing is employed to reduce overhead by aggregating multiple data points into single operations, increasing throughput. Furthermore, row-level scheduling allows for parallel processing of individual data rows, maximizing resource utilization and enabling finer-grained control over data transformations. This combination of batching and row-level scheduling minimizes latency and maximizes the overall speed of synthetic data generation and experimentation workflows, contributing to the platform’s scalability.
Matrix is designed for interoperability with existing high-performance computing infrastructure. Specifically, it leverages SLURM for workload scheduling and resource management, enabling efficient distribution of agentic tasks across clusters. Apptainer containers are utilized to ensure reproducibility and portability of experiments by packaging agent code and dependencies. Furthermore, Matrix integrates with Ray, a distributed execution framework, to facilitate scalable and parallel execution of agent interactions and data processing pipelines. This integration allows Matrix to harness the capabilities of established tools, providing a robust and flexible platform for synthetic data generation and experimentation within existing computational environments.
Matrix employs a peer-to-peer (P2P) architecture where agents communicate directly with each other, bypassing a central server. This direct communication methodology results in a substantial performance increase, achieving up to 15.4x higher throughput in synthetic data generation compared to traditional centralized systems. Crucially, this improvement in throughput is achieved while maintaining comparable output data quality as observed in centralized approaches, indicating that the P2P design does not compromise the fidelity of the generated synthetic data. The elimination of a central point of control reduces bottlenecks and enables parallelized processing, contributing to the observed scalability and efficiency gains.

Generating and Evaluating Agentic Tasks and Behaviors
TaskCraft is an automated system designed to produce complex, multi-step tasks requiring the use of multiple tools. This capability facilitates a systematic and repeatable evaluation of agent performance across a range of scenarios. The generated tasks are not simply single requests, but rather sequences of actions an agent must perform, utilizing various tools to achieve a defined goal. By controlling the complexity and the required toolset within these generated tasks, researchers and developers can rigorously assess an agent’s ability to plan, execute, and adapt its behavior, providing quantifiable metrics for performance comparison and improvement.
AgentSynth and SWE-Synth are automated systems designed to facilitate large-scale testing and improvement of agent-based systems. AgentSynth generates a diverse range of tasks for agents to perform, allowing for comprehensive evaluation of their capabilities across varying scenarios. Complementarily, SWE-Synth focuses on synthesizing verifiable bug fixes for software errors. It operates by automatically generating patches and verifying their correctness through testing, thereby providing a scalable method for identifying and resolving software defects. Both systems prioritize automation and scalability to address the challenges of evaluating and improving complex agentic systems and software.
Agent Instruct is a system designed to efficiently generate datasets consisting of multi-turn interactions between a user and an agent. These datasets are composed of instructions provided by the user and corresponding responses generated by the agent, and are essential for supervised fine-tuning and reinforcement learning of agent behaviors. The system allows for programmatic control over dataset characteristics, including instruction complexity, topic diversity, and the desired length of conversational turns. By enabling the creation of large-scale, high-quality interaction datasets, Agent Instruct facilitates the training of agents capable of engaging in more complex and nuanced dialogues, and supports systematic evaluation of performance improvements as agent capabilities evolve.
Performance evaluations demonstrate that the Matrix framework, utilizing the Collaborative Reasoner, achieves a 6.8x increase in token throughput compared to its official implementation. This improvement represents a substantial gain in processing efficiency, allowing for significantly faster execution of agentic tasks and behaviors. The Collaborative Reasoner’s architecture facilitates parallelization and optimized token handling, directly contributing to this observed performance boost. This increase in throughput enables more extensive testing and evaluation of agent capabilities within a given timeframe and with comparable resources.
Demonstrating Scalability and Impact in Agentic Intelligence
Tau2-Bench represents a significant advancement in evaluating the capabilities of conversational agents, particularly in complex, interactive scenarios. Unlike traditional benchmarks focused on single-turn responses, Tau2-Bench assesses performance within dual-control environments, where both a human and an agent collaboratively navigate a task. This setup demands agents not only generate coherent and relevant responses, but also effectively interpret human guidance and adapt their strategies accordingly. The benchmark utilizes a diverse set of tasks requiring multi-turn interaction, challenging agents to maintain context, resolve ambiguity, and exhibit proactive problem-solving skills. By pushing the boundaries of agent interaction in these collaborative settings, Tau2-Bench provides a more realistic and nuanced measure of agentic intelligence, fostering development toward truly helpful and adaptive conversational AI.
SWE-Agent showcases a practical application of advanced agentic systems by tackling the complexities of real-world software engineering, with a specific focus on automated bug resolution. This system doesn’t merely identify errors, but actively diagnoses the root cause and implements corrective code changes, demonstrating a level of autonomy previously unseen in automated software maintenance. Through rigorous testing on established codebases, SWE-Agent exhibits the potential to significantly reduce developer workload and accelerate the software development lifecycle. The system leverages large language models to understand code context, generate potential fixes, and validate those fixes through testing, effectively mimicking the problem-solving process of a human engineer. This approach marks a shift from passive code analysis tools to proactive, self-correcting agents capable of independent software refinement.
The pursuit of truly intelligent agents hinges on robust reasoning capabilities, and the NaturalReasoning dataset represents a significant leap forward in fostering this crucial skill within large language models. This expansive resource, meticulously constructed at a large scale, moves beyond simple pattern recognition and encourages LLMs to engage in complex, multi-step reasoning processes. By providing a diverse range of challenging scenarios, NaturalReasoning doesn’t just test an LLM’s existing abilities; it actively drives progress in areas like commonsense reasoning, logical deduction, and problem-solving. The dataset’s design prioritizes not just the correctness of an answer, but also the clarity and justification of the reasoning path taken, offering valuable insights into how LLMs arrive at their conclusions and pinpointing areas for further refinement in agent intelligence.
Recent advancements in agentic intelligence have been dramatically propelled by infrastructure capable of handling massive computational demands; notably, the Matrix system, built upon the vLLM framework, achieved the generation of 185,376,127 tokens utilizing a cluster of 13 H100 nodes. This represents a substantial leap in processing capacity, allowing for the concurrent handling of 1,500 tasks-a threefold increase over previous benchmarks of 500 concurrent tasks. The scale of this operation not only demonstrates the potential for accelerating agent training and deployment but also establishes a new standard for evaluating and scaling agentic systems designed for complex, real-world applications, paving the way for more responsive and capable artificial intelligence.
Charting a Course for Future Advancements in Agentic Systems
The future of agentic systems increasingly relies on the strategic use of synthetic data, particularly when leveraged within a framework like the Matrix. Current machine learning approaches often demand vast datasets for effective training, a limitation that hinders the development of agents capable of operating reliably in diverse, real-world scenarios. Synthetic data generation offers a compelling solution by allowing researchers to create customized training environments and edge cases that would be difficult or impossible to collect through real-world observation. This approach not only expands the scope of training data but also enables precise control over data distribution, leading to agents exhibiting enhanced robustness and generalization capabilities. By intelligently crafting synthetic experiences, developers can proactively address potential failure modes and equip agents with the adaptability needed to thrive in unpredictable environments, ultimately accelerating progress beyond the constraints of purely observational learning.
Large-scale multi-agent systems often face significant communication bottlenecks as the number of interacting agents increases; however, innovative message offloading techniques are proving vital for optimizing efficiency. These methods strategically reduce the volume of data transmitted by prioritizing essential information and summarizing or compressing less critical messages. Recent experiments demonstrate that implementing such techniques can reduce network bandwidth consumption by as much as 20%, allowing for more scalable and responsive agent interactions. This optimization is achieved through algorithms that intelligently determine which agents require complete message details and which can function effectively with abstracted summaries, thereby minimizing redundant data transfer and maximizing overall system performance.
The advancement of agentic systems hinges not only on novel algorithms but also on the rigorous tools used to assess their performance. Current evaluation metrics often fall short of capturing the nuances of complex, autonomous behavior, necessitating the creation of benchmarks that prioritize generalization, robustness, and long-term adaptability. Future work must focus on developing standardized, yet flexible, evaluation suites capable of measuring an agent’s proficiency across diverse and unpredictable environments. This includes moving beyond task completion rates to assess qualities like efficient resource utilization, safe exploration strategies, and the ability to collaborate effectively with other agents or humans. Without such comprehensive benchmarks, it remains difficult to objectively compare different approaches, pinpoint limitations, and ultimately drive meaningful progress in the field of agentic intelligence.
The future of artificial intelligence hinges on the synergistic potential arising from the intersection of agentic systems with other prominent AI fields. Combining the autonomous decision-making of agents with the pattern recognition of deep learning, the reasoning capabilities of knowledge graphs, and the generative power of large language models creates a powerful framework for tackling complex challenges. This convergence isn’t simply about combining tools; it’s about fostering a new paradigm where agents can not only perceive and act but also learn, reason, and create – leading to solutions previously unattainable. For instance, an agent leveraging a language model could interpret ambiguous instructions, while a knowledge graph provides contextual awareness for more informed actions. Such integrated systems promise breakthroughs in areas ranging from scientific discovery and personalized medicine to robotics and automated problem-solving, ushering in an era of truly intelligent and adaptable artificial entities.
The design of Matrix, with its emphasis on a peer-to-peer architecture, highlights the importance of systemic understanding. The framework doesn’t simply address synthetic data generation; it reconsiders the fundamental structure of how such systems operate, shifting from centralized bottlenecks to distributed asynchronous execution. This holistic approach resonates with Donald Knuth’s observation: “Premature optimization is the root of all evil.” Matrix prioritizes a well-structured, scalable runtime over isolated performance gains, recognizing that true efficiency emerges from elegant design and a thorough understanding of the interplay between components. The framework’s success isn’t merely about throughput; it’s a testament to the power of thoughtful, systemic design.
What Lies Ahead?
The pursuit of scalable synthetic data generation, as exemplified by Matrix, inevitably highlights a fundamental tension. Each new dependency – each agent, each peer-to-peer connection – introduces a hidden cost to the system’s overall freedom. While Matrix demonstrably alleviates throughput bottlenecks inherent in centralized architectures, the question remains: at what level of complexity does distributed execution itself become the limiting factor? The elegance of a peer-to-peer design lies in its theoretical decentralization, yet practical implementations always grapple with the realities of network latency, message overhead, and the emergent behaviors of numerous interacting components.
Future work must address not only the scale of these multi-agent systems, but also their robustness. Asynchronous execution, while enabling higher throughput, introduces challenges for debugging, verification, and ensuring data consistency. A system’s structure dictates its behavior; therefore, rigorous formal methods for reasoning about the emergent properties of these distributed agent networks are crucial. Simply achieving speed is insufficient; the synthetic data must be demonstrably useful, and that utility is inextricably linked to the integrity of the generative process.
Ultimately, the true measure of success will not be the size of the dataset produced, but the extent to which these synthetic worlds accurately reflect, and allow exploration of, the complexities they are meant to model. The framework’s potential extends beyond mere data augmentation; it offers a platform for experimenting with decentralized intelligence itself. Whether that potential is realized depends on a willingness to confront the inherent trade-offs between scale, complexity, and control.
Original article: https://arxiv.org/pdf/2511.21686.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Best Arena 9 Decks in Clast Royale
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Clash Royale Furnace Evolution best decks guide
- Clash Royale Witch Evolution best decks guide
- Best Hero Card Decks in Clash Royale
2025-11-29 07:46