Author: Denis Avetisyan
New research reveals that even small variations in app design and content can dramatically impact the reliability of UI agents designed to automate tasks.

OpenApps, a novel simulation framework, systematically measures UI agent performance across a spectrum of app variations to quantify and address this fragility.
While autonomous UI agents hold promise for app interaction, current reliability evaluations fail to account for the inevitable variations in real-world app design and content. To address this limitation, we introduce OpenApps, a lightweight, open-source ecosystem for systematically measuring UI agent performance across thousands of configurable app instances, as detailed in ‘OpenApps: Simulating Environment Variations to Measure UI-Agent Reliability’. Our findings reveal substantial fluctuations in task success-over 50% for some agents-highlighting that reliability within a fixed app does not guarantee consistent performance across variations. This raises a critical question: how can we build truly robust UI agents capable of adapting to the dynamic and unpredictable nature of app environments?
The Illusion of Fluency: Why UI Agents Remain Fragile
Contemporary user interface agents, powered by foundation models, frequently exhibit unexpectedly fragile performance. Even subtle alterations to an application’s visual layout, button labeling, or content arrangement can dramatically disrupt their ability to complete tasks successfully. This brittleness arises because these agents often prioritize recognizing superficial visual patterns over genuinely understanding the underlying functionality and intended user goals of the interface. Consequently, a seemingly minor change – such as a color adjustment or a slight repositioning of elements – can mislead the agent, causing it to misinterpret instructions or fail to locate essential controls, ultimately leading to unreliable and unpredictable user experiences.
Current user interface agents, despite their apparent fluency, often operate by identifying visual patterns and surface-level similarities rather than genuinely comprehending the underlying logic of an application or the user’s goals. This reliance on superficial matching renders them vulnerable to even slight alterations in an app’s layout, text, or content; an agent trained to click a button labeled “Submit” may fail when that label is changed to “Send,” even if the button’s function remains identical. Consequently, these agents struggle with dynamic interfaces or apps featuring localized content, demonstrating a lack of true understanding and an inability to generalize beyond the specific examples encountered during training. This pattern-matching approach contrasts sharply with human interaction, where intent and contextual understanding allow for flexible adaptation to novel situations and interface variations.
Contemporary evaluation techniques for user interface agents prove inadequate in anticipating the breadth of real-world application behaviors, leading to inconsistent performance. Studies reveal a substantial vulnerability: agent reliability can shift dramatically-by more than 50%-when presented with even subtle alterations in an application’s layout or content. This instability arises because current testing largely focuses on a limited set of pre-defined scenarios, failing to account for the ‘long tail’ of potential interface variations encountered during genuine user interaction. Consequently, agents may perform flawlessly under controlled conditions but falter unpredictably when faced with the dynamic and often unpredictable nature of modern applications, ultimately undermining user trust and the promise of seamless automation.

OpenApps: A System for Rigorous and Scalable Testing
OpenApps is a system built on open-source principles to facilitate large-scale application testing. It functions by programmatically generating numerous, distinct versions of an application – potentially reaching thousands – each defined by a clear and accessible logic and internal state. This generation process isn’t random; it’s designed to systematically explore the application’s parameter space, varying elements like visual presentation, data content, and configurable settings. The resulting ‘app variations’ are fully defined in code, allowing for reproducibility, auditability, and precise control over the testing environment. This approach contrasts with manual or ad-hoc testing by providing a scalable and deterministic method for exercising an application’s functionality across a wide range of conditions.
OpenApps generates a comprehensive test suite for UI agents through the creation of App Variations, which are systematically altered versions of an application. These variations are produced by modifying parameters related to app appearance – including visual elements and themes – content, such as text, images, and data displayed, and configuration settings that influence application behavior. This systematic variation allows for testing across a broad range of potential app states, increasing the robustness of UI agents by exposing them to diverse and often unexpected scenarios. The resulting suite facilitates comprehensive evaluation of an agent’s ability to generalize and perform reliably under varying conditions, exceeding the limitations of manually created test cases.
OpenApps leverages BrowserGym to facilitate interaction with and testing of the numerous app variations it generates. This integration allows developers to define action spaces – the set of possible user interactions – within BrowserGym and then apply those actions across a diverse range of OpenApps instances. BrowserGym handles the complexities of interacting with each app, abstracting away differences in UI elements and application state. Consequently, a single action definition can be used to test functionality across thousands of automatically generated app configurations, significantly increasing test coverage and reducing the need for manually crafted test scripts for each variation.

Beyond Simple Accuracy: Diagnosing the Roots of Failure
OpenApps facilitates the identification of specific failure modes in UI agents beyond overall accuracy metrics. Analysis within the platform reveals two common issues: Invalid Actions, which occur when an agent attempts an operation unsupported by the current application state, and Looping Behavior, stemming from flawed decision-making processes that cause the agent to repeatedly perform the same actions. These failure modes are logged and categorized by OpenApps, allowing developers to pinpoint the root causes of agent instability and improve robustness. Identifying these specific issues is crucial for targeted improvements, as generalized accuracy scores do not provide granular enough data for effective debugging and optimization.
Analysis of UI agent performance indicates a consistent difficulty with Content Variations within applications. This struggle isn’t simply a matter of visual differences, but demonstrates a fundamental limitation in the agent’s ability to extract and process semantic meaning from UI elements. When the textual content or data presented within an application changes – even if the underlying functionality remains identical – agent success rates decline significantly. This suggests that current models often rely on surface-level pattern matching rather than a robust understanding of the application’s purpose and the meaning of the displayed information, hindering their ability to generalize across different content states.
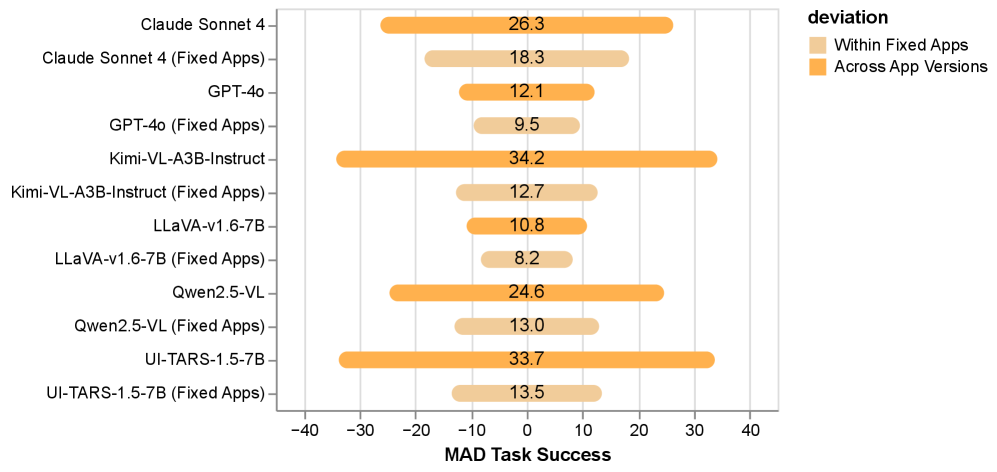
UI agents exhibit reduced reliability when confronted with superficial visual changes within applications. Analysis indicates that alterations in appearance, such as color schemes or icon styles, can significantly distract agents, leading to decreased task success rates. These variations do not alter the underlying functionality of the application, yet they demonstrably impact agent performance, suggesting a reliance on visual cues rather than a robust understanding of semantic content. This sensitivity to appearance variations is observed across multiple models, including Qwen2.5-VL, Kimi-VL, and UI-Tars, and contributes to a higher standard deviation in task completion when agents are evaluated across diverse app appearances.
OpenApps integration with simulators facilitates large-scale UI agent reliability testing on complex, multi-step tasks. Quantitative analysis demonstrates a significant impact of application variations on agent performance; the standard deviation of task success rates is approximately two times higher when agents are evaluated across diverse app versions compared to testing within a single, fixed app version. This performance disparity was observed consistently across multiple visual language models, including Qwen2.5-VL, Kimi-VL, and UI-Tars, indicating a general vulnerability to changes in application appearance and structure.
Testing of the UI-Tars agent revealed a significant performance impact related to visual theme. Specifically, loop counts-a metric indicating repeated, unproductive action sequences-nearly doubled when the application interface was switched to a dark theme. This indicates a sensitivity to appearance variations, suggesting the agent’s decision-making process is influenced by superficial visual changes rather than underlying semantic content. The observed increase in loop counts implies reduced efficiency and a higher probability of task failure in applications employing dark themes when using the UI-Tars agent.

Towards Truly Robust UI Agents: A Future of Resilience
OpenApps establishes a comprehensive framework for assessing and bolstering the dependability of user interface (UI) agents. This methodology moves beyond simple testing by systematically generating a diverse range of application states and variations – encompassing differences in layout, content, and dynamic behavior. Through this rigorous exploration, potential failure points in UI agent performance are proactively identified and addressed before real-world deployment. The scalability of OpenApps allows for evaluation across numerous applications and complex scenarios, providing a statistically significant measure of agent reliability. Ultimately, this approach not only minimizes frustrating user experiences caused by erratic automation but also substantially lowers the long-term costs associated with maintaining and troubleshooting unpredictable UI agents in production environments.
A robust approach to UI agent reliability hinges on proactive failure identification through comprehensive app variation testing. Rather than reacting to issues post-deployment, this methodology systematically explores the vast landscape of potential app states – considering differences in layouts, content, and even unexpected user interactions. By subjecting agents to this rigorous examination before release, developers can pinpoint critical failure modes and implement preventative measures. This preemptive strategy isn’t simply about bug fixing; it’s about building agents that exhibit consistent performance across a diverse and ever-changing application ecosystem, ultimately fostering greater user trust and minimizing costly maintenance interventions. The technique effectively shifts the paradigm from reactive troubleshooting to proactive resilience.
A significant benefit of proactively addressing UI agent reliability extends beyond simply improving how users interact with technology. By identifying and mitigating potential failure points before deployment-through methods like OpenApps-organizations can substantially lower long-term operational costs. Unreliable agents frequently necessitate extensive troubleshooting and repeated maintenance interventions, diverting valuable engineering resources. Reducing these interventions, and the associated downtime, translates directly into cost savings, allowing development teams to focus on innovation rather than firefighting. This preventative strategy fosters a more sustainable and economically viable approach to UI automation, ultimately delivering a better return on investment and a smoother experience for end-users.
Ongoing research prioritizes the creation of UI agents capable of graceful degradation and proactive adaptation to dynamic application environments. Current systems often struggle when confronted with even minor alterations in app interfaces or functionality; future iterations aim to overcome this fragility through techniques like continual learning and meta-learning. These agents will not simply react to changes, but rather anticipate potential disruptions by building internal models of app behavior and leveraging transfer learning from previously encountered variations. This proactive approach promises significantly enhanced resilience, reducing the need for frequent retraining and minimizing user disruption when applications inevitably evolve, ultimately fostering a more robust and dependable user experience.
The pursuit of robust UI agents, as detailed in the introduction of OpenApps, necessitates a move beyond curated datasets and towards dynamic, variable testing environments. This echoes Tim Bern-Lee’s sentiment: “The web is more a social creation than a technical one.” OpenApps directly embodies this principle by simulating the ever-shifting landscape of application interfaces and content. By systematically introducing variations, the framework acknowledges the web’s inherent fluidity-its resistance to static definition. The framework’s emphasis on measuring task success across these variations isn’t simply about improving agent performance; it’s about building systems that gracefully adapt to the unpredictable nature of the digital environment, aligning with the web’s fundamentally social and evolving character.
What Remains?
The introduction of OpenApps clarifies a simple, previously obscured point: UI agent reliability is not a fixed property, but a fluctuating value contingent upon the precise instantiation of its digital environment. This is less a discovery than a necessary correction of presumptions. The framework itself is merely a tool to measure what was always true, yet often ignored. Future iterations should not focus on increasing the number of simulated variations – complexity for its own sake is a distraction – but on identifying the minimal set of variations that reliably differentiate robust agents from those merely lucky in their testing.
A fundamental limitation persists: simulation, however sophisticated, remains a reduction of reality. The true measure of an agent’s reliability lies not in its performance across a multitude of synthetic apps, but in its consistent success within the singular, chaotic, and unpredictable landscape of actual user interaction. OpenApps, therefore, should be viewed as a triage system, identifying agents unworthy of deployment in real-world scenarios, rather than certifying their ultimate competence.
The ultimate question is not whether an agent can succeed, but whether its failures are gracefully contained. A perfectly reliable agent is an impossibility; a predictably failing one is a design goal. The pursuit of perfection is a fool’s errand. The intelligent approach is to acknowledge inherent fallibility and to engineer systems that anticipate, and accommodate, inevitable imperfection.
Original article: https://arxiv.org/pdf/2511.20766.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Clash Royale Furnace Evolution best decks guide
- Chuck Mangione, Grammy-winning jazz superstar and composer, dies at 84
- December 18 Will Be A Devastating Day For Stephen Amell Arrow Fans
- Clash Royale Witch Evolution best decks guide
- Now That The Bear Season 4 Is Out, I’m Flashing Back To Sitcom Icons David Alan Grier And Wendi McLendon-Covey Debating Whether It’s Really A Comedy
- All Soulframe Founder tiers and rewards
- Riot Games announces End of Year Charity Voting campaign
- Deneme Bonusu Veren Siteler – En Gvenilir Bahis Siteleri 2025.4338
- BLEACH: Soul Resonance Character Tier List
2025-11-29 06:11