Author: Denis Avetisyan
Researchers have developed a novel approach to robot learning that allows machines to acquire manipulation skills from diverse video sources, bridging the gap between human demonstrations and robotic execution.
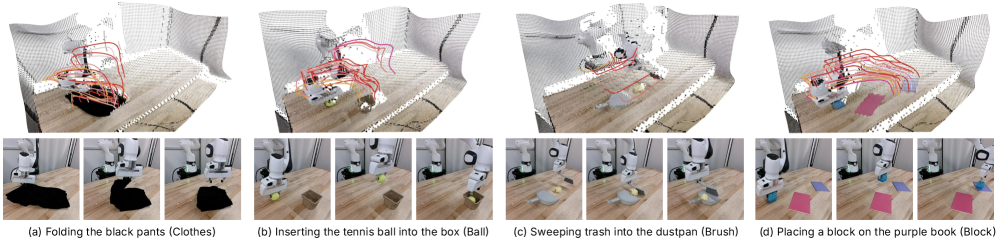
TraceGen represents motion in a compact 3D trace space, enabling efficient skill transfer between robots and from human video data.
Learning robust robot skills from limited data remains a key challenge, despite the abundance of videos featuring diverse embodiments and environments. This paper introduces ‘TraceGen: World Modeling in 3D Trace Space Enables Learning from Cross-Embodiment Videos’, a novel approach that unifies heterogeneous video data by representing motion in a compact, symbolic 3D “trace space.” By predicting future scene-level trajectories-rather than raw pixels-TraceGen learns transferable 3D motion priors from both human and robot demonstrations, achieving high success rates with minimal target robot data. Could this abstraction unlock truly generalizable robot learning, bridging the gap between human instruction and robotic execution across varied platforms and scenarios?
The Illusion of Pixels: Why We Chase Ghosts in Video
Conventional video analysis typically relies on processing data at the pixel level, a method that quickly becomes computationally prohibitive. Each frame is treated as a vast array of individual pixels, resulting in high-dimensional data sets that demand significant processing power and memory. This approach struggles with scalability, particularly when dealing with high-resolution videos or real-time applications. The sheer volume of pixel data also obscures the essential information related to movement and action, making it difficult to efficiently identify and track objects or interpret complex scenes. Consequently, traditional methods often require substantial pre-processing and simplification, potentially losing crucial details in the process, or demand specialized hardware for practical implementation.
Trace-Space offers a fundamentally different approach to video analysis by shifting focus from individual pixels to the underlying motion itself. Instead of processing the complete visual data, this representation distills movement into concise, three-dimensional trajectories that capture the essential path of objects or points of interest. By discarding superfluous visual details – texture, color, and static background elements – Trace-Space creates a dramatically simplified dataset. This reduction in dimensionality not only accelerates computational processes but also enhances the robustness of motion analysis algorithms, allowing them to generalize more effectively across varying conditions and focus on the core dynamics of a scene. The resulting trajectories provide a powerful and efficient means of representing and understanding movement, opening new avenues for applications in areas like action recognition, robotic vision, and behavioral analysis.
Building a World Model From Motion’s Echo
TraceGen represents a novel approach to world modeling by directly predicting future motion within a dedicated Trace-Space. Unlike traditional methods that forecast in pixel or 3D coordinate spaces, TraceGen operates on a normalized representation of movement, facilitating more efficient and accurate forecasting. This direct prediction within Trace-Space allows the model to bypass the computational demands of translating between abstract representations and visual data, resulting in reduced latency and improved performance in predicting dynamic scenes. The model’s architecture is specifically designed to leverage the properties of this Trace-Space for superior motion prediction capabilities.
TraceGen utilizes CogVideoX as its decoding mechanism to generate 3D trajectories from learned latent representations. CogVideoX, a pre-trained video diffusion model, is adapted to interpret the compressed latent space output by TraceGen’s encoding network. This allows the model to translate abstract, high-level understandings of motion into concrete 3D positional data over time, effectively reconstructing predicted future movements. The decoder’s function is to map these latent vectors to sequences of 3D coordinates, defining the predicted trajectory of objects within the modeled environment. This process enables TraceGen to produce visually interpretable and physically plausible motion forecasts.
TraceForge is a core component of the TraceGen system, functioning as a data engine responsible for preparing heterogeneous video data for consistent model training. It normalizes diverse video inputs and aligns them into a unified “Trace-Space” representation, which facilitates the prediction of 3D trajectories. This normalization is achieved through training on a large-scale dataset comprising 1.8 million observation-trace-language triplets sourced from 123,000 videos. The resulting dataset provides the necessary data for TraceGen to learn the relationships between visual observations, corresponding 3D traces of motion, and associated descriptive language.
The Garden of Possible Paths: Stochastic Trajectory Generation
TraceGen utilizes a Stochastic Interpolant framework for trajectory generation by introducing variations through multiple noise initializations. This approach involves creating a distribution of possible trajectories rather than a single deterministic path. By sampling different noise vectors at the outset of the interpolation process, the system can produce a diverse set of trajectories from a single pair of start and end states. This stochasticity is key to exploring the trajectory space and improving robustness, as the model isn’t limited to a single, potentially brittle, solution. The framework allows for the creation of multiple plausible trajectories given the same conditions, enabling more adaptable and versatile robotic behaviors.
The trajectory generation framework utilizes Linear Interpolation to create intermediate states between keyframes, providing a discrete approximation of continuous motion. This interpolated path is then refined through Ordinary Differential Equation (ODE) integration, which solves for the continuous trajectory that best satisfies the defined initial and terminal conditions. By combining these methods, the framework efficiently samples trajectory space, enabling rapid generation of diverse and plausible paths without requiring extensive computational resources. The process involves defining a continuous dynamical system and using the ODE solver to propagate the state of the system forward in time, effectively smoothing the linearly interpolated path and producing a more natural and realistic trajectory.
Prismatic-VLM facilitates conditional trajectory generation by integrating visual and linguistic inputs. This fusion is achieved through the concurrent processing of visual features extracted via DINOv3 and SigLIP, and linguistic information encoded by a frozen T5 encoder. The resulting combined representation conditions the trajectory generation process, allowing the model to produce trajectories responsive to both observed visual states and given language instructions. This architecture enables the generation of diverse and contextually relevant trajectories based on multi-modal inputs.
Prismatic-VLM leverages DINOv3 and SigLIP for robust visual feature extraction, enabling effective perception of the environment and objects involved in manipulation tasks. Linguistic information is processed using a frozen T5 Encoder, preserving pre-trained language understanding capabilities without gradient updates during training. This architecture achieves an 80% success rate in real-world manipulation tasks after learning from only 5 demonstrations, significantly outperforming video-based approaches with a 50x speed increase in processing time. The combination of these components allows for efficient and accurate conditional trajectory generation based on both visual and linguistic inputs.
Beyond Mimicry: The Promise of Embodied Intelligence
TraceGen establishes a novel approach to robotic control by generating a shared representation of motion divorced from the specifics of any particular physical body. This decoupling allows a robot to learn and replicate movements demonstrated by entities with vastly different morphologies – a human, a quadruped, or even a simulated character – without requiring extensive re-training for each new form. The system achieves this through a latent space that encodes the essential dynamics of motion, effectively abstracting away details like limb length or joint configuration. Consequently, a single TraceGen model can generalize across a diverse range of embodiments, enabling robots to learn from and imitate a wider variety of demonstrations and potentially paving the way for more adaptable and versatile robotic systems.
To cultivate a robust understanding of movement, the model underwent extensive training utilizing large-scale datasets such as the Agibot Dataset and the SSV2 Dataset. These datasets, encompassing a diverse range of robotic and human motions, enabled the system to discern underlying principles governing movement rather than memorizing specific trajectories. This approach fostered the development of generalizable motion patterns, allowing the model to adapt to novel scenarios and unseen physical forms. By exposing the system to a wide variety of actions – from simple reaching to complex manipulation – the training process facilitated the extraction of fundamental kinematic and dynamic relationships, ultimately enhancing its capacity for versatile and adaptable motion control.
TraceGen represents a significant advancement in robotic control by fundamentally separating the how of motion from the look of the agent performing it. Traditional world models often struggle with transferring learned skills between different robotic bodies or from human demonstrations due to their reliance on specific visual features. This model, however, learns a generalized representation of motion trajectories, allowing it to effectively translate human actions – even those demonstrated with varying styles and without precise calibration – onto diverse robotic platforms. This decoupling has been experimentally validated, with the system achieving a 67.5% success rate in replicating actions from just five uncalibrated human demonstration videos, demonstrating its potential for intuitive robot programming and versatile imitation learning capabilities.

The pursuit of generalized robotic manipulation, as demonstrated by TraceGen, often feels like chasing a phantom architecture. The system’s ability to learn from cross-embodiment videos and represent motion in a 3D trace space is, at its core, a testament to the inherent limitations of predictive design. As John McCarthy observed, “Programs must be written for humans to understand, not just for computers to execute.” The elegance of TraceGen lies not in a pre-defined structure, but in its capacity to grow a world model from diverse data. Scalability, in this context, isn’t about handling more complexity – it’s simply a word used to justify it. The true challenge isn’t building a perfect architecture, but accepting that every system will eventually succumb to the pressures of unforeseen circumstances, demanding constant adaptation and refinement.
What Lies Ahead?
TraceGen offers a compelling vision of world modeling, but the garden always expands faster than the gardener intends. The compression of motion into a 3D trace space is not merely a technical achievement; it’s an acknowledgment that perfect fidelity is an illusion. Every reduction in dimensionality is a carefully chosen forgetting, a prophecy of maneuvers the system will struggle to recover from. The true test will not be replicating known motions, but graceful degradation when faced with the inevitable novelty of the physical world.
The promise of cross-embodiment learning, while enticing, highlights a deeper challenge. A system doesn’t learn to manipulate; it learns to interpret. Transferring skills between robots is not a matter of sharing parameters, but of building shared metaphors for action. The ability to generalize from human demonstration suggests not intelligence, but a clever form of mimicry. The interesting failures will be those where the system attempts to apply a learned ‘trace’ to a situation where the underlying physics simply doesn’t align.
Future work will inevitably focus on scaling these models – more data, larger trace spaces, more complex scenarios. However, the real leverage may lie in accepting the inherent limitations of prediction. Resilience lies not in isolation, but in forgiveness between components – in building systems that can detect and recover from their own inevitable misinterpretations. A world model is not a mirror, but a sculptor’s approximation, forever incomplete, forever in progress.
Original article: https://arxiv.org/pdf/2511.21690.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Chuck Mangione, Grammy-winning jazz superstar and composer, dies at 84
- Clash Royale Furnace Evolution best decks guide
- December 18 Will Be A Devastating Day For Stephen Amell Arrow Fans
- Now That The Bear Season 4 Is Out, I’m Flashing Back To Sitcom Icons David Alan Grier And Wendi McLendon-Covey Debating Whether It’s Really A Comedy
- Clash Royale Witch Evolution best decks guide
- All Soulframe Founder tiers and rewards
- Riot Games announces End of Year Charity Voting campaign
- Deneme Bonusu Veren Siteler – En Gvenilir Bahis Siteleri 2025.4338
- BLEACH: Soul Resonance Character Tier List
2025-11-29 01:09