Author: Denis Avetisyan
Researchers have developed an agent-based system to rigorously test and refine our understanding of what’s happening inside large language models.
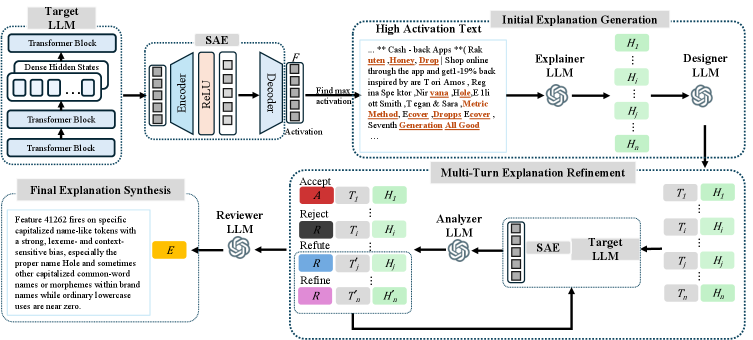
This paper introduces SAGE, an agentic framework for interpreting sparse autoencoder features and improving the interpretability of large language models through empirical validation.
Despite recent advances in large language models, understanding how they represent knowledge remains a significant challenge. This work introduces SAGE: An Agentic Explainer Framework for Interpreting SAE Features in Language Models, a novel approach that moves beyond passive feature analysis to actively test interpretations using an agent-based methodology. By systematically formulating, experimenting with, and refining explanations grounded in empirical activation feedback, SAGE demonstrably improves the accuracy and predictive power of feature understanding in sparse autoencoders. Could this active, iterative approach unlock a new era of reliable and interpretable AI systems?
The Opaque Oracle: Decoding the Language Model’s Inner Life
Contemporary language models demonstrate remarkable capabilities in processing and generating human language, yet these achievements often come at the cost of interpretability. These models frequently operate as “black boxes,” where the complex interplay of internal components-specifically, what are known as SAE Features-remains largely obscured from view. These features, developed through layers of artificial neural networks, capture nuanced patterns in the input text, but their precise meaning and contribution to the model’s output are difficult to discern. While a model might accurately translate a sentence or answer a question, the rationale behind its decision-making process remains hidden within these opaque internal representations, presenting a significant challenge for those seeking to understand, control, and ultimately trust these powerful systems.
The utility of sophisticated language models hinges not only on their performance, but also on the ability to understand why they arrive at specific conclusions – a challenge significantly complicated by the nature of SAE Features. These internal representations, while enabling impressive capabilities, remain largely uninterpretable, creating a barrier to effective model debugging and control. Without insight into which textual patterns trigger particular feature activations, identifying and rectifying errors becomes a process of trial and error, rather than informed intervention. Crucially, this lack of transparency erodes trust; users are understandably hesitant to rely on systems whose reasoning remains obscured, particularly in high-stakes applications where accountability is paramount. Consequently, unlocking the interpretability of these features is not merely a technical hurdle, but a fundamental requirement for the responsible deployment of advanced language technologies.
Current techniques for analyzing the internal workings of large language models often fall short when attempting to link specific textual elements to individual feature activations. While researchers can observe that a feature is triggered by a given input, determining which precise words or phrases are responsible remains a significant challenge. This isn’t simply a matter of identifying keywords; complex interactions and subtle nuances within the text can drive feature responses in non-obvious ways. Consequently, understanding the model’s reasoning process-and ultimately, building trust in its outputs-is hampered by this opacity, as the connection between input and internal representation remains largely obscured. This limitation necessitates the development of novel analytical tools capable of dissecting these complex relationships and revealing the specific textual patterns that govern model behavior.
SAGE: An Ecosystem for Explanation
SAGE is an agent-based framework designed to provide explanations for the behavior of Safety-critical AI Elements (SAE) features. The system utilizes multiple Large Language Models (LLMs) operating as autonomous agents to iteratively develop and assess potential explanations. This approach moves beyond traditional static analysis techniques by enabling dynamic experimentation; agents formulate hypotheses regarding SAE feature activation, then actively test these hypotheses through controlled input variations. The framework’s architecture allows for continuous refinement of explanations based on empirical evidence gathered from these tests, ultimately aiming to provide robust and verifiable insights into the decision-making processes of SAE features.
The SAGE framework’s central component is the ‘Explainer Agent’, responsible for initial hypothesis generation. This agent operates on ‘Exemplar Data’, which consists of text segments identified as having high activation values – specifically, those segments exhibiting the strongest response from the underlying models during the analysis of System-Aware Explanations (SAE) features. These high-activation segments are not chosen arbitrarily; they represent portions of the input text that most strongly influenced the model’s decision-making process, and therefore serve as the foundation for constructing plausible explanations regarding feature behavior. The Explainer Agent leverages this Exemplar Data to formulate potential hypotheses about why a particular SAE feature produced a given output.
Unlike static analysis methods which rely on pre-existing data and logical deduction, SAGE actively tests proposed explanations through experimentation. The framework modifies text inputs and observes the resulting changes in the System Under Examination (SUE). These modifications, or ‘probes’, are designed to specifically challenge the hypothesized relationship between input features and SUE behavior. If altering a particular text segment consistently alters the SUE’s output as predicted by the explanation, the hypothesis is strengthened; conversely, inconsistent results indicate the need for refinement or rejection of the proposed explanation. This iterative process of experimentation and validation allows SAGE to move beyond correlation and towards establishing a more robust understanding of causal relationships within the system.
Iterative Refinement: Sculpting Understanding Through Experimentation
The SAGE system utilizes a ‘Designer Agent’ to generate specific ‘Test Text’ inputs intended to evaluate the behavior of identified features within the model. This agent does not produce random inputs; instead, it constructs text tailored to directly challenge or support the hypotheses proposed by the ‘Explainer Agent’ regarding feature importance. The design of this ‘Test Text’ is crucial; it aims to elicit measurable responses from the model – specifically, feature activations – that can be analyzed to either confirm the Explainer Agent’s understanding of how a feature influences the model’s output, or to identify areas where the explanation requires revision. The targeted nature of these inputs ensures efficient probing of feature behavior and facilitates a focused evaluation of the generated explanations.
The Analyzer Agent functions by quantifying the internal state of the model under test. Specifically, it measures ‘Activation Feedback’, which consists of the values of feature activations – the degree to which individual features within the model are triggered by a given input. These activation values represent the model’s internal processing and serve as objective data for evaluating the Explainer Agent’s hypotheses. The Analyzer Agent does not interpret the meaning of these activations, but rather provides a raw, quantifiable signal that is subsequently assessed by the Reviewer Agent to determine the validity of the explanation.
The Reviewer Agent performs iterative refinement of explanations by evaluating the Activation Feedback received from the Analyzer Agent. This evaluation drives a process of Hypothesis Refinement, where the initial explanation is updated based on discrepancies between predicted and observed feature activations. This isn’t a single-step process; the system employs a Multi-Turn Explanation Refinement approach, meaning the Designer Agent can generate new Test Text based on the Reviewer Agent’s feedback, prompting further analysis and iterative improvement of the explanation until a satisfactory level of accuracy and completeness is achieved. Each turn involves assessing the current explanation, identifying areas for improvement, and guiding the generation of new tests to specifically address those weaknesses.
From Prediction to Genesis: Synthesizing a Causal Model
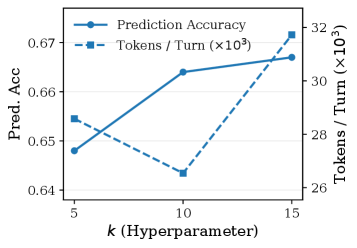
SAGE employs a process of iterative refinement to arrive at explanations of neural network behavior that surpass simple prediction. While many approaches focus solely on identifying what a neuron represents, SAGE strives to understand how it functions, moving beyond predictive accuracy-reaching 0.65-0.83 compared to Neuronpedia’s 0.52-0.70-to demonstrate genuine generative accuracy. This means the framework doesn’t just anticipate feature activations, but can actually cause them, effectively modeling the underlying computational process. The ability to causally generate activations represents a significant step toward interpretability, offering a deeper understanding of the model’s reasoning and enabling more robust control over its outputs.
The culmination of SAGE’s analytical process lies in its ‘Final Explanation Synthesis,’ a robust integration of previously accepted hypotheses to comprehensively interpret the behavior of each Stimulus-Attribute Embedding (SAE) feature. This synthesis doesn’t simply predict what a feature activates, but actively generates those activations, demonstrating a significant leap in understanding and control. Quantitative results reveal substantial gains in generative accuracy, ranging from 29% to an impressive 458% improvement over the established Neuronpedia baseline. This indicates that the synthesized explanations aren’t merely descriptive; they offer a causal model of feature behavior, fostering a deeper, more reliable grasp of the language model’s internal workings and paving the way for enhanced transparency and trustworthiness.
The developed framework offers a crucial step toward realizing language models that are not simply powerful, but also understandable and reliable. By moving beyond correlative analysis to establish causal links between internal features and model behavior, researchers gain the ability to interpret why a model produces a given output. This interpretability directly translates to increased controllability, allowing for targeted interventions to refine model responses and mitigate biases. Ultimately, this pathway fosters trust in these complex systems, paving the way for their responsible deployment in critical applications where transparency and dependability are paramount – from healthcare and finance to legal reasoning and scientific discovery.
The pursuit of definitive explanation, as demonstrated by SAGE’s agentic approach to interpreting sparse autoencoder features, mirrors a fundamental tension. One might observe that a system striving for perfect interpretability is, in effect, predicting its own eventual inadequacy. This echoes Blaise Pascal’s sentiment: “The eloquence of youth is that it knows nothing.” SAGE doesn’t build understanding; it cultivates it through iterative testing, acknowledging the polysemantic nature of LLM features. The framework anticipates failure, not as a flaw, but as an intrinsic component of growth, refining explanations through constant challenge. A system that never breaks is, indeed, a system that has ceased to learn.
What’s Next?
The pursuit of interpretability, as demonstrated by frameworks like SAGE, is not a quest for illumination-it is architecture, how one postpones chaos. To actively test explanations, to subject them to agentic refinement, acknowledges a fundamental truth: there are no best practices, only survivors. SAGE does not find meaning in the latent space; it cultivates a selective pressure, rewarding explanations that withstand scrutiny. This is not explanation, but evolution.
The focus on sparse autoencoders is, of course, a temporary reprieve. The substrate will shift, the dimensionality will increase, and the polysemantic features will become ever more opaque. The core problem remains: any attempt to dissect a complex system inevitably creates a reduction that misses the emergent properties. SAGE offers a method for managing this reduction, not eliminating it.
Future work must confront the inevitable. Order is just cache between two outages. The next generation of interpretability frameworks will not seek to explain what is, but to predict what will fail. The truly useful feature is not the one understood, but the one whose absence precipitates catastrophe. The field must move beyond explanation and embrace pre-failure analysis – a science of controlled demolition, rather than hopeful reconstruction.
Original article: https://arxiv.org/pdf/2511.20820.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Best Arena 9 Decks in Clast Royale
- Clash Royale Furnace Evolution best decks guide
- Best Hero Card Decks in Clash Royale
- FC Mobile 26: EA opens voting for its official Team of the Year (TOTY)
2025-11-28 06:35