Author: Denis Avetisyan
Researchers have developed a new technique to pinpoint the neurons within large language models responsible for specific skills and reasoning processes.
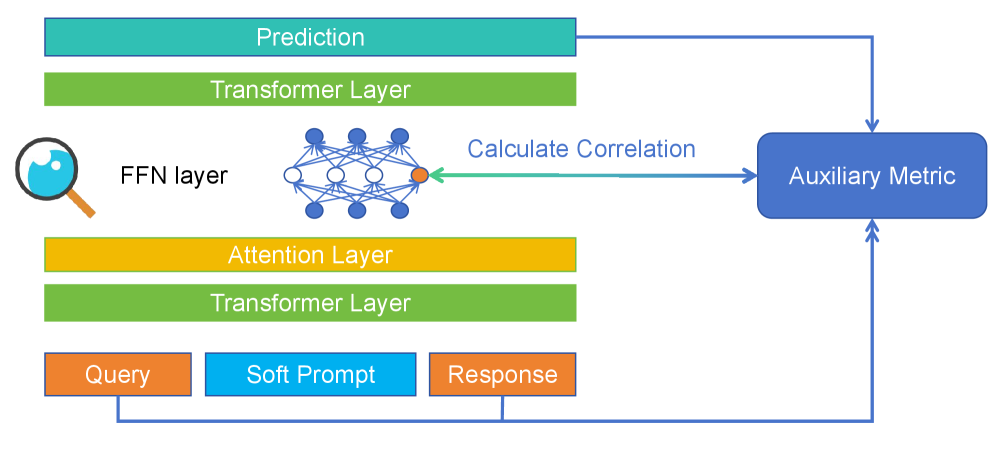
A novel method using auxiliary metrics improves the interpretability of skill neurons in large language models by analyzing activation correlations.
Despite the remarkable capabilities of large language models, understanding how they achieve these feats remains a significant challenge. In “Auxiliary Metrics Help Decoding Skill Neurons in the Wild,” we introduce a method for identifying neurons responsible for specific skills by correlating their activations with readily available auxiliary metrics-like prediction confidence or external labels. This approach allows us to pinpoint task-relevant neurons without laborious manual analysis, revealing both known abilities and previously hidden shortcuts within the network. Could this technique unlock a more comprehensive understanding of the inner workings of these powerful models and guide the development of more interpretable AI?
The Fragility of Scale: Beyond Correlation, Towards Understanding
Despite their remarkable capacity to generate human-quality text, large language models frequently demonstrate a fragility in reasoning, often succeeding through statistical correlations rather than genuine understanding. This reliance on superficial patterns means these models can be easily misled by subtle changes in phrasing or context, exhibiting what appears to be a lack of robust cognitive ability. While capable of mimicking logical structures, they often struggle with tasks requiring abstract thought, common sense, or the application of knowledge to novel situations. This brittleness highlights a fundamental difference between statistical language modeling and true reasoning, prompting researchers to explore methods for building AI systems that possess a deeper, more reliable understanding of the world.
The pursuit of robust artificial intelligence may hinge on identifying dedicated “skill neurons” within large language models – specific neural units responsible for discrete linguistic abilities like negation, coreference resolution, or even recognizing logical fallacies. This concept proposes that, unlike current models which distribute processing across vast networks, isolating these neurons could yield AI systems that aren’t simply mimicking patterns but genuinely understanding language. Such interpretable components would allow researchers to pinpoint the source of errors, improve reasoning through targeted refinement, and ultimately build AI less prone to “brittle” failures when confronted with novel or ambiguous inputs. This modular approach promises a shift from opaque, black-box systems to more transparent and controllable AI, potentially unlocking a new era of reliable and adaptable machine intelligence.
The pursuit of identifying dedicated ‘skill neurons’ within large language models faces a significant hurdle: the limitations of traditional supervised learning. Relying on manually labeled datasets to pinpoint these neurons – those demonstrably responsible for specific linguistic abilities – proves both costly and potentially biased, as labeling can inadvertently reinforce existing patterns instead of revealing genuinely novel computational mechanisms. Consequently, researchers are developing innovative approaches to signal detection, moving beyond explicit labeling to leverage the internal dynamics of these models themselves. These methods include analyzing neuron activation patterns during various tasks, probing for consistent responses to specific linguistic features, and employing algorithmic techniques to isolate neurons that exhibit strong, interpretable signals – all with the aim of uncovering the building blocks of reasoning without the constraints of human annotation. This shift promises a more scalable and objective path towards understanding, and ultimately improving, the reasoning capabilities of artificial intelligence.
Quantifying Skill: Auxiliary Metrics as Signposts
Auxiliary metrics are employed as quantifiable indicators of linguistic skill to pinpoint neurons exhibiting consistent activation during the execution of a defined task. These metrics move beyond simple accuracy scores by providing a granular assessment of a model’s capabilities, allowing for the isolation of specific neuron responses. By correlating neuron activations with the values of these auxiliary metrics, researchers can identify neurons demonstrably linked to particular linguistic processes, regardless of the presence of explicit task labels. This approach enables a more targeted investigation of neural network function and facilitates the understanding of how models internally represent and process language.
The use of arithmetic tasks as a method for identifying neurons associated with numerical reasoning offers a significant advantage by eliminating the necessity for manually assigned labels. These tasks provide a standardized and controlled environment, allowing for the direct correlation between neuron activation patterns and performance on quantifiable metrics. Specifically, our research demonstrated a strong positive correlation – a Pearson correlation coefficient of $0.93$ – between neuron activations and auxiliary metrics derived from the successful completion of arithmetic problems. This high degree of correlation indicates that measurable activity within specific neurons is consistently associated with the model’s ability to perform numerical reasoning, enabling targeted identification and analysis.
The Pearson correlation coefficient, denoted as $r$, is employed to statistically quantify the linear relationship between neuron activations and auxiliary metrics. Values range from -1 to +1, with higher absolute values indicating a stronger correlation. In our methodology, a top-K correlation threshold of 0.43 was implemented during the identification of sparse neurons performing the HANS (Holistically-Assessed Neurons for Solving) task. This threshold defines the minimum $r$ value required for a neuron to be considered correlated with a specific auxiliary metric, enabling the isolation of neurons demonstrably linked to targeted linguistic skills. The selection of 0.43 represents a balance between identifying a sufficient number of neurons and maintaining statistical rigor in the correlation analysis.
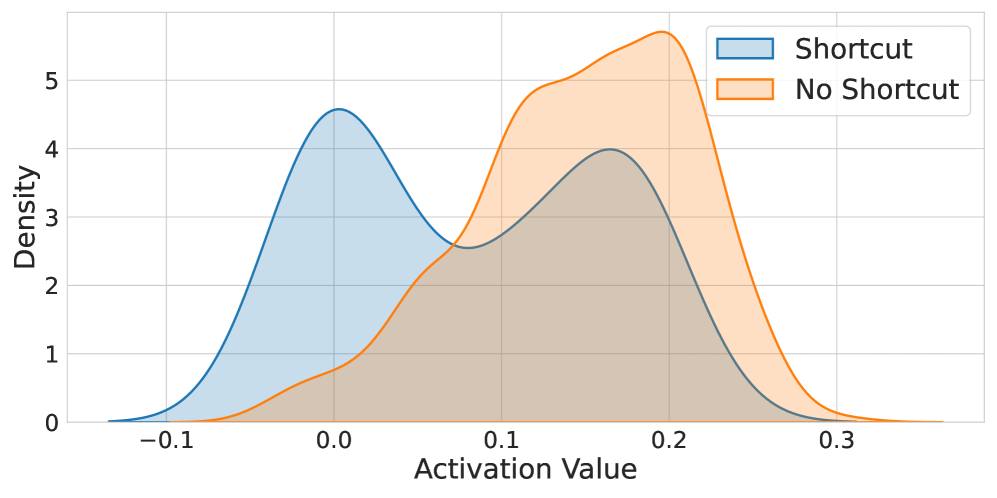
Directing Intelligence: Soft Prompt Tuning and Skill Neuron Activation
Soft prompt tuning represents a parameter-efficient transfer learning technique for Large Language Models (LLMs). Traditional fine-tuning adjusts all or most of the LLM’s parameters to a new task, which is computationally expensive and requires significant storage. In contrast, soft prompt tuning introduces a small number of trainable vectors – the ‘soft prompt’ – prepended to the input sequence. These vectors are optimized through gradient descent while the original LLM parameters remain fixed. This approach drastically reduces the number of trainable parameters – often to less than 1% of the total model size – enabling faster training, lower memory requirements, and easier deployment without sacrificing performance on the target task. The technique allows adaptation to new tasks with a fraction of the computational cost associated with full fine-tuning.
Soft prompt tuning facilitates targeted task performance by influencing the activation of specific Skill Neurons within a Large Language Model. This is achieved by optimizing continuous prompt vectors that, when prepended to the input, subtly alter the model’s internal representations. By carefully shaping the input context through these learned prompts, the model’s attention is directed towards the features most relevant to the desired skill, effectively increasing the probability of activating the corresponding neurons and improving output quality on targeted tasks without modifying the core model parameters.
The causal attention mechanism within soft prompt tuning operates by weighting the importance of different parts of the input sequence when generating a response. This is achieved through attention weights calculated based on the relationships between tokens, allowing the model to prioritize relevant instructions and contextual information. Specifically, the mechanism ensures that the model attends to preceding tokens in the input sequence – adhering to a causal structure – to predict the subsequent token. By strategically shaping the soft prompt, these attention weights can be directed toward Skill Neurons associated with desired capabilities, effectively modulating the model’s internal representations and enhancing task performance without modifying the core model parameters. The resulting attention maps demonstrate a focused allocation of attention to the prompt tokens, indicating successful activation of targeted skills.
The Foundations: Model and Optimization Parameters
Qwen 1.5, utilized as the base model for all experiments, is a large language model developed by Alibaba Cloud. It distinguishes itself through its strong performance on a variety of benchmarks and its support for a substantial context window of up to $200K$ tokens, enabling processing of lengthy input sequences. The model is instruction-tuned, meaning it has been specifically trained to follow natural language instructions, improving its usability for diverse tasks without requiring extensive task-specific fine-tuning. Qwen 1.5 is available in multiple parameter sizes, ranging from 2.7 billion to 72 billion parameters, allowing for trade-offs between computational cost and model capacity. The model employs a group query attention mechanism for increased inference throughput and reduced memory usage.
The Qwen 1.5 model utilizes a Transformer architecture, a neural network design relying on self-attention mechanisms to weigh the importance of different parts of the input data. Central to this architecture is the Feed-Forward Layer, a fully connected network applied to each position independently, responsible for processing the information extracted by the attention mechanism. This layer employs the SiLU (Sigmoid Linear Unit) activation function, defined as $SiLU(x) = x * sigmoid(x)$, which introduces non-linearity and has been shown to improve performance in language modeling tasks. The combination of the Transformer structure, the Feed-Forward Layer, and the SiLU activation function facilitates the identification and activation of specific ‘skill neurons’ within the model, enabling the representation and execution of learned skills.
The AdamW optimizer was utilized for training the soft prompts, leveraging its benefits for models with a large number of parameters. AdamW incorporates a weight decay penalty directly into the gradient update rule, effectively regularizing the model and preventing overfitting. This differs from standard Adam, which applies L2 regularization separately. The optimization process involved calculating gradients via backpropagation, applying the AdamW update rule-incorporating first and second moment estimates of the gradients with bias correction-and updating the soft prompt parameters. Key hyperparameters included a learning rate of $1e-3$, $\beta_1 = 0.9$, $\beta_2 = 0.999$, and a weight decay of $0.01$. These settings were chosen based on empirical performance during validation runs.
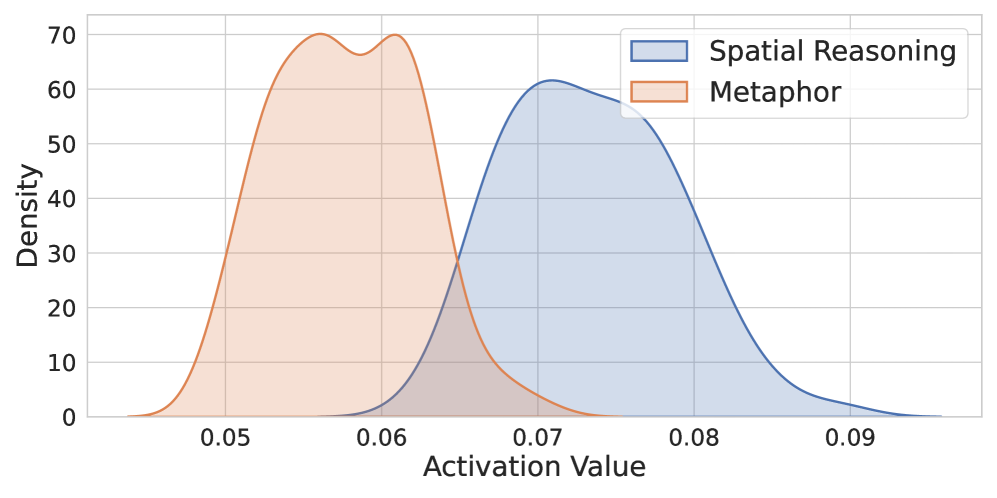
Towards Modular Intelligence: Implications and Future Directions
Recent investigations have revealed that Large Language Models harbor internally specialized “Skill Neurons” – individual neurons or small groups that activate consistently during the execution of specific tasks, such as translation or code generation. This discovery establishes the feasibility of dissecting these models beyond their monolithic structure, offering a pathway towards more modular AI systems. By identifying and leveraging these Skill Neurons, researchers can potentially create AI assistants that are not only more efficient – focusing computational resources only on relevant skills – but also more adaptable and easier to refine. This approach moves beyond simply scaling model size, suggesting a future where AI capabilities are built from interconnected, specialized components, much like the human brain, enabling targeted improvements and the creation of truly versatile artificial intelligence.
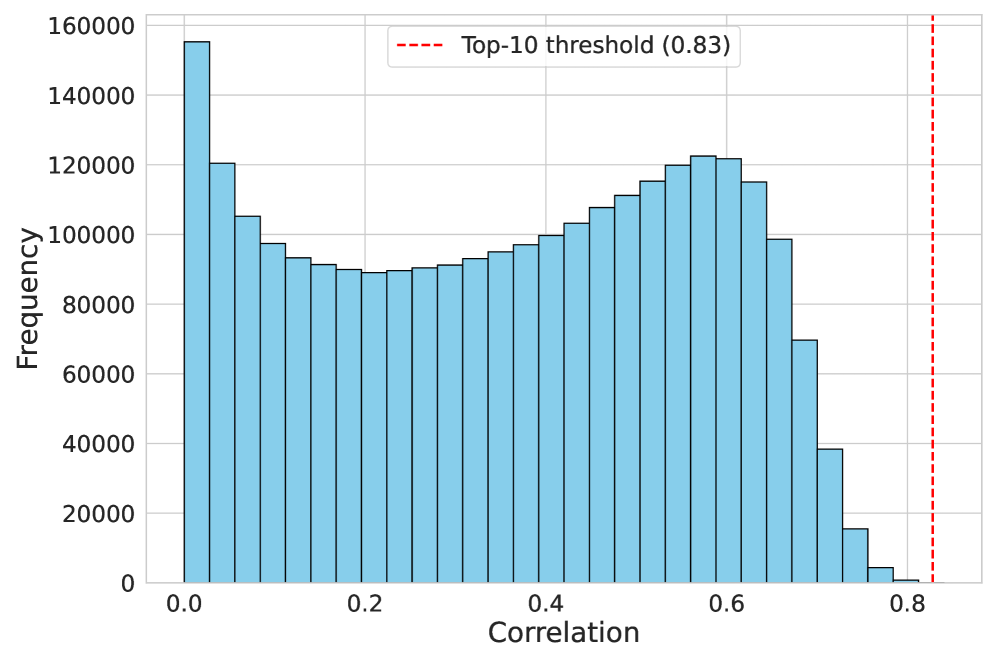
The development of the Skill-Mix framework represents a significant step toward building artificial intelligence assistants capable of handling diverse and complex tasks with greater reliability. This approach directs language models to generate outputs that specifically demand the application of identified skills, effectively testing and reinforcing their specialization. Empirical evaluation of the SkillMix task revealed a strong correlation – reaching a top-10 threshold of 0.83 – between the intended skill activation and the model’s generated output, indicating the framework’s efficacy in guiding skill utilization. This ability to orchestrate skill application promises more robust performance across varied prompts and scenarios, moving beyond generalized responses towards nuanced, skill-based problem-solving in AI assistants.
Investigations are now shifting towards understanding how Skill Neurons interact during complex tasks, moving beyond individual skill identification. Researchers aim to map these interactions, revealing potential synergies and dependencies between different learned abilities within large language models. A key challenge lies in developing mechanisms for dynamic activation – systems that can intelligently select and engage the appropriate Skill Neurons based on the nuances of a given request. This could involve reinforcement learning approaches, where the model learns to optimize skill combinations for peak performance, or the creation of gating networks that regulate neuron activation based on input characteristics. Successfully implementing such dynamic control promises a new generation of AI systems capable of exhibiting greater flexibility, efficiency, and specialization, adapting their internal processes to meet the demands of an ever-changing world.
The pursuit of understanding within large language models necessitates a ruthless pruning of complexity. This work, focused on identifying skill neurons through auxiliary metrics, exemplifies that principle. It isn’t about discovering every activated node, but discerning those fundamentally linked to specific heuristics-a distillation of function. As Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This sentiment aligns with the methodology; researchers bypass exhaustive analysis, instead focusing on measurable correlations to swiftly pinpoint skill-related neurons. The core strength lies in what remains after this focused examination – a clearer understanding of the model’s internal mechanisms.
Further Refinements
The presented methodology, while demonstrably effective at surfacing correlates of skill within the opaque architecture of large language models, does not resolve the fundamental question of understanding. Correlation, even robust correlation, remains a descriptive, not an explanatory, exercise. Future iterations must move beyond identifying that a neuron participates in a skill, to elucidating how its activation contributes to the emergent behavior. The current reliance on auxiliary metrics, while pragmatic, introduces a dependence on externally defined proxies; the true skill, one suspects, is often encoded in a more nuanced, internal representation.
A significant limitation lies in the scalability of this approach. Network dissection, even with automated metrics, is computationally expensive. The models continue to expand in parameter count, creating a diminishing return on interpretability efforts. Research should prioritize methods that reduce the search space, perhaps through architectural constraints or the development of intrinsically interpretable model components. The pursuit of ever-larger models, without commensurate advances in interpretability, risks entrenching a situation where function remains divorced from comprehension.
Ultimately, the value of identifying skill neurons is not intrinsic, but instrumental. Their true utility will be realized when this knowledge can be leveraged to improve model control, enhance robustness, or facilitate transfer learning. The focus must shift from simply finding these neurons, to engineering systems where their function is predictable and reliable. Emotion, it is observed, is merely a side effect of structure; the structure itself deserves greater scrutiny.
Original article: https://arxiv.org/pdf/2511.21610.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Chuck Mangione, Grammy-winning jazz superstar and composer, dies at 84
- December 18 Will Be A Devastating Day For Stephen Amell Arrow Fans
- Clash Royale Furnace Evolution best decks guide
- Now That The Bear Season 4 Is Out, I’m Flashing Back To Sitcom Icons David Alan Grier And Wendi McLendon-Covey Debating Whether It’s Really A Comedy
- Clash Royale Witch Evolution best decks guide
- Riot Games announces End of Year Charity Voting campaign
- Deneme Bonusu Veren Siteler – En Gvenilir Bahis Siteleri 2025.4338
- All Soulframe Founder tiers and rewards
- BLEACH: Soul Resonance Character Tier List
2025-11-28 01:32